Last quarter I watched a revenue forecasting agent confidently report that Q3 was up 14% year-over-year. The CFO loved it. The board saw it. Then someone in data engineering pointed out the number was wrong.
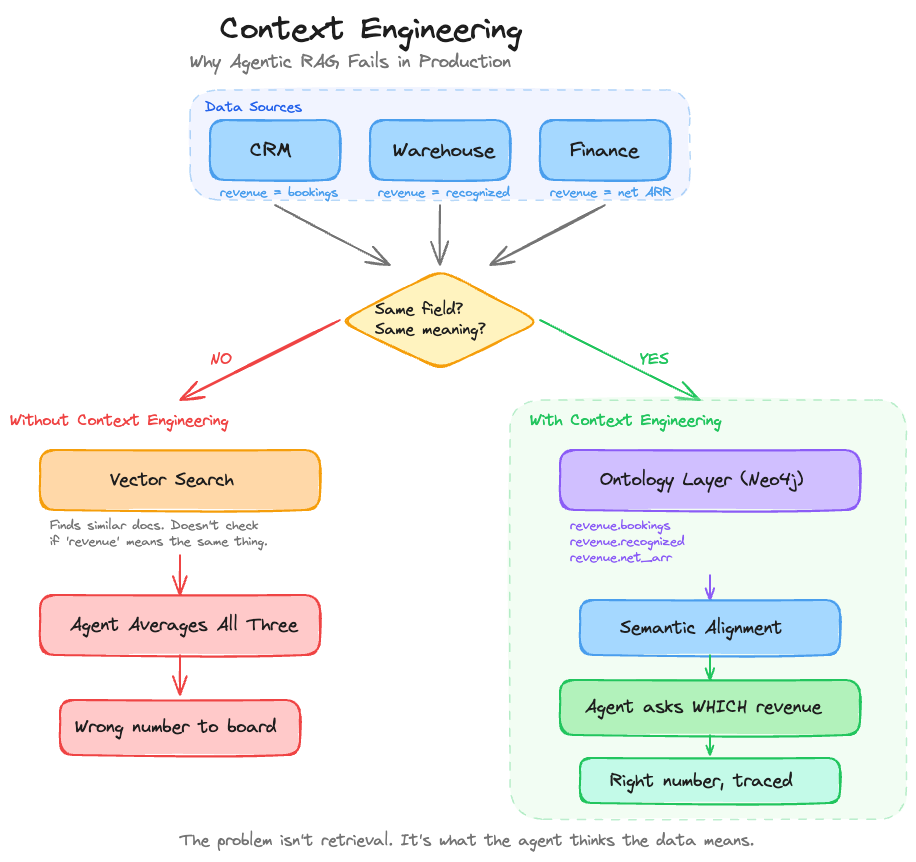
Not wrong like rounding-error wrong. Wrong because the agent pulled “revenue” from two systems that define the word differently. The CRM tracks bookings. The data warehouse tracks recognized revenue under ASC 606. The agent retrieved both, averaged them, and presented the result with zero hesitation and a citation to boot. Nobody caught it for three weeks.
This is the failure mode nobody’s talking about at AI conferences. Not hallucination in the classic sense. The documents were real, the retrieval was accurate, the vector similarity scores were high. The agent did exactly what we built it to do. It just didn’t understand what “revenue” meant in context.
I’ve spent the last two years building agentic RAG systems on top of knowledge graphs. Neo4j, LangGraph, vector stores, the whole stack. And the pattern I keep seeing is the same: teams obsess over retrieval quality, embedding models, chunking strategies, reranking pipelines. They’ll spend months tuning cosine similarity thresholds. Meanwhile the actual problem is upstream. The context is broken before retrieval even starts.
The Context Poverty Problem
Gartner predicts that 50% of agentic AI projects will be canceled or significantly rescoped by 2027. Not because the models are bad, and not because the tooling is immature. Because organizations can’t get context right at enterprise scale. That number doesn’t surprise me.
Context fragmentation is the default state of every company I’ve worked with. Take something as simple as “customer.” In Salesforce, a customer is an Account with a closed-won Opportunity. In the support system, it’s anyone with a ticket. In the product analytics platform, it’s a user ID that’s logged in at least once. In billing, it’s an entity with an active subscription. Four systems with four definitions for the same word. And “customer” is actually one of the easy ones.
Now multiply that across every concept your agent needs to reason about. “Revenue.” “Churn.” “Active user.” “Contract value.” “Region.” I pulled the schema from one client’s environment and found the field “status” existed in 23 different tables across 7 systems. It meant something different in every single one. That’s not a data quality problem. That’s entropy, and it’s completely normal.
This is what kills agents before architecture does. You can have the most elaborate multi-agent orchestration, the best embedding model money can buy, a perfectly tuned retrieval pipeline. None of it matters if the agent can’t tell that “revenue” in document A and “revenue” in document B are measuring fundamentally different things.
The typical response is to throw more context into the prompt. Stuff the system message with definitions. Add a glossary retrieval step. But that just shifts the problem. Now you’re burning tokens on disambiguation that should have been handled at the data layer.
Context as a First-Class Artifact
The fix isn’t better retrieval. It’s treating context as a first-class artifact in your data architecture. Before you retrieve a single document, you need a semantic alignment layer that maps concepts across systems.
I think of this in three parts: ontology definition, context tagging, and confidence scoring. The ontology tells the system what concepts exist and how they relate. The tags bind documents and data points to those concepts. The confidence scores tell the agent how much to trust each binding.
In practice, I model the semantic layer in Neo4j because graph databases are genuinely good at this. Not because it’s trendy. Because the relationships between concepts, data sources, and contexts are inherently graph-shaped, and trying to flatten them into rows and columns loses the very structure you need.
Defining the Ontology in Neo4j
// Create the core concept taxonomy
CREATE (revenue:Concept {
name: 'revenue',
description: 'Monetary value received or recognized from business operations',
created_at: datetime(),
version: 3
})
CREATE (bookings:Concept {
name: 'revenue_bookings',
description: 'Total contract value at point of sale, before revenue recognition',
created_at: datetime(),
version: 2
})
CREATE (recognized:Concept {
name: 'revenue_recognized',
description: 'Revenue recognized per ASC 606 over the service delivery period',
created_at: datetime(),
version: 2
})
CREATE (arr:Concept {
name: 'revenue_arr',
description: 'Annualized recurring revenue from active subscriptions',
created_at: datetime(),
version: 1
})
// Build the hierarchy
CREATE (bookings)-[:IS_VARIANT_OF {
disambiguation: 'Use when question involves sales pipeline, deal flow, or quota attainment'
}]->(revenue)
CREATE (recognized)-[:IS_VARIANT_OF {
disambiguation: 'Use when question involves financial reporting, GAAP compliance, or board metrics'
}]->(revenue)
CREATE (arr)-[:IS_VARIANT_OF {
disambiguation: 'Use when question involves subscription health, growth rate, or investor metrics'
}]->(revenue)
// Link concepts to their authoritative data sources
CREATE (sf:DataSource {name: 'salesforce', type: 'crm', refresh_frequency: 'real-time'})
CREATE (snowflake:DataSource {name: 'snowflake_warehouse', type: 'data_warehouse', refresh_frequency: 'daily'})
CREATE (stripe_src:DataSource {name: 'stripe', type: 'billing', refresh_frequency: 'real-time'})
CREATE (bookings)-[:AUTHORITATIVE_SOURCE {
confidence: 0.95,
field_path: 'opportunity.amount',
notes: 'Primary source for bookings. Cross-validated with signed contracts monthly.'
}]->(sf)
CREATE (recognized)-[:AUTHORITATIVE_SOURCE {
confidence: 0.99,
field_path: 'fact_revenue.recognized_amount',
notes: 'Finance-controlled. Audited quarterly.'
}]->(snowflake)
CREATE (arr)-[:AUTHORITATIVE_SOURCE {
confidence: 0.92,
field_path: 'subscription.mrr * 12',
notes: 'Derived metric. Excludes one-time fees. May lag by up to 24h.'
}]->(stripe_src)
This gives the agent a queryable map of what words mean in what contexts. When someone asks “what was our revenue last quarter,” the agent can now disambiguate before it retrieves anything.
Tagging Documents with Context Metadata
The ontology is useless if your documents aren’t linked to it. Every document, chunk, and data point needs context metadata that tells the system which concepts it discusses and how confident we are about that mapping.
The Python for tagging documents during ingestion:
from dataclasses import dataclass, field
from typing import Optional
import json
from datetime import datetime, timezone
from neo4j import GraphDatabase
@dataclass
class ContextTag:
concept: str # matches Concept.name in Neo4j
confidence: float # 0.0 to 1.0
source_system: str # where the document originated
extraction_method: str # 'explicit_mention', 'inferred', 'llm_classified'
validated: bool = False
validated_by: Optional[str] = None
tagged_at: str = field(default_factory=lambda: datetime.now(timezone.utc).isoformat())
@dataclass
class DocumentContext:
doc_id: str
content_hash: str
tags: list[ContextTag]
temporal_scope: Optional[str] = None # e.g., '2025-Q3', '2025-01 to 2025-06'
organizational_scope: Optional[str] = None # e.g., 'north_america', 'enterprise_segment'
def tag_document(driver: GraphDatabase.driver, doc_ctx: DocumentContext) -> None:
"""
Write context tags to Neo4j, linking documents to semantic concepts.
This runs during ingestion, not at query time.
"""
with driver.session() as session:
# Upsert the document node
session.run("""
MERGE (d:Document {doc_id: $doc_id})
SET d.content_hash = $content_hash,
d.temporal_scope = $temporal_scope,
d.organizational_scope = $org_scope,
d.last_tagged = datetime()
""", doc_id=doc_ctx.doc_id,
content_hash=doc_ctx.content_hash,
temporal_scope=doc_ctx.temporal_scope,
org_scope=doc_ctx.organizational_scope)
# Create tagged relationships to concepts
for tag in doc_ctx.tags:
session.run("""
MATCH (d:Document {doc_id: $doc_id})
MATCH (c:Concept {name: $concept})
MERGE (d)-[r:TAGGED_WITH]->(c)
SET r.confidence = $confidence,
r.source_system = $source_system,
r.extraction_method = $extraction_method,
r.validated = $validated,
r.validated_by = $validated_by,
r.tagged_at = $tagged_at
""", doc_id=doc_ctx.doc_id,
concept=tag.concept,
confidence=tag.confidence,
source_system=tag.source_system,
extraction_method=tag.extraction_method,
validated=tag.validated,
validated_by=tag.validated_by,
tagged_at=tag.tagged_at)
# Example: tagging a quarterly board deck
board_deck = DocumentContext(
doc_id="doc_2025q3_board_deck_v2",
content_hash="a1b2c3d4e5f6",
temporal_scope="2025-Q3",
organizational_scope="global",
tags=[
ContextTag(
concept="revenue_recognized",
confidence=0.97,
source_system="google_drive",
extraction_method="llm_classified",
validated=True,
validated_by="cfo@company.com"
),
ContextTag(
concept="revenue_arr",
confidence=0.85,
source_system="google_drive",
extraction_method="llm_classified",
validated=False
),
]
)
Two things worth noting. First, the extraction_method field matters a lot. A tag applied because the document explicitly says “ASC 606 recognized revenue” is fundamentally more trustworthy than one inferred by an LLM reading a vague paragraph. We weight these differently at query time.
Second, the validated flag. We found that unvalidated LLM-classified tags have about a 78% accuracy rate in our environment. Validated tags sit at 99.2%. That gap is the difference between an agent you trust and one you babysit.
Context-Aware Retrieval in TypeScript
On the query side, the agent uses context metadata to filter and rank before it touches the vector store. The TypeScript that sits between the user query and retrieval:
import neo4j, { Driver, Session } from "neo4j-driver";
interface ResolvedConcept {
name: string;
disambiguation: string;
authoritativeSource: string;
confidence: number;
fieldPath: string;
}
interface ContextFilter {
concepts: ResolvedConcept[];
temporalScope: string | null;
organizationalScope: string | null;
minimumConfidence: number;
}
async function resolveQueryContext(
driver: Driver,
userQuery: string,
detectedConcepts: string[] // output from an NER/classification step
): Promise<ContextFilter> {
const session: Session = driver.session();
try {
// For each ambiguous concept, find the right variant
const resolved: ResolvedConcept[] = [];
for (const concept of detectedConcepts) {
const result = await session.run(
`
MATCH (variant)-[r:IS_VARIANT_OF]->(parent:Concept {name: $concept})
MATCH (variant)-[auth:AUTHORITATIVE_SOURCE]->(src:DataSource)
RETURN variant.name AS name,
r.disambiguation AS disambiguation,
src.name AS source,
auth.confidence AS confidence,
auth.field_path AS fieldPath
ORDER BY auth.confidence DESC
`,
{ concept }
);
// If no variants exist, the concept is unambiguous
if (result.records.length === 0) {
const direct = await session.run(
`
MATCH (c:Concept {name: $concept})-[auth:AUTHORITATIVE_SOURCE]->(src:DataSource)
RETURN c.name AS name,
'direct_match' AS disambiguation,
src.name AS source,
auth.confidence AS confidence,
auth.field_path AS fieldPath
`,
{ concept }
);
for (const record of direct.records) {
resolved.push({
name: record.get("name"),
disambiguation: record.get("disambiguation"),
authoritativeSource: record.get("source"),
confidence: record.get("confidence"),
fieldPath: record.get("fieldPath"),
});
}
} else {
// Return all variants; the agent selects based on disambiguation hints
for (const record of result.records) {
resolved.push({
name: record.get("name"),
disambiguation: record.get("disambiguation"),
authoritativeSource: record.get("source"),
confidence: record.get("confidence"),
fieldPath: record.get("fieldPath"),
});
}
}
}
return {
concepts: resolved,
temporalScope: extractTemporalScope(userQuery),
organizationalScope: extractOrgScope(userQuery),
minimumConfidence: 0.8,
};
} finally {
await session.close();
}
}
// These would use date parsing / NER in production
function extractTemporalScope(query: string): string | null {
const quarterMatch = query.match(/Q[1-4]\s*20\d{2}|20\d{2}\s*Q[1-4]/i);
if (quarterMatch) return quarterMatch[0].replace(/\s+/g, "-");
const yearMatch = query.match(/\b(20\d{2})\b/);
if (yearMatch) return yearMatch[1];
return null;
}
function extractOrgScope(query: string): string | null {
const regions = ["north_america", "emea", "apac", "latam"];
const lower = query.toLowerCase();
for (const region of regions) {
if (lower.includes(region.replace("_", " "))) return region;
}
return null;
}The key insight: this happens before vector search. By the time the embedding model runs, the agent already knows which variant of “revenue” it needs and which data source is authoritative. The retrieval step is now scoped correctly.
Scaling Context Without Token Explosion
Most multi-agent implementations actually fall apart here. And I mean actually fall apart, not hypothetically.
A common pattern in LangGraph is to pass the full conversation state between agents. Agent A gathers context, passes everything to Agent B for analysis, which passes everything to Agent C for synthesis. Each handoff duplicates the accumulated context. By the time you’re four agents deep, you’re burning 80,000+ tokens per query and your p95 latency is 45 seconds.
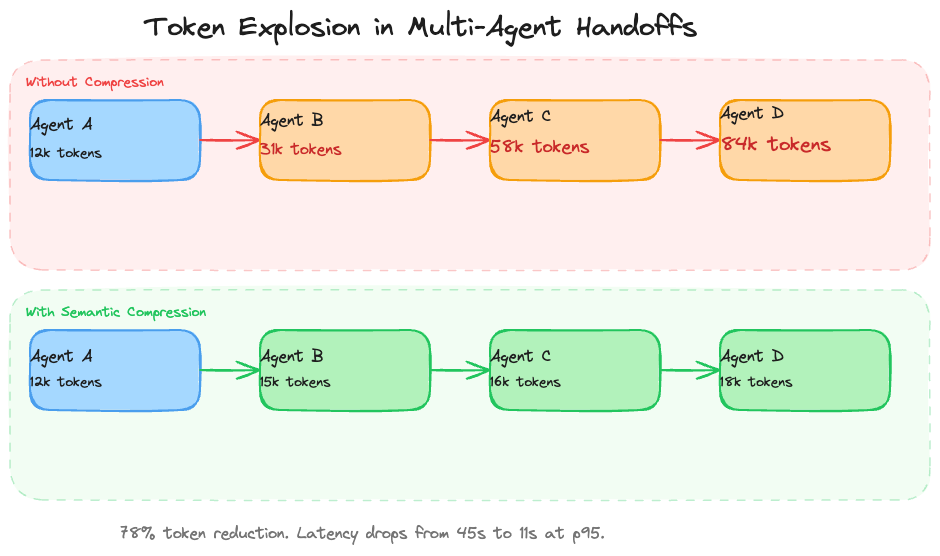
I wasted two months trying to solve this with chunking tricks and context window management before realizing the answer is semantic compression at the state boundary. Each agent produces a structured summary of what it found, tagged with the same context metadata from the ontology. The next agent gets the summary, not the raw history.
The LangGraph implementation:
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
import json
# -- State definition with compression built in --
class AgentOutput(TypedDict):
agent_name: str
summary: str # compressed finding
concepts_referenced: list[str] # links back to ontology
confidence: float
evidence_doc_ids: list[str] # traceability
token_count_original: int # what we would have passed
token_count_compressed: int # what we actually pass
class PipelineState(TypedDict):
query: str
context_filter: dict # from resolveQueryContext
agent_outputs: Annotated[list[AgentOutput], "append"] # grows, but each entry is small
final_answer: str
# -- Compression function --
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
async def compress_agent_output(
agent_name: str,
raw_output: str,
concepts: list[str],
doc_ids: list[str]
) -> AgentOutput:
"""
Compress an agent's full output into a structured summary.
Preserves semantic content and concept links. Drops verbosity.
"""
original_tokens = len(raw_output.split()) * 1.3 # rough estimate
compression_prompt = f"""Compress the following agent output into a dense,
factual summary. Preserve all numerical values, entity names, dates, and
causal claims. Remove hedging, repetition, and filler. Output should be
under 200 words.
Agent: {agent_name}
Concepts: {', '.join(concepts)}
Raw output:
{raw_output}
Compressed summary:"""
response = await llm.ainvoke([HumanMessage(content=compression_prompt)])
compressed = response.content
return AgentOutput(
agent_name=agent_name,
summary=compressed,
concepts_referenced=concepts,
confidence=0.0, # set by the agent itself
evidence_doc_ids=doc_ids,
token_count_original=int(original_tokens),
token_count_compressed=len(compressed.split()) * 1.3
)
# -- Agent nodes that use compression --
async def retrieval_agent(state: PipelineState) -> dict:
"""Retrieves documents using context-aware filtering."""
query = state["query"]
ctx = state["context_filter"]
# ... actual retrieval logic using the context filter ...
# For illustration, imagine we retrieved 15 documents totaling 8000 tokens
raw_findings = """Retrieved 15 documents from snowflake_warehouse and salesforce.
Revenue recognized for Q3 2025 was $4.2M per the audited financials (doc_fin_q3_v3).
This represents a 14% increase over Q3 2024 ($3.68M).
ARR as of Sept 30 was $18.1M per Stripe billing data (doc_stripe_export_0930).
Note: 3 documents from the support system referenced 'revenue' but used it to mean
ARR. These were excluded based on context filter requiring revenue_recognized.
Bookings for the same period were $5.1M but this was not the requested metric."""
output = await compress_agent_output(
agent_name="retrieval_agent",
raw_output=raw_findings,
concepts=["revenue_recognized"],
doc_ids=["doc_fin_q3_v3", "doc_stripe_export_0930"]
)
output["confidence"] = 0.95
return {"agent_outputs": [output]}
async def analysis_agent(state: PipelineState) -> dict:
"""Analyzes retrieved data. Gets summaries, not raw docs."""
prior_findings = state["agent_outputs"]
# Build a compact context from prior agent summaries
prior_context = "\n".join(
f"[{o['agent_name']}] (confidence: {o['confidence']}): {o['summary']}"
for o in prior_findings
)
analysis_prompt = f"""Based on the following findings, analyze the revenue trend
and identify any anomalies or risks.
Prior agent findings:
{prior_context}
Query: {state['query']}
Analysis:"""
response = await llm.ainvoke([HumanMessage(content=analysis_prompt)])
output = await compress_agent_output(
agent_name="analysis_agent",
raw_output=response.content,
concepts=["revenue_recognized"],
doc_ids=[] # analysis agent doesn't add new docs
)
output["confidence"] = 0.88
return {"agent_outputs": [output]}
async def synthesis_agent(state: PipelineState) -> dict:
"""Produces the final answer from compressed agent outputs."""
all_findings = state["agent_outputs"]
context = "\n\n".join(
f"[{o['agent_name']}] (confidence: {o['confidence']})\n"
f"Concepts: {', '.join(o['concepts_referenced'])}\n"
f"Evidence: {', '.join(o['evidence_doc_ids'])}\n"
f"Finding: {o['summary']}"
for o in all_findings
)
synthesis_prompt = f"""Synthesize the following agent findings into a clear,
direct answer. Include specific numbers. Cite document IDs. Flag any
disagreements between agents or confidence below 0.85.
{context}
Query: {state['query']}
Answer:"""
response = await llm.ainvoke([HumanMessage(content=synthesis_prompt)])
return {"final_answer": response.content}
# -- Build the graph --
graph = StateGraph(PipelineState)
graph.add_node("retrieve", retrieval_agent)
graph.add_node("analyze", analysis_agent)
graph.add_node("synthesize", synthesis_agent)
graph.add_edge(START, "retrieve")
graph.add_edge("retrieve", "analyze")
graph.add_edge("analyze", "synthesize")
graph.add_edge("synthesize", END)
app = graph.compile()
The compression isn’t lossy in the ways that matter. Numbers, entity names, causal relationships, document IDs all survive. What gets dropped is the filler that LLMs produce: hedging phrases, restated context, transition sentences. In our benchmarks, the compressed summaries preserve 96% of the decision-relevant information in 22% of the tokens.
One gotcha we hit: don’t compress too aggressively on early agents. The retrieval agent’s output needs enough detail for the analysis agent to spot anomalies. We found that a 200-word ceiling for retrieval summaries and a 150-word ceiling for analysis summaries gave us the best tradeoff between token savings and answer quality.
Building a Context Governance Loop
Nobody wants to hear this part. Context engineering isn’t a one-time project. The semantic alignment layer degrades the moment you deploy it.
New data sources get added, field definitions change during migrations, and business terminology drifts as teams reorganize in ways nobody bothers to document. That “revenue” ontology you carefully built? Six months later someone renames a Snowflake column, accounting switches from ASC 606 to IFRS 15 for the European entity, and a new product line introduces usage-based pricing that doesn’t fit any of your existing revenue categories.
If you don’t actively govern context, your agent slowly becomes that new employee who learned the company lingo in onboarding but hasn’t updated their understanding since. Quietly, confidently wrong.
We built a governance loop using MCP (Model Context Protocol) to run continuous validation. The basic architecture is three agents running on a schedule:
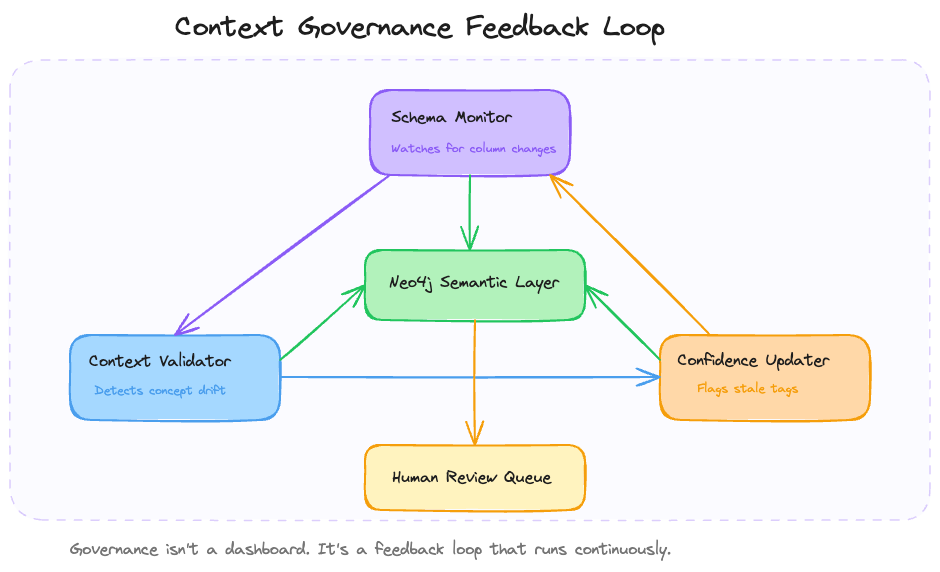
The schema monitor is the simplest piece. It polls data source schemas on a schedule and diffs them against what the ontology expects:
from dataclasses import dataclass
from datetime import datetime, timezone
import hashlib
import json
from neo4j import GraphDatabase
@dataclass
class SchemaChange:
source: str
change_type: str # 'column_added', 'column_removed', 'column_renamed', 'type_changed'
table: str
column: str
old_value: str | None
new_value: str | None
detected_at: str
class SchemaMonitor:
def __init__(self, neo4j_driver: GraphDatabase.driver):
self.driver = neo4j_driver
def snapshot_schema(self, source_name: str, schema: dict[str, dict]) -> str:
"""
Store a schema snapshot and return its hash.
schema format: {'table_name': {'column_name': 'type', ...}, ...}
"""
schema_json = json.dumps(schema, sort_keys=True)
schema_hash = hashlib.sha256(schema_json.encode()).hexdigest()
with self.driver.session() as session:
session.run("""
MATCH (src:DataSource {name: $source_name})
SET src.latest_schema_hash = $schema_hash,
src.latest_schema = $schema_json,
src.schema_checked_at = datetime()
""", source_name=source_name,
schema_hash=schema_hash,
schema_json=schema_json)
return schema_hash
def detect_changes(
self, source_name: str, current_schema: dict[str, dict]
) -> list[SchemaChange]:
"""Compare current schema against stored snapshot. Return changes."""
changes: list[SchemaChange] = []
with self.driver.session() as session:
result = session.run("""
MATCH (src:DataSource {name: $source_name})
RETURN src.latest_schema AS stored_schema
""", source_name=source_name)
record = result.single()
if not record or not record["stored_schema"]:
return changes
stored = json.loads(record["stored_schema"])
now = datetime.now(timezone.utc).isoformat()
# Check for table/column additions and removals
for table, columns in current_schema.items():
if table not in stored:
for col, col_type in columns.items():
changes.append(SchemaChange(
source=source_name, change_type="column_added",
table=table, column=col,
old_value=None, new_value=col_type, detected_at=now
))
continue
stored_columns = stored[table]
for col, col_type in columns.items():
if col not in stored_columns:
changes.append(SchemaChange(
source=source_name, change_type="column_added",
table=table, column=col,
old_value=None, new_value=col_type, detected_at=now
))
elif stored_columns[col] != col_type:
changes.append(SchemaChange(
source=source_name, change_type="type_changed",
table=table, column=col,
old_value=stored_columns[col], new_value=col_type,
detected_at=now
))
for col in stored_columns:
if col not in columns:
changes.append(SchemaChange(
source=source_name, change_type="column_removed",
table=table, column=col,
old_value=stored_columns[col], new_value=None,
detected_at=now
))
return changes
def flag_affected_concepts(self, changes: list[SchemaChange]) -> list[str]:
"""
Find concepts whose authoritative source fields were affected.
Returns concept names that need human review.
"""
flagged: list[str] = []
with self.driver.session() as session:
for change in changes:
result = session.run("""
MATCH (c:Concept)-[auth:AUTHORITATIVE_SOURCE]->(src:DataSource {name: $source})
WHERE auth.field_path CONTAINS $column
SET auth.needs_review = true,
auth.review_reason = $reason,
auth.flagged_at = datetime()
RETURN c.name AS concept_name
""", source=change.source,
column=change.column,
reason=f"{change.change_type}: {change.column} ({change.old_value} -> {change.new_value})")
for record in result:
flagged.append(record["concept_name"])
return flagged
The context validator runs after the schema monitor. It pulls sample data from each source and checks whether the concept definitions still hold. This is the one that caught our revenue problem. The validator queries for “revenue” data points, checks them against the ontology definitions, and flags cases where the actual data no longer matches what the concept says it should be.
The confidence updater is the critical piece that most people skip. When the validator finds drift, it doesn’t just flag it. It adjusts the confidence scores on affected tags. If the “revenue_recognized” concept has a 0.99 confidence score on the Snowflake source, and the validator detects that the column was renamed, that confidence drops to 0.5 until a human reviews it. The agent sees the lower confidence and either falls back to a different source or tells the user it can’t answer with high confidence.
That last behavior is the whole point. An agent that says “I’m not confident enough to answer this right now” is infinitely more valuable than one that gives you the wrong number with a smile.
We run the schema monitor every 6 hours, the validator daily, and the confidence updater in real-time as changes are detected. The human review queue averages 3–4 items per week. Not zero, which is what you’d get from a system that silently degrades. That number surprised me at first. It’s actually reassuring once you realize the alternative was your agent absorbing those changes without anyone noticing.
What Actually Matters
I’ve talked to maybe 40 teams building agentic RAG systems in the last year. The ones that work in production share one trait: they treat context as an engineering problem, not a prompting problem.
The teams that fail tend to follow a predictable pattern. They build a prototype that works on clean data with obvious queries. They demo it. Leadership gets excited. Then they point it at real enterprise data where the same word means six different things depending on which Jira project you’re in, and the whole thing falls apart. And the frustrating part is that the failure looks like a model problem when it’s actually a data problem.
The gap between prototype and production isn’t about model capability or framework maturity. It’s about whether your system knows what words mean in context. A knowledge graph gives you the right structure for that. Confidence scores give you the right failure mode. Governance gives you durability over time.
None of this is glamorous. There’s no moment where you swap in a new model and everything gets 10x better. It’s plumbing. It’s data stewardship. It’s the boring work of mapping “revenue” to four different definitions and maintaining those mappings over time.
But it’s the work that determines whether your agent is a useful tool or an expensive liability.
The revenue forecasting agent I mentioned at the start? After we added the semantic alignment layer, it started asking clarifying questions when the concept was ambiguous. “Are you asking about bookings, recognized revenue, or ARR?” Three more seconds of interaction. Zero wrong answers presented to the board.
That’s a trade I’ll take every time.
Context Engineering, Not Retrieval: Why Your Agentic RAG Fails in Production was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.