Every team runs evals. Almost none have an evaluation practice. The difference is the gap between a one-off notebook and a system that continuously assesses, alerts, and acts on what it finds. The teams that close that gap don’t do it in one leap — they grow into it. Here’s how we think about that progression.
The Evaluation Harness
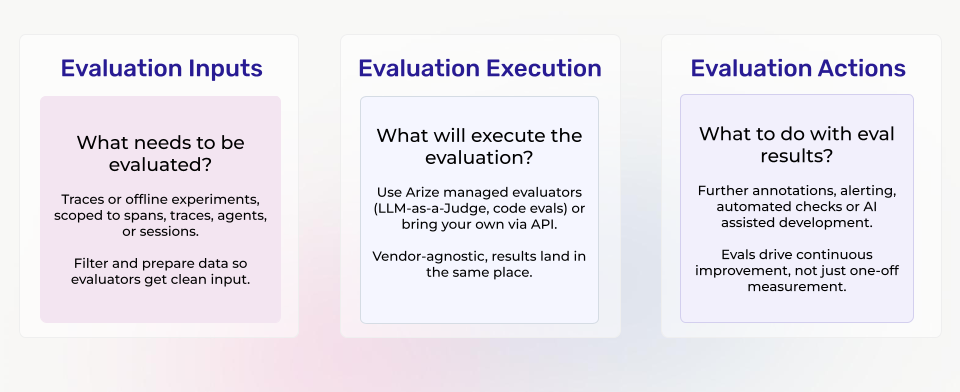
Everything in this post is powered by a single architectural concept we call the evaluation harness — a three-stage pipeline that stays consistent no matter how sophisticated your evaluation practice becomes.
Evaluation Inputs define what gets evaluated. Traces or offline experiments, scoped to spans, traces, agent trajectories, or sessions, filtered and prepared so evaluators receive clean, targeted data.
Evaluation Execution determines how scoring happens. LLM-as-a-Judge, deterministic code checks, embedding similarity, custom scoring functions, or any combination — executed through the platform, through an API endpoint, or through external open-source packages. Vendor-agnostic, results land in the same place.
Evaluation Actions close the loop. Annotation queues for human review, monitors and alerts routed to operational tooling, CI/CD gates for regression validation, and AI-assisted experiment workflows that turn evaluation results into system improvements.
The harness architecture is the backbone of everything that follows. We’ll publish a full technical deep-dive on it soon. For now, here’s what you can build with it.
AI Ops stages
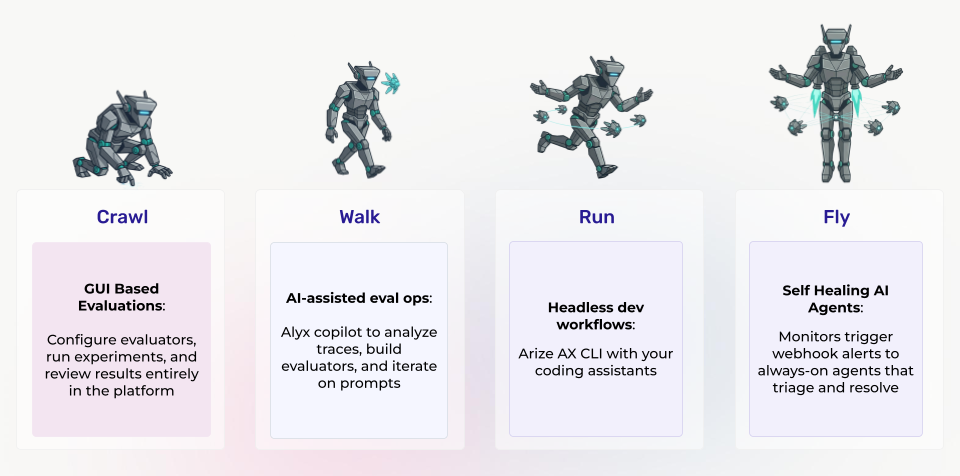

Crawl: GUI-First Evaluation
The starting point. Your app is instrumented with OpenTelemetry, traces are flowing into the platform, and now you need to actually score what you’re seeing.
In the Crawl stage, you do everything through the platform UI. Scope your evaluation to the right unit of work — a single LLM call, a full agent trace, an entire user session. Pick an evaluator template (hallucination detection, relevance scoring, QA correctness, or build your own). Configure the judge model. Run it. Review the results. No code required beyond the initial instrumentation.
This isn’t a simplified mode with training wheels. It’s the same execution engine, the same data model, the same evaluation infrastructure that powers every other stage. The difference is the interface, not the capability. And that distinction matters, because it means domain experts and product managers can participate in evaluation directly — not just the engineer who wired up the SDK. Evaluation stops being one person’s job and becomes a team practice.
If you’re already using an open-source tool like Phoenix for local evaluation and tracing, that’s a natural on-ramp. The platform builds on the same OpenTelemetry and OpenInference primitives, so nothing you’ve built gets thrown away — your instrumentation, your trace schemas, your evaluator logic all carry forward.
 Walk: AI-Assisted Eval Ops
Walk: AI-Assisted Eval Ops
The Crawl stage gets you running evals. The Walk stage changes who can run them and how fast.
Alyx is an AI copilot embedded directly in the platform. Instead of manually configuring every evaluator, task, and experiment, you direct Alyx conversationally. Ask it to analyze your traces and identify failure modes. Have it generate synthetic test data for edge cases you haven’t covered. Let it draft an evaluator template, run the experiment, interpret the results, and iterate on the prompt until a target metric threshold is met.
Each step in a multi-turn workflow is transparent and inspectable. Alyx proposes a plan, you approve or modify it, and execution proceeds with human oversight at every gate. The shift is subtle but significant: you go from “I configure evals” to “I direct an AI that configures evals.” The expertise required to operate the evaluation harness drops dramatically without sacrificing rigor or control.
This is where the evaluation practice starts scaling beyond the engineers who built it. A domain expert who understands what “correct” means for their use case can drive evaluation workflows end to end — building evaluators, running experiments, interpreting results — without writing code or learning a CLI.
 Run: Headless Developer Workflows
Run: Headless Developer Workflows
For engineering teams iterating fast, the platform exposes a fully documented CLI with a skills framework that AI coding agents can consume directly.
The AX CLI gives programmatic access to every platform capability: exporting spans, creating evaluators, wiring up tasks, triggering runs, pulling results. The skills docs give AI coding agents — Cursor, Claude Code, Windsurf, Codex, whatever you use — full context on APIs, data schemas, and experiment workflows. Your coding agent doesn’t just execute commands blindly; it understands the platform’s data model and can reason about what to do next.
The real workflow looks like this: your agent fetches open alerts from a failing monitor, exports the relevant spans, analyzes the failure pattern, drafts a prompt fix, runs a targeted evaluation against the modified version, compares results to the baseline, and pushes the change for review or directly into CI/CD. Human in the loop, but AI-accelerated at every step.
Evaluation moves from a separate activity into the development inner loop. The harness becomes part of how you ship — not something you check after the fact.
 Fly: Monitor-Triggered Autonomous Agents
Fly: Monitor-Triggered Autonomous Agents
This is the North Star.
A monitor detects degradation on an evaluation metric — hallucination rates spiking in a specific semantic cluster, tool-call failure rates climbing after a model update, retrieval relevance dropping in a new topic area. It fires an alert via webhook. That webhook triggers an always-on agent with AX CLI access and full skills context. The agent triages autonomously: exports the relevant spans, runs targeted evaluations to isolate the failure mode, identifies the cluster boundary, and surfaces structured findings for human review — or, for well-understood failure patterns, drafts and tests a fix directly.
This isn’t science fiction. Every primitive — monitors with configurable thresholds, webhook-based alert routing, the CLI, the skills framework — exists today. The composition is the frontier. The most advanced teams are already building toward this: evaluation infrastructure that doesn’t just measure your system but actively participates in maintaining it.
You don’t start here. You build toward it. Each stage in the maturity model lays the foundation for the next: GUI familiarity leads to AI-assisted workflows, which lead to programmatic access, which leads to full automation. The harness architecture stays the same throughout. The only thing that changes is how much of it runs without you.
Start Wherever You Are
One architecture. Four levels of operational maturity. Start wherever your team is today and grow into the next stage when you’re ready. The evaluation harness doesn’t force a workflow — it grows with you.
Coming next: We’ll break down the evaluation harness architecture in detail — how inputs, execution, and actions compose into the system that powers all four of these workflows from a single platform.
Try it yourself: Want to experience the first three stages hands-on? We built a companion notebook that takes you from zero instrumentation to AI-assisted evaluation in a single session.
The post From First Eval to Autonomous AI Ops: A Maturity Model for AI Evaluation appeared first on Arize AI.