Automation accelerates slop or value
Welcome to a series on data science in 2026 (👋)
I’m about to publish my first book (Manning) on the 19/05/2026 — Building LLM applications with DSPy. This series is a reflection on what I learned throughout writing the book
TL;DR
Coding agents + DSPy = Trust & Performance
Continue reading if you want to understand what this means.
Content
- The reality of coding agents
- Coding agents risks in data science
- Use known frameworks and minimize code to mitigate risk
- From theory to practice — Karpathy’s Autoresearch
- DSPy — Autoresearch for prompts
- Summary
The reality of coding agents
As more code being generated automatically, the new bottleneck have moved to testing. I don’t think I need to provide any evidence to support this claim.
How does this affect machine learning, data science and LLM based features (AI?)?
Data science is supposed to be the perfect candidate for automation. The whole methodology of Machine Learning is setting a mathematical goal post, allocate compute and data and let it run. So why can’t you just ask Claude/Codex to slap a KPI on your task and let coding agents do their thing? If KPI achieved → DONE.
🥁🥁🥁
Because, there’s always a risk that the produced results are “bad”.
The KPI/metric is not the only acceptance criteria.
The same with code, getting a result is a must but not sufficient.
Even though we can imagine an automation of PRs —
for example, evidence A: Intercom: AI is approving our pull requests… —
it’s still not the norm.
We can replace “coding agents” with junior data scientists throughout the rest of the article and yet the meaning will remain the same. To “err” is human? Well it’s also very machine like. Lets list a couple of failure modes.
Leakages
Did you ever used test set or validation set to normalize features?
Well that’s leakage 101, you should only use the training set for fitting the normalization and then apply it for other datasets.
Here’s an example of leakage from MLE-STAR (Google’s attempt at automatic data science research) trying to solve a certain task.

MLE-STAR has a special component that’s responsible for looking for finding leakage and fixing it.
Overfitting a test set is also a frequent one, here’s a public complaint in openai’s mle-bench.
Evaluating the wrong thing
From “The More You Automate, the Less You See: Hidden Pitfalls of AI Scientist Systems”.
“Upon inspecting the generated code, we found that in this run,
the Agent Laboratory had selected only a subset of the provided benchmark dataset, rather than using the complete evaluation set…”
That’s a failure that’s hard to catch. The numbers add up, there’s no warning, just a slight modification of the pre-processing code.
Skipping baselines and ill managing computation costs
I’m sure this happened to you, it sure did happen to me several times. I was really eager to try out bigger models that will take longer to train, betting it will improve quality. Sometimes it did, but it never moonshot me to production.
The methodological approach starts with a baseline, and changing each time a single variable to help understand the effect of the change.
Tracking experiments
Experiment tracking is essential but it can be done in a way that’s intractable. For example, having a local .csv/.tsv is malleable to after thought changes. Weights and biases and Mlflow serve as a more solid experiment tracking tool, allowing to log whatever you need to enable error analysis.
Risk mitigation
- Basic: go over the code
- Create a shared infrastructure you can trust
So in order to minimize risk we need:
- Enforce minimal and simple code
- Enforce methodology through known frameworks and patterns
The recent Karpathy’s Autoresearch project does this perfectly.
Autoresearch drill down from a risk mitigation perspective
Introducing Autoresearch!

Autoresearch enables coding agents to optimize the training of an LLM.
How does it mitigates the outlined risks?
Here’s a portion of the program.md which is the input for the coding agent.
…
What can you do: Modify train.py — this is the only file you edit. Everything is fair game: model architecture, optimizer, hyperparameters, training loop, batch size, model size, etc.
What you CANNOT do:
- Modify prepare.py. It is read-only. It contains the fixed evaluation, data loading, tokenizer, and training constants (time budget, sequence length, etc).
- Install new packages or add dependencies. You can only use what’s already in pyproject.toml.
- Modify the evaluation harness. The evaluate_bpb function in prepare.py is the ground truth metric.
…
Lets break it down based on outlined principles:
- Preventing leakage — there’s a fixation of preprocessing
- Evaluation the right thing — there’s a fixation of evaluation
- Skipping baseline and ill managing computation costs — each experiment lasts only 5 minutes
- Minimal code — Three main files to read (prepare.py, train.py, program.md) and One main file to edit: train.py
- Tracking experiments — a git branch per experiment and a results file
- Use known patterns — Define the neural network and the training with PyTorch
This is not perfect, and should be customized to your use case. For instance, I love experiment tracking tools and their visability.
Now lets think of a different task such as a classification task based on a prompt that contains the task description and outputs a task.
DSPy — the autoresearch for prompt tasks
Great, now lets get back to the industry focus of 2026 which is building LLM based applications. The app/feature you’re working now has probably API calls to one of the major LLM providers. The LLM part might be a feature (summarizing documents) or maybe the main thing (chatbot, co-pilot).
Coding agents on prompt optimization, will it sink or float?

How do you go about evaluating and optimizing prompt based tasks?
How do you keep a minimal foot print of code?
How do you enforce sampling and evaluation?
There’s no PyTorch for prompt optimization! Or is it there?
Introducing DSPy — the original autoresearch like “harness” for prompt optimization
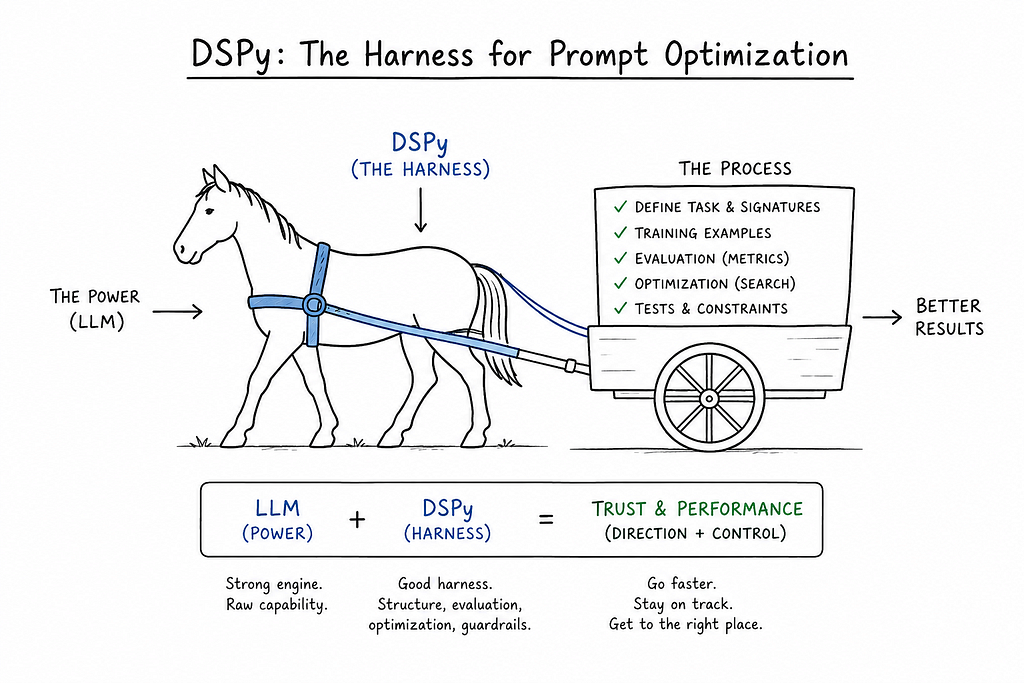
In my experiments I have pitted three different agents:
- Coding agent — Free style (within autoresearch limits)
- No coding agent — DSPy only
- Coding agent + DSPy
And in the next installment we will break down the results together.
Summary
Each data scientist is now becoming a manager of a very passionate hive of workers.
They do not sleep. But they are overly eager.
In order to make reliable progress, we need to figure out which processes enable trustworthy experimentation through minimzing code and reusing patterns.
For prompt optimization, DSPy is the best candidate for a Pytorch/scikit-learn experience.
If the info wasn’t satisfying enough, you can stay tuned for book discounts as well ;)
Links
- Friendly ML Architect Substack , subscribe to get book discounts and additional content
- My YouTube channel with +20 videos on DSPy and coding agents
- Feel free to DM on my personal LinkedIn
Data science in 2026 — we’re all managers was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.