Everyone is talking about prompt engineering being dead. That is only half true. What replaced it is bigger, quieter, and a lot more interesting.
Where this term came from
In mid-2025, Andrej Karpathy posted something that spread fast. He said the skill that actually matters for building with LLMs is not writing better prompts. It is context engineering: carefully constructing the information that goes into the context window so the model has exactly what it needs to do a good job.
Around the same time, Tobi Lutke, CEO of Shopify, used the same phrase in an internal memo that went public. He described it as a core competency every engineer at Shopify would need going forward.
Two high-signal people, same term, same week. The AI community took notice. But most of the content that followed either watered it down to “write better prompts” or made it sound impossibly complex. Neither is right. Let us go deeper than the definition.
The chef analogy
Think of an LLM as a world-class chef. Extraordinarily skilled. Given the right ingredients, the right recipe, and the right context about who they are cooking for, they will produce something remarkable.
Prompt engineering is like writing the order on the ticket. “Make me a pasta. Something creamy.”
Context engineering is everything else. Stocking the kitchen before the chef even starts. Telling them who the guest is, what allergies they have, what the occasion is, and which tools are on the counter. The chef has the same skills either way. What changes is the world they are operating inside.
Prompt engineering is what you ask. Context engineering is what world you put the model inside.
When a model underperforms, the problem is almost never that the model is bad. It is that the model was given the wrong world to work inside. Context engineering is the discipline of fixing that.
The anatomy of a context window
What actually goes into a context window? It is not just “the prompt.” A well-engineered context window has five distinct layers, each managed deliberately.
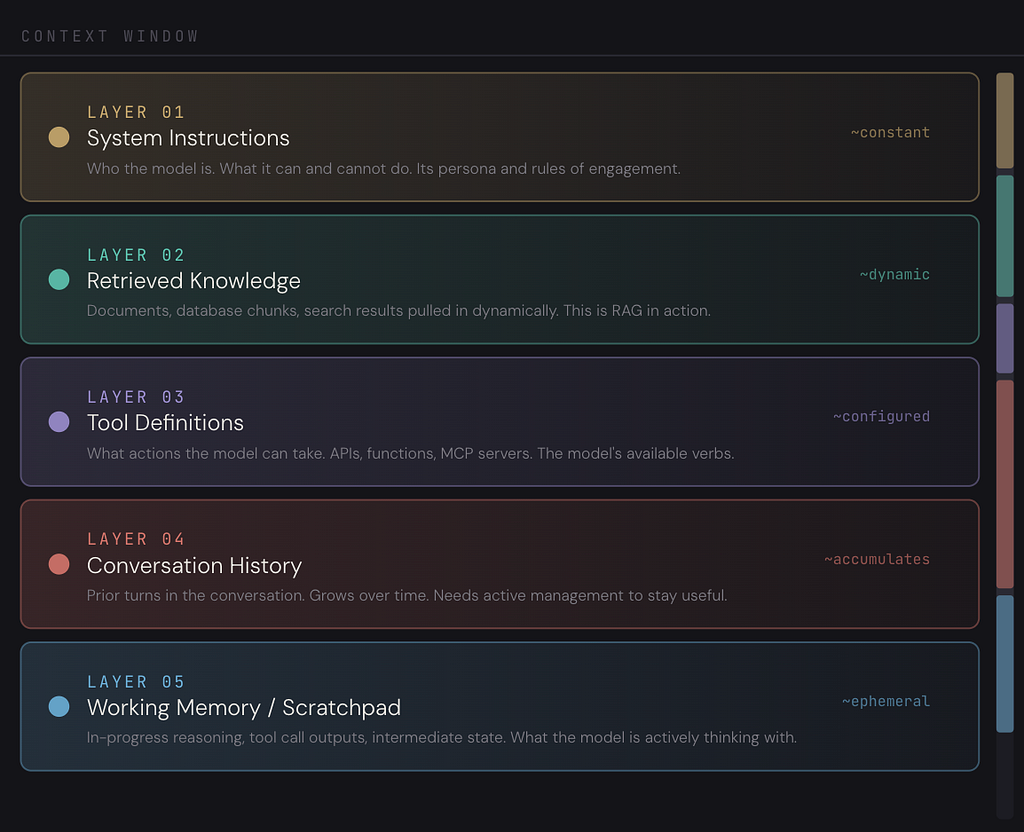
Every one of these layers is a design decision. You choose what goes in, how much space it takes, and how it gets updated over time. That is context engineering. Prompt engineering only ever touched Layer 04. Context engineering manages all five.
The techniques engineers actually use
Knowing the five layers is the vocabulary. Here is the grammar: the concrete techniques that determine whether a context window performs well or quietly degrades over time.
Layer 01: Instruction hygiene
Most system prompts are archaeology projects. Someone wrote 200 words in week one. A month later, someone added a new rule. Three months later, a bug fix appended three more paragraphs. Nobody deleted anything. Now you have a 3,000-token system prompt where section four contradicts section eight, the model is confused, and nobody can figure out why outputs are inconsistent.
Good instruction hygiene means treating your system prompt like production code: versioned, reviewed, and regularly pruned. Every sentence should be load-bearing. If you cannot say what a line does, remove it. Shorter, unambiguous instructions reliably outperform long, comprehensive ones because the model does not have to negotiate internal conflicts before generating a single word.
Layer 02: Surgical retrieval over document dumping
The naive RAG approach is to take a relevant document and paste the whole thing into the context. This is almost always wrong. A 20-page policy document probably has three paragraphs relevant to the current query. The other 19 pages are noise that buries the signal, eats your token budget, and degrades focus.
The technique is chunking with semantic awareness. Instead of fixed-size character splits, you split on natural boundaries: paragraphs, sections, logical units. Then you retrieve only the chunks that score highly against the query, not the whole document. A useful mental model: think of retrieval as search, not copy-paste. You are looking for the three paragraphs the model actually needs, not handing over the filing cabinet.
Layer 03: Dynamic tool scoping
When you give an agent access to tools, every tool definition consumes tokens and, more importantly, adds cognitive surface area. A model with 40 tools available will make worse decisions than one with 6. This is not a model capability problem. It is a context design problem.
The technique is dynamic scoping: load only the tools relevant to the current task or user intent. If the user is asking about their calendar, they do not need the code execution tool or the database write tool. Scoping tool definitions to the active context meaningfully improves accuracy and reduces both latency and cost.
Layer 04: Rolling history compression
Conversation history is the layer most likely to blow up your context budget. In a long agentic session, raw history accumulates fast. By turn 20, you may have consumed 40,000 tokens on back-and-forth that is no longer relevant to what the agent is doing right now.
The technique is rolling compression: instead of keeping full raw turns, periodically summarize older parts of the conversation into a compact narrative and replace them. The summary costs far fewer tokens than the original turns and preserves decision-relevant information without the filler. Some systems trigger this every N turns; others trigger it when context hits a threshold. Either way, the result is a window that stays lean across long sessions.
All layers: Placement-aware ordering
This one is counterintuitive. Research has consistently shown that LLMs recall information placed at the very beginning or the very end of a context window far better than information buried in the middle. The phenomenon even has a name: the “lost in the middle” problem.
The practical implication is that where you put information matters as much as whether you include it at all. The most critical facts and instructions should open or close the context, not sit in the middle of a long document dump. If you have retrieved five chunks, the one most relevant to the query should be placed last, sitting in high-attention territory. This is not a hack. It is working with how attention patterns in transformers actually behave.
What bad context engineering looks like
Theory absorbs better when you can see it fail. Here are three failure patterns that show up constantly in real AI systems. None of them are model problems. All of them are context problems.
Failure pattern 01: The degrading agent
You build a customer support agent. In testing, it works beautifully. After deploying it, users start reporting that it gives strange, circular, or contradictory answers in longer conversations. The model has not changed. What has changed is the context window.
By turn 15, raw conversation history is consuming most of the available tokens. Old turns that are no longer relevant, including early messages describing a problem that was already solved, are still sitting in context. The model tries to reconcile them with the current state of the conversation. It cannot. So it hedges, contradicts itself, and degrades.
The fix: Implement rolling history compression. Summarize resolved threads and drop them from raw context. The model only needs to know where the conversation currently is, not the full play-by-play of how it got there.
Failure pattern 02: The RAG system that still hallucinates
You build a RAG system over your company’s internal documentation. The documents are in there. The model has access. But it still makes up answers, gets details wrong, or says it does not have information when the answer is clearly in the knowledge base.
The problem is almost always retrieval quality, not model capability. The retrieval step is pulling the wrong chunks, or pulling the right document but burying the relevant passage inside a 5,000-token context dump. The model cannot reliably surface a fact that is sandwiched between 2,000 tokens of irrelevant prose on either side.
The fix: Move from naive chunking to semantic chunking. Retrieve fewer, more precise chunks. Place the most relevant one last in the context. Evaluate retrieval quality separately from generation quality. Most RAG failures live in Layer 02, not in the model.
Failure pattern 03: The haunted system prompt
A team builds an AI assistant over six months. Every time a new edge case appears, someone adds a rule to the system prompt to handle it. Every time the model does something wrong, a new instruction goes in to prevent it. Nobody ever deletes anything. By month six, the system prompt is 4,000 tokens long.
Buried in there are instructions that directly contradict each other. “Always be brief” sits two sections above “Always provide a full explanation.” “Do not ask clarifying questions” conflicts with “If the user seems confused, ask what they need.” The model tries to average across these constraints. The output is mush: neither brief nor thorough, inconsistent in personality, impossible to debug.
The fix: Audit the system prompt like a codebase. Every rule should have a reason. Conflicting rules should be resolved, not accumulated. A 400-token system prompt with no contradictions will outperform a 4,000-token one with internal conflicts almost every single time.
Why is this the real job now
If you have read the earlier pieces in this series, the connections here are hard to miss.
MCP is a context engineering tool. It is a standard for injecting tool definitions and external data into Layers 02 and 03 in a structured, reusable way. Connecting an MCP server to an agent is a context design decision.
Agent memory is context engineering applied over time. The four types of agent memory are all about what persists between context windows, what gets retrieved into the next one, and what gets discarded. Memory architecture is context architecture.
A2A protocols are about how agents share context with each other. When one agent hands a task off to another, what it is really doing is constructing a new context window for the receiving agent to work inside of.
The shift in one sentence
The job of an AI engineer used to be choosing the right model. Today it is designing the right context. The model is a given. The context is the craft.
The bottom line
Prompt engineering got us ChatGPT demos. You could impress someone in a meeting by writing a clever system prompt and watching the model perform. The demo worked because the context was simple: one turn, one task, a clean slate.
Production agents do not get clean slates. They run for hours, across dozens of turns, pulling from live data, using real tools, and maintaining state across tasks. Every one of the failure patterns above is invisible in a demo and devastating in production.
Context engineering is the discipline that bridges that gap. It is not glamorous. It does not involve fine-tuning weights or discovering new architectures. It is information architecture: deciding what goes in, where it goes, how much space it gets, and when it leaves. The engineers who get fluent in it early are the ones building things that actually hold up.
Context Engineering: Explained Simply was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.