Accuracy tells you a model got the right answer. It doesn’t tell you whether to trust it, deploy it, or stake your product on it.
1. The number that broke AI benchmarking
In 2023, a major LLM scored over 85% on a widely cited reasoning benchmark. Researchers celebrated. Blog posts were published. Comparisons were drawn to human performance.
Then someone tried a simple experiment: they rephrased the benchmark questions. Same logic, different wording. The model’s accuracy dropped by more than 20 percentage points.
Nothing about the underlying task had changed. The model hadn’t gotten worse. It had never been as good as the number suggested.
“LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on sophisticated reasoning abilities.” Mondorf & Plank, 2024
This is the accuracy trap. And it’s not an edge case. It is, according to a 2024 survey published at COLM, a systematic feature of how current LLMs behave, and how we’ve been measuring them.
This article is about fixing your measurement. We’ll go through what accuracy misses, what the research says we should be measuring instead, and how to build an evaluation approach that actually tells you whether a model is fit for your purpose.

2. Accuracy: what it measures, what it misses
Accuracy is seductive. It’s a single number. It ranks models cleanly. It shows up neatly in leaderboards and press releases. And for narrow, well-defined classification tasks, is this email spam? Does this image contain a cat? It does the job.
The problem is that most real LLM tasks aren’t narrow and well-defined. They’re open-ended, contextual, and performed by users who phrase things inconsistently, make typos, add irrelevant context, or switch languages mid-prompt.
Mondorf and Plank’s 2024 survey systematically reviewed studies that probed LLM reasoning beyond simple task performance. Their central finding: when you look past accuracy, models frequently reveal that they are not reasoning, they are pattern-matching.
The shortcut learning problem
A model trained on a large corpus will absorb statistical regularities in that corpus. If answer choice “A” tends to be correct more often on a benchmark, the model may learn to favour A. If questions containing the word “not” tend to have a different answer distribution, the model picks that up too.
This is called shortcut learning: achieving high accuracy by exploiting statistical artefacts in the dataset rather than solving the actual problem. The model looks capable. The metric confirms it. The underlying behaviour is fragile.

The benchmark contamination problem
There is a second, increasingly serious issue: data contamination. Many prominent benchmarks like MMLU, HellaSwag, and GSM8K have been circulating for years. The training corpora of modern LLMs almost certainly contain text that overlaps with, or directly reproduces, benchmark questions and answers.
When a model scores 90% on MMLU, you cannot be certain whether that reflects generalisation ability or memorisation. The metric doesn’t distinguish between the two. This is not a niche research concern; it is a fundamental validity problem that affects how the entire industry compares models.
3. The 6 metrics that actually matter
In 2022, researchers at Stanford’s Centre for Research on Foundation Models published HELM: Holistic Evaluation of Language Models. It is one of the most comprehensive LLM evaluation frameworks to date, covering 42 scenarios, 30 models, and 7 core metrics.
The core insight behind HELM: no single metric is sufficient. Every metric reveals something different about a model’s behaviour. Evaluating only accuracy is like evaluating a car only on its top speed, technically informative, practically misleading.
Here are the six non-accuracy metrics that matter, what each one tells you, and what goes wrong when you ignore it.
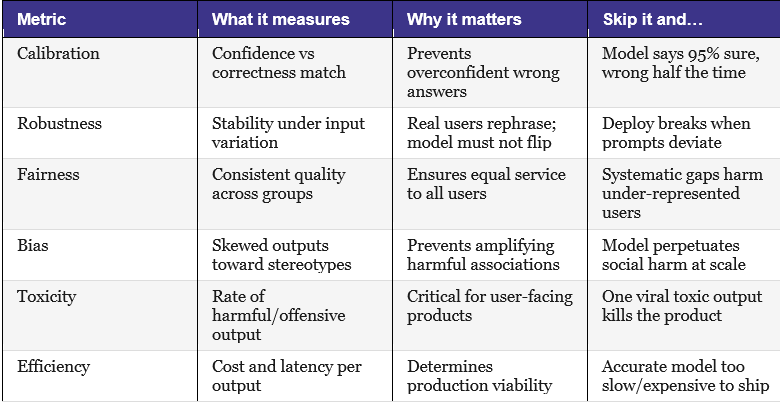
Calibration: Does the model know what it doesn’t know?
A well-calibrated model is one whose confidence matches its actual accuracy. When it says it’s 90% confident, it should be right about 90% of the time. When it says 60%, it should be right roughly 60% of the time.
Most LLMs are poorly calibrated. They express high confidence even on questions where they are wrong, a behaviour sometimes called hallucination with conviction. For high-stakes applications (medical, legal, financial), calibration may be more important than accuracy. A model that is right 80% of the time but always tells you when it’s uncertain is more useful than one that is right 85% of the time but never admits doubt.
Robustness: Does it hold up under variation?
Robustness measures how stable a model’s outputs are when inputs change in ways that shouldn’t change the answer: synonym substitution, reordering of information, different phrasing, added irrelevant context, and spelling errors.
HELM’s evaluations found significant robustness gaps across models. A model that handles a clean benchmark prompt well may handle a messy real-world prompt poorly. Since real users never type clean benchmark prompts, robustness is a direct proxy for production reliability.
Bias: what associations is it amplifying?
Bias evaluation tests whether the model’s outputs systematically associate certain groups with certain attributes in ways that reflect or reinforce social stereotypes. This is distinct from fairness: a model can treat all groups equally poorly (fair but biased) or treat them unequally without stereotyping (unfair but less biased).
Bias tends to be invisible until it isn’t. A content generation tool might produce subtly gendered descriptions of professionals for months before someone notices the pattern. Proactive bias evaluation surfaces these issues in the lab, not in production.
Toxicity: what’s the floor on harmful output?
Toxicity metrics measure how frequently a model produces content that is offensive, harmful, or dangerous, under adversarial prompting, edge-case inputs, or even normal use. The key insight: toxicity is a tail risk. A model might produce toxic output only 0.3% of the time, but at scale, 0.3% is thousands of harmful outputs per day.
Toxicity evaluation should include both standard and adversarial conditions. Models that behave well under neutral prompts sometimes behave very differently when users probe their limits.
Efficiency: Can you actually afford to deploy it?
Efficiency measures latency, throughput, and cost per inference. It is frequently omitted from research evaluations because it is infrastructure-dependent. It is rarely irrelevant to practitioners.
A model that scores 92% accuracy but costs $40 per thousand tokens and takes 8 seconds per response may be completely impractical for your use case. A model that scores 84% but costs $2 and responds in 400ms may be the right choice. HELM’s inclusion of efficiency as a core metric reflects this reality.
4. The evaluation gap: what the research found
Before HELM, the state of LLM evaluation was fragmented in a way that is, in retrospect, remarkable. Liang et al. found that prior to their work, models were evaluated on an average of just 17.9% of the same core scenarios, meaning different models were rarely tested on the same tasks under the same conditions.
If two models have never been tested on the same benchmark under the same conditions, any comparison between them is essentially fiction.
HELM improved this to 96%, all 30 models benchmarked on the same core scenarios. What they found when they finally looked at the same models through the same lens: the rankings changed significantly depending on which metric you prioritised. A model that ranked first on accuracy ranked seventh on fairness. A model that ranked third on accuracy ranked first on efficiency.
This is the finding that should reshape how your team discusses model selection. There is no universally best model. There is only the best model for your specific metric priorities, your specific use case, and your specific user base.
5. Reasoning behaviour vs reasoning performance
The deepest contribution of Mondorf and Plank’s survey is a distinction that the field has been slow to operationalise: the difference between reasoning performance and reasoning behaviour.
Reasoning performance is what we currently measure: did the model get the right answer on a set of reasoning tasks? Reasoning behaviour is what we actually want to understand: how did the model arrive at that answer, and would it arrive at the same answer through a different route?
Why the distinction matters
Consider a model that consistently answers multi-step arithmetic problems correctly. Two explanations are possible. First: the model has learned arithmetic and is applying it. Second: the model has memorised patterns from its training data that happen to produce correct outputs on these specific problem types.
These two models would score identically on a standard accuracy benchmark. They would behave very differently in production, specifically on problems that deviate from the training distribution in any way.

Behavioural probing: what it looks like in practice
Researchers are developing behavioural evaluation methods that go beyond asking “did the model get it right” to asking “does the model’s reasoning hold up under perturbation?” Techniques include:
- Consistency probing: ask the same question in multiple equivalent forms and check whether the model gives consistent answers
- Counterfactual testing: change a non-logically-relevant aspect of the problem and verify the answer changes only when it should
- Chain-of-thought auditing: examine the model’s stated reasoning steps and check whether they are actually causally linked to the output
- Adversarial rephrasing: systematically vary phrasing, syntax, and context to measure how much the model’s output depends on surface form
These methods are not yet standardised, and they require more effort than running a model through a benchmark. But they are the direction the field needs to move in, and the direction practitioners should start moving in now, even informally.
6. How to evaluate an LLM for your use case
Different applications demand different metric priorities. A one-size-fits-all evaluation suite does not exist, and trying to use one will either mislead you or bury the signal you actually need.
Here is a practical framework for matching metrics to task type:
Customer support and conversational AI
- Users rephrase, abbreviate, and make errors constantly. Robustness is paramount
- Any harmful output is a brand and legal risk. The toxicity threshold must be tight
- The model should know when to hand off to a human. Calibration matters for escalation
- Latency over 2 seconds, degrades conversation quality. Efficiency directly affects experience
Code generation and developer tools
- Code either runs, or it doesn’t. Accuracy on functional correctness is meaningful here
- Developers describe requirements differently. Robustness to specification variation
- But not zero (generated code can contain biased variable names, comments). Bias evaluation is a lower priority
Medical, legal, and financial summarisation
- Overconfident wrong answers in these domains cause direct harm. Calibration is the top priority
- Hallucination is a safety issue, not just a quality issue. Factual accuracy with source attribution
- Input documents varies enormously. Robustness to jargon and format variation
- The primary risk is confident misinformation, not offensive language. Toxicity is relevant but secondary
Content generation for diverse or global audiences
- Quality must not degrade for non-standard English users. Fairness across dialects and languages
- Content generation at scale amplifies any systematic associations. Bias evaluation is critical
- Fringe topics often receive lower-quality outputs than mainstream ones. Robustness to topic variation

7. The honest conclusion
Here is what the research tells us, plainly: we do not yet fully understand how LLMs reason. We can measure what they output. We can probe their behaviour. But the internal processes that produce those outputs remain largely opaque, even to their creators.
This uncertainty is not a reason to avoid deploying LLMs. It is a reason to deploy them carefully, with eyes open, with the right metrics in place, and with the humility to know that a benchmark score is not a guarantee.
Mondorf and Plank close their survey by calling for research that “delineates the key differences between human and LLM-based reasoning.” That is a long-term project. In the short term, the practical version of that call is simpler:
- Stop treating accuracy as a proxy for capability
- Evaluate the metrics that match your specific risk profile
- Test under conditions that resemble how real users will actually interact with your model
- Treat evaluation as an ongoing practice, not a one-time gate
The models are getting better. The evaluations need to keep pace.
References
Mondorf, P. & Plank, B. (2024). Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models — A Survey. COLM 2024. arXiv:2404.01869
Liang, P., Bommasani, R., et al. (2022). Holistic Evaluation of Language Models (HELM). Transactions on Machine Learning Research (2023). arXiv:2211.09110
Evaluating LLMs: Beyond Accuracy — What Metrics Actually Matter was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.