Six phases of dbt. SQLMesh added on top. Same Nessie backend, same Iceberg tables, same bronze layer, provably identical gold layer. What I learned the hard way.
SQLMesh + Nessie + Trino + Iceberg with full virtual data environments is not clearly documented anywhere. You are reading the first person who built it end-to-end and wrote about it honestly.
Most dbt vs SQLMesh articles compare marketing pages. This one is different. The two tools ran simultaneously on the same Trino catalog, against the same Brazilian e-commerce dataset, producing provably identical output down to floating-point parity. The setup is reproducible. The receipts exist.
What follows is not a benchmark. It is a confession — every blocker, every orphaned S3 folder, every macro workaround, and the one architectural breakthrough that lets both tools coexist on the same backend.
The Arena
The stack
Not AWS Glue. Not Databricks. A NAS under a desk and an Ubuntu laptop on the same LAN.
PostgreSQL ─── source data + SQLMesh state DB
SeaweedFS ─── S3-compatible object storage
Nessie ─── Iceberg catalog (Git for data)
Trino ─── query engine
Dremio ─── semantic / BI layer
↓
dbt-trino AND SQLMesh ─── same nessie_rest catalog
↓
Kestra (orchestration)
Hardware: UGREEN NASync DXP2800 (16 GB RAM, always-on) for storage and orchestration; ASUS Zephyrus G16 (Ubuntu 24.04, 64 GB RAM, RTX 5070 Ti) for compute. Every constraint hit in this article is a real production constraint — no managed service papering over bugs.

What was built before this comparison
dbt earned its scars first. SQLMesh came in clean. That sequence is what makes this comparison fair — neither tool is being judged on a greenfield idealization.

dbt earned its scars first. SQLMesh came in clean. That sequence is what makes this comparison fair — neither tool is being judged on a greenfield idealization.
The blocker nobody warned me about
The first thing that will stop you cold if you try to run SQLMesh on Nessie + Trino:
TrinoUserError: createView is not supported for Iceberg Nessie catalogs
Native Nessie’s Trino catalog (iceberg.catalog.type=nessie) blocks every CREATE VIEW. SQLMesh's entire virtual environment model depends on views — that is how dev/prod isolation is implemented. Most articles stop here and conclude that SQLMesh and Nessie are incompatible. That conclusion is wrong.
The hidden door
Nessie 0.99+ exposes a second protocol on the same service: an Iceberg REST catalog at /iceberg/main/. REST implements the Iceberg catalog spec natively, which supports views. Same Nessie service, same backend storage, same data — different door.
# Verify the REST endpoint exists on your Nessie instance
curl http://localhost:10041/iceberg/main/v1/config
# Look for: POST /v1/{prefix}/namespaces/{namespace}/views
# Present in 0.107.4. Absent in older versions.
The fix is a single Trino catalog file:
# trino/catalog/nessie_rest.properties
connector.name=iceberg
iceberg.catalog.type=rest
iceberg.rest-catalog.uri=http://nessie:19120/iceberg/main/
iceberg.rest-catalog.warehouse=lakehouse
CREATE VIEW works. SQLMesh's environment system works. The whole model is unlocked.
The version trap
The :latest Nessie Docker image was sitting at 0.76 for months. REST endpoint does not exist there. Pin explicitly:
image: ghcr.io/projectnessie/nessie:0.107.4
Upgrading from 0.76 to 0.107.4 required dropping and recreating the Nessie state database. The Iceberg metadata in S3 survives — only the catalog state resets — and every table needs to be re-registered through nessie_rest.system.register_table(). Location strings must byte-match what is in each table's metadata.json. Old PySpark code that wrote s3a://lakehouse//bronze/... with a double slash is invisible to the strict REST catalog. Fix the writer, regenerate the metadata, re-register.
The real breakthrough: coexistence on one catalog
Once the REST endpoint is working, dbt and SQLMesh run on the same nessie_rest Trino catalog with no conflict. Schema namespacing is the only isolation mechanism needed:
nessie_rest (iceberg.catalog.type=rest)
├── bronze/ ← 10 EXTERNAL tables (PySpark owns)
├── silver_dbt/ ← 7 dbt physical tables
├── gold_dbt/ ← 3 dbt physical tables
├── sqlmesh__silver/ ← SQLMesh physical layer (snapshot tables with hash suffix)
├── sqlmesh__gold/ ← SQLMesh physical layer
├── silver/ ← SQLMesh views (virtual layer, prod env)
├── gold/ ← SQLMesh views (virtual layer, prod env)
└── silver__dev / gold__dev/ ← on-demand by `sqlmesh plan dev`

Both tools read from the same bronze tables. Both write through the same catalog endpoint. This is the architectural insight that nothing else in the public documentation prepares you for, and it is what makes migration tractable.
You do not need a parallel Nessie instance, a separate Trino catalog, or a big-bang cutover. Drop the silver_dbt and gold_dbt schemas when the team is ready. SQLMesh is already running alongside.
268 files vs zero: the orphan audit
After six phases of dbt with --full-refresh operations, the count came back ugly:

Why dbt creates orphans
materialized='table' performs DROP + CREATE on each run. Without an explicit location= config, Iceberg writes the new table to a new S3 path. The old path is no longer referenced by Nessie metadata, but the parquet files stay on SeaweedFS forever. Across six phases of development, those orphan folders accumulate.
The dbt-side fix required three changes:
- Add location='s3a://lakehouse/silver/model_name' to every model config
- Switch from materialized='table' to materialized='incremental'
- Build 04_cleanup_orphaned_folders.py — 200+ lines that query Trino's SHOW CREATE TABLE to identify live S3 paths and delete everything else
That script is now part of every dbt Kestra flow. Mandatory hygiene.
The incident that proved the script needed a safety guard
The cleanup script originally swallowed Trino exceptions with except Exception: print(). After Phase 11's catalog rename, every "what to keep" query silently failed. The script saw an empty keep-set and proceeded as designed: it deleted everything not on the keep list.
Result: every silver and gold folder in S3 was deleted — 10 folders, 25 parquet objects. Tables remained queryable for a brief window because Nessie metadata still pointed at the (now nonexistent) files. Recovery: dbt run --full-refresh to regenerate everything from bronze.
The fix is two safety layers:
# Every Trino failure now raises hard
try:
live_folders = query_trino_for_live_paths()
except Exception as e:
raise RuntimeError(f"Trino query failed — aborting cleanup: {e}")
# Final guard: an empty live set is almost certainly a query failure,
# not reality
if len(live_folders) == 0:
raise RuntimeError("Live folder count returned 0 -
refusing to delete anything")
The class lesson is more important than the specific bug: any cleanup script that reads live state to decide what to delete must treat query failures as hard errors, and must refuse to act on an empty keep-set. “Nothing to protect” and “the query is broken” are indistinguishable from inside the script. Always assume the second.
Why SQLMesh has zero orphans
SQLMesh’s PostgreSQL state backend records every physical table and its S3 path at creation time. sqlmesh janitor diffs the state database against actual S3 contents and removes anything not referenced. Orphans are architecturally impossible.
This is not a maturity difference. It is a design philosophy difference: dbt hands file lifecycle management to the user, SQLMesh internalizes it. At scale, companies hire full-time Data Platform SRE roles to manage exactly this hygiene. SQLMesh makes that role unnecessary for this class of problem.
Four macros down, one survivor
The dbt setup ran two query targets — Trino (development, primary) and Dremio (BI semantic layer, secondary). Cross-engine compatibility cost five macros. Migrating to SQLMesh eliminated four of them.
The problem the macros were solving

The dbt model (Phase 9 silver_orders)
{{ config(
schema='silver_dbt',
unique_key='order_id',
incremental_strategy='append',
views_enabled=false
) }}
SELECT
order_id,
customer_id,
{{ safe_cast('purchase_ts', 'TIMESTAMP') }} AS order_purchase_date,
{{ safe_cast('delivered_ts', 'TIMESTAMP') }} AS order_delivered_date,
{{ date_diff_days('purchase_ts', 'delivered_ts') }} AS delivery_days
FROM {{ source('bronze', 'olist_orders') }} {{ at_branch() }}
WHERE order_id IS NOT NULL
AND purchase_ts IS NOT NULL
{% if is_incremental() %}
AND CAST(purchase_ts AS TIMESTAMP) > (
SELECT MAX(order_purchase_date) FROM {{ this }}
)
{% endif %}Five macro invocations in a 20-line model. Every new engine target requires new macro branches. Every macro is a maintenance surface.
The SQLMesh equivalent
MODEL (
name silver.silver_orders,
kind INCREMENTAL_BY_UNIQUE_KEY (unique_key order_id),
dialect trino
);
SELECT
order_id,
customer_id,
TRY_CAST(purchase_ts AS TIMESTAMP) AS order_purchase_date,
TRY_CAST(delivered_ts AS TIMESTAMP) AS order_delivered_date,
DATE_DIFF('day',
TRY_CAST(purchase_ts AS TIMESTAMP),
TRY_CAST(delivered_ts AS TIMESTAMP)) AS delivery_days
FROM nessie_rest.bronze.olist_orders
WHERE order_id IS NOT NULL
AND purchase_ts IS NOT NULL
Declare dialect trino once. Write plain Trino SQL. sqlglot — the SQL parser and transpiler built into SQLMesh — handles dialect translation to whatever engine actually runs the query.
The SQLMesh equivalent
MODEL (
name silver.silver_orders,
kind INCREMENTAL_BY_UNIQUE_KEY (unique_key order_id),
dialect trino
);
SELECT
order_id,
customer_id,
TRY_CAST(purchase_ts AS TIMESTAMP) AS order_purchase_date,
TRY_CAST(delivered_ts AS TIMESTAMP) AS order_delivered_date,
DATE_DIFF('day',
TRY_CAST(purchase_ts AS TIMESTAMP),
TRY_CAST(delivered_ts AS TIMESTAMP)) AS delivery_days
FROM nessie_rest.bronze.olist_orders
WHERE order_id IS NOT NULL
AND purchase_ts IS NOT NULL
Declare dialect trino once. Write plain Trino SQL. sqlglot — the SQL parser and transpiler built into SQLMesh — handles dialect translation to whatever engine actually runs the query.
What sqlglot does with TRY_CAST

You write once in your declared dialect. sqlglot rewrites at execution time for any target. The same applies to DATE_DIFF, function name differences, argument order conventions, and dozens of other ANSI variations.
The macro elimination scorecard
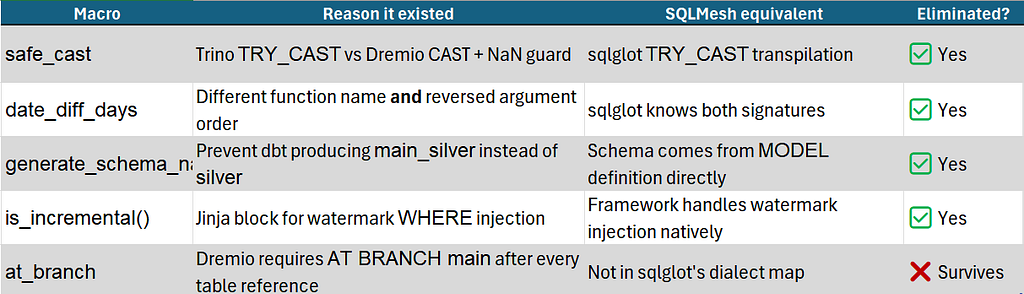
Net: 4 of 5 macros eliminated. The surviving at_branch is the honest caveat: sqlglot covers ANSI SQL and engine-standard extensions, not vendor-specific runtime syntax like Dremio's Nessie branch parameter. That kind of transformation needs a tool-level workaround regardless of which SQL framework you use.
The “wait, dbt cannot do that?” moment
SQLMesh refuses to deploy a change without first showing you what will happen and asking for confirmation. To demonstrate this, I made a deliberate breaking change to silver_orders (changed TRY_CAST(purchase_ts AS TIMESTAMP) to TRY_CAST(purchase_ts AS VARCHAR)) and added a non-breaking column (demo_added_date). Then ran sqlmesh plan dev:
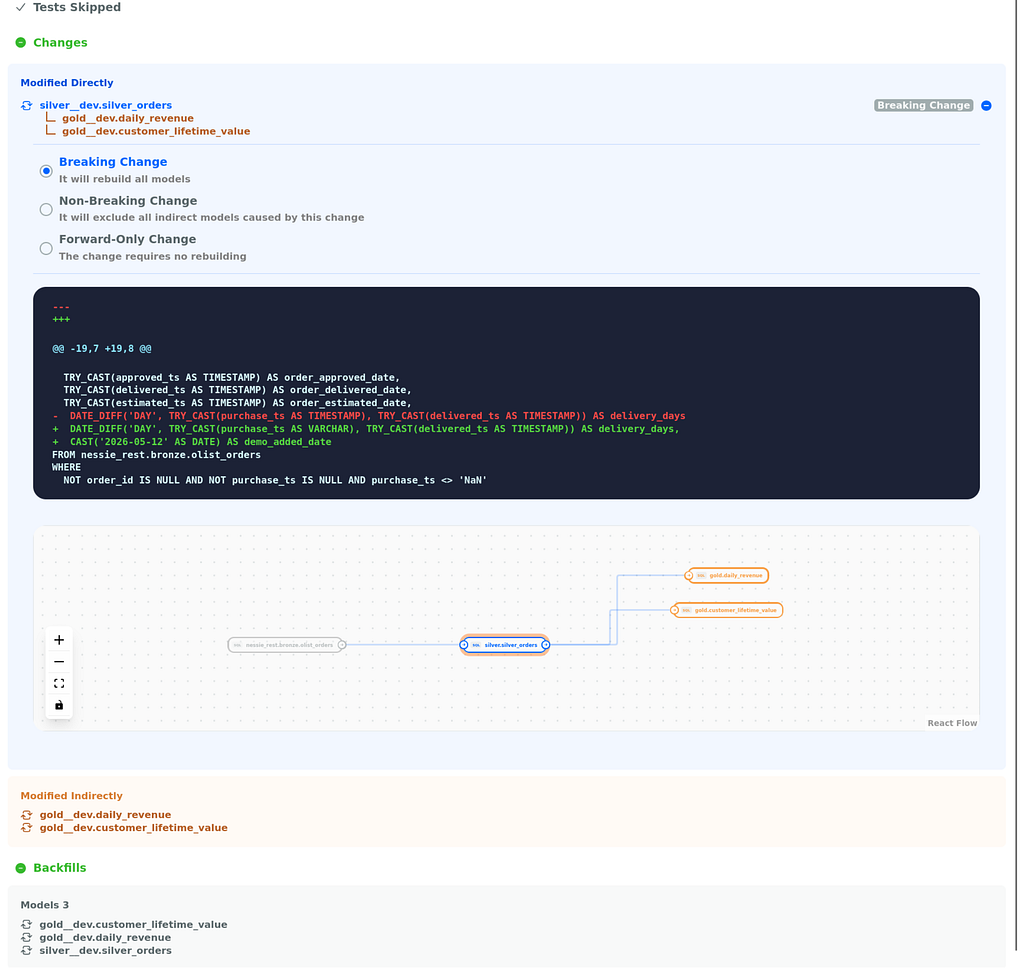
The radio buttons matter. “Breaking Change,” “Non-Breaking Change,” “Forward-Only Change” — SQLMesh classifies the impact automatically, defaults to the safe choice, and lets you confirm or override. dbt has no equivalent. With dbt, you push the change to production, the model rebuilds, downstream models break, and you find out from the failure.
This is the workflow difference that converts skeptical dbt users in seconds.
The Iceberg View Dialect Lock
This is the production blocker I was not warned about and could not find documented anywhere.
When Dremio tried to read a SQLMesh-generated view from nessie_rest.silver.*:
This view contains unsupported SQL dialects.
Supported dialects are: [DREMIO, DREMIOSQL, SPARK].
Actual dialects in representations: [trino]
What is happening
The Iceberg View specification stores SQL with a dialect tag embedded in view metadata. When Trino creates a view, it tags it trino. When Dremio opens the same view, it checks the dialect tag, sees trino, and refuses to execute — protecting users from running SQL that may behave differently across engines.
This is industry-wide behavior, not a SQLMesh bug. Dremio’s own documentation describes the inverse: Trino cannot read Dremio-created views either. Each engine treats foreign-dialect views as untrusted.
Initial conclusion (wrong): SQLMesh and Dremio are incompatible.
The workaround that actually works
Iceberg physical tables are engine-agnostic. They are binary Parquet plus Iceberg metadata — no SQL, no dialect tag. Only views carry the dialect lock.
SQLMesh writes physical tables to sqlmesh__silver and sqlmesh__gold (the names include hash suffixes like silver__orders__1258931077). The silver and gold schemas are virtual views that point at those physical tables — and those views are what Dremio refuses to read.
The fix: point Dremio Virtual Datasets (VDS) at the physical tables, not the virtual views.
Dremio "Business Analytics" space
├── silver_sqlmesh/ ← VDS folder
│ ├── orders ──────→ nessie_rest.sqlmesh__silver.silver__orders__1258931077
│ ├── customers ─────→ nessie_rest.sqlmesh__silver.silver__customers__9047281033
│ └── ...
└── gold_sqlmesh/ ← VDS folder
├── daily_revenue ──→ nessie_rest.sqlmesh__gold.gold__daily_revenue__7782341984
└── ...
The hash stability concern (and why it is not a concern)
The hash suffix on SQLMesh’s physical table names looks alarming at first. If silver__orders__1258931077 becomes silver__orders__9988776655 tomorrow, every Dremio VDS breaks.
Tested empirically: capture the table list, run sqlmesh run, capture again. Identical hash.
SQLMesh’s snapshot hash is computed from the model SQL definition, not from the data. The hash rotates only when a developer edits the model SQL — a deliberate engineering change, not a daily refresh event. Across Phase 11 the gold__daily_revenue hash rotated exactly once: when I added a total_product_revenue column. Daily data refreshes in between left every hash untouched.
That makes the VDS-over-physical-tables pattern viable for production. The day a model SQL changes is a deployment day — exactly when you would rebuild downstream artifacts anyway.
Three architecture patterns

All three are validated on this stack.
Two SSH tasks. That’s the whole pipeline.
The Kestra orchestration comparison is the moment the philosophical difference between the two tools becomes operational.
The dbt production reality
Daily transformation requires lakehouse_transform — four orchestrated tasks: clone the repo, run dbt on silver, run dbt on gold, run dbt tests. Each dbt task internally also does pip install dbt-trino, copies a profiles.yml, and runs dbt deps. Then a separate weekly lakehouse_maintenance flow handles orphan cleanup.


The SQLMesh production reality

First-run output:
INFO 2026-05-10T20:08:01 Cleanup complete.
INFO 2026-05-10T20:08:02 ✅ SQLMesh pipeline complete — models refreshed, orphans cleaned
Side-by-side
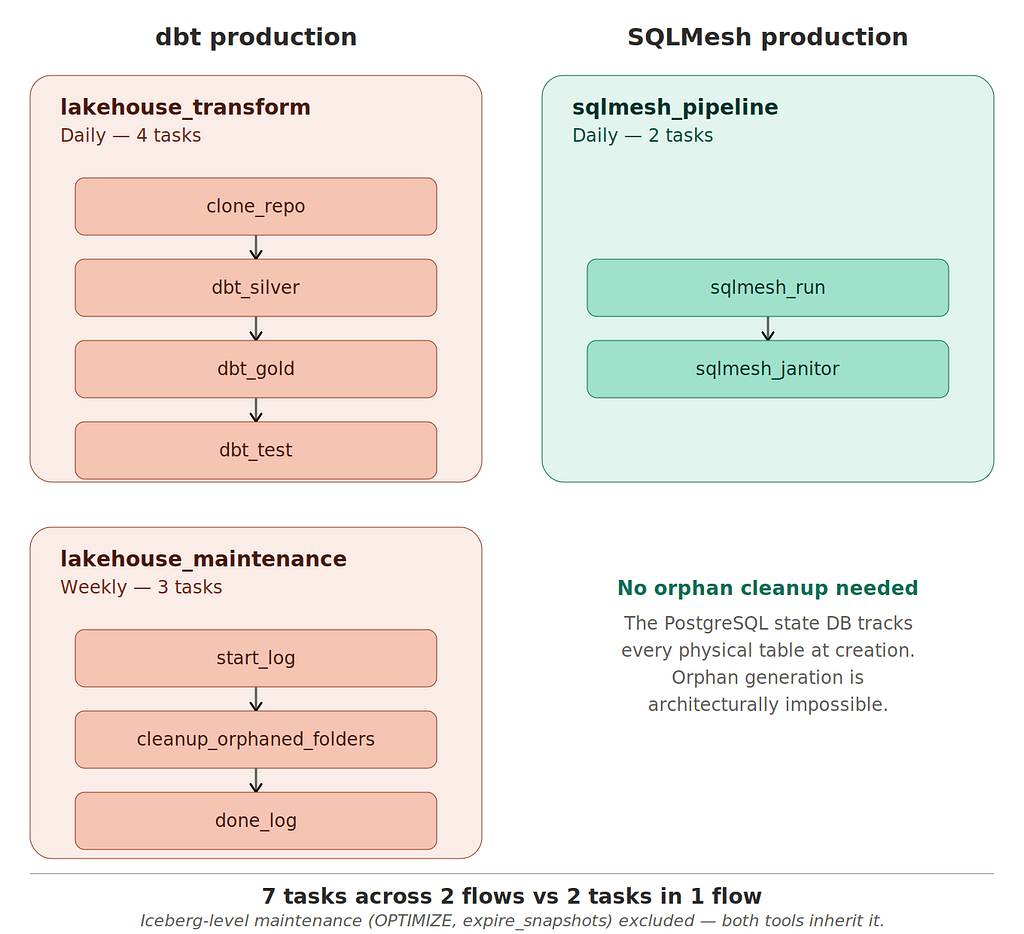
Two SSH tasks. No profile management. No pip installs. No macros. No cleanup script. No separate maintenance flow.
This is not a bug-for-bug comparison. It is the difference between a tool designed before lakehouse catalogs were first-class (dbt, 2016) and one designed for the catalog era (SQLMesh, 2023). The dbt complexity is real, earned, and well-understood — every piece exists because dbt was not designed to own these concerns. SQLMesh internalizes them by default. The Kestra simplicity is a symptom, not the cause.
A skeptical reader will ask: won’t SQLMesh eventually need OPTIMIZE and expire_snapshots too? Yes — Iceberg snapshot accumulation and file fragmentation are tool-agnostic concerns. The architectural win shown above is in one specific category: orphan S3 folder generation. dbt’s materialized='table' creates that category by design. SQLMesh eliminates it entirely. The remaining Iceberg-level maintenance applies to both tools and is excluded from this comparison.
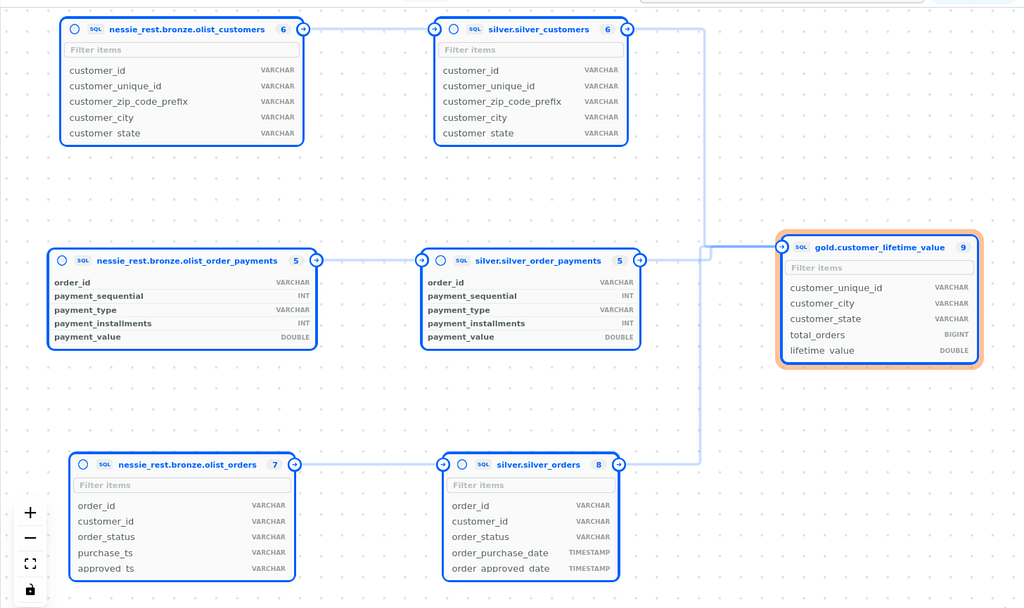
Both tools, same bronze, identical gold
Two pipelines, same source data, same business logic. The outputs are mathematically identical.
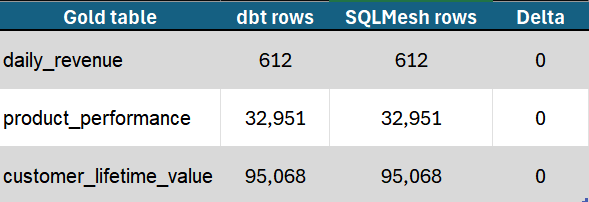
The cross-validation query:
SELECT s.order_date,
s.total_revenue - d.total_revenue AS diff
FROM nessie_rest.gold.daily_revenue s
JOIN nessie_rest.gold_dbt.daily_revenue d ON s.order_date = d.order_date
WHERE ABS(s.total_revenue - d.total_revenue) > 1e-6;
-- Expected: 0 rows. Sub-threshold floating-point noise filtered out.
Without the ABS > 1e-6 filter the query returns 453 rows where the diff is in the 1e-10 range — IEEE 754 floating-point summation order differences between Trino's incremental append plan and the full-refresh plan. Mathematically equivalent. With the threshold filter, the result is zero rows of real divergence across 612 daily revenue points.
Validated: same business logic + same engine = same output. The choice between dbt and SQLMesh does not introduce data differences. The decision is architectural, not correctness-based.
The full decision matrix

Three patterns, all validated
dbt is more mature in community and ecosystem. SQLMesh is more mature in design philosophy. Both statements are true. Neither tool is better in the abstract — the right choice depends on what you are building and what your team already runs.
Pattern 1 — dbt + Dremio. dbt manages all Iceberg tables via the dbt-trino or dbt-dremio adapter. Dremio reads those physical tables and adds its semantic layer on top. Battle-tested, mature ecosystem, every BI tool connects to Dremio without issue. Best for organizations where data analysts outnumber data engineers and the existing dbt investment is significant.
Pattern 2 — SQLMesh + Trino direct. SQLMesh handles transformation, environments, and hygiene. Engineers query Trino directly or through any Iceberg-native tool. No Dremio dependency. Best for engineering-first organizations that want developer tooling parity with software engineering practices — sqlmesh plan dev to create an isolated dev environment in 30 seconds, sqlmesh plan prod to promote with a 10-second view swap, no data recompute.
Pattern 3 — SQLMesh + Dremio via physical tables. SQLMesh for transformation and environments, Dremio VDS pointed at SQLMesh’s hash-stable physical tables (sqlmesh__silver, sqlmesh__gold) for the semantic layer. The dialect lock on views is sidestepped because physical tables carry no dialect tag. Best for organizations that need both: engineering-grade tooling and a governed BI layer. This is the pattern I would build for a client today.
The honest closing
dbt was designed in 2016, before lakehouse catalogs existed as first-class infrastructure. The friction across Phases 5–10 — macros, orphans, manual branch management, profile juggling — is the cost of using dbt against problems it was not designed for. That cost is real, well-understood, and manageable. It is not a reason to rip and replace a working dbt investment.
For greenfield lakehouse projects, the question is different. SQLMesh was designed knowing that Iceberg, Nessie, and multi-engine environments would exist. The two-task Kestra pipeline, the zero orphan count, the plan-before-execute workflow, the built-in column-level lineage UI, the interactive environment promotion — these are not bolt-on features. They reflect a different starting assumption about what a transformation tool is responsible for.
The strongest evidence is simple: sqlmesh_pipeline is two SSH tasks, and it just works.
Appendix — For Technical Readers
A. Performance metrics

B. Gotcha quick reference
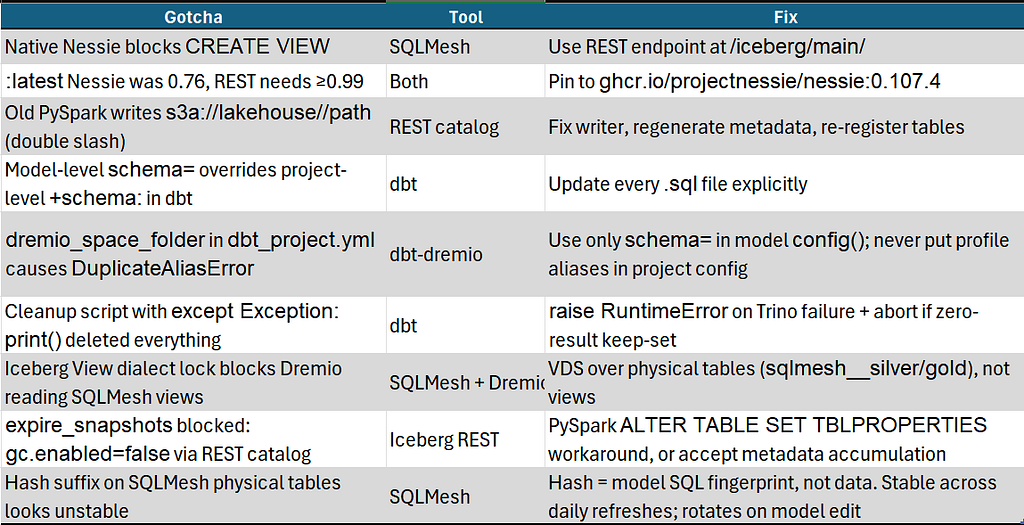
C. Q&A
Q: Can dbt and SQLMesh really run on the same Nessie backend simultaneously? Yes — and both use the same nessie_rest Trino catalog. dbt is schema-isolated to silver_dbt/gold_dbt. SQLMesh owns silver/gold/sqlmesh__*. Both read from the same bronze tables. Schema namespacing is the only isolation mechanism needed. Migration becomes incremental — drop the *_dbt schemas when the team is ready, SQLMesh is already running alongside.
Q: Does sqlglot eliminate all macros? No. It eliminates macros that abstract standard SQL dialect differences (TRY_CAST, DATE_DIFF, function name and argument order variations, etc.). It does not handle vendor-specific runtime syntax like Dremio's AT BRANCH main — that is a Nessie/Dremio integration concern, not a SQL dialect concern.
Q: Is the 268 orphan count a dbt flaw or user error? Partly both. materialized='table' plus Iceberg without explicit location= configs is a known rough edge in the dbt + Iceberg integration. The fix works once you know about it. SQLMesh makes the problem architecturally impossible — there is no equivalent user error to make.
Q: Will SQLMesh eventually need OPTIMIZE and expire_snapshots maintenance too? Yes. Iceberg snapshot accumulation and file fragmentation are tool-agnostic concerns at the table format level. The 7-tasks-vs-2 comparison in this article is specifically about orphan cleanup, which is dbt-specific. Both tools inherit Iceberg-level maintenance regardless of choice; SQLMesh’s incremental strategies write fewer fragments per run than dbt’s materialized='table' rebuilds, so the cadence is slower, but the eventual need is the same.
Q: Which pattern should a new client use?
- BI-heavy organization, needs Dremio, team already knows dbt → dbt + Dremio
- Engineering team, Trino-native, wants safety guarantees and dev/prod isolation → SQLMesh + Trino
- Wants both → SQLMesh + Dremio via physical tables
All three are validated on real infrastructure on this stack.
Maroun Sader is a Strategic Data & AI professional and architect. He writes about building real data infrastructure, not theoretical frameworks.
Stack used in this article: UGREEN NASync DXP2800 · Apache Iceberg · Project Nessie 0.107.4 · Trino · Dremio · SeaweedFS · Kestra · dbt-trino · dbt-dremio · SQLMesh · Ubuntu 24.04
dbt vs SQLMesh: An Honest Comparison on a Self-Hosted Lakehouse was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.