Retrieval Augumented Generation boosts LLM by grounding them in external knowledge .Traditional RAG simply retrieves flat text chunk which often yields fragmented answers .REcent works add graph structure (GraphRAG ,LightGraph) to capture entity relations but these only model pairwise links. Cog-Rag instead simulates human “top-down” reasoning.It firsts identifies the global themes of a query and then recalls supporting details. Concretely , Cog-RAG builds a dual-hypergraph over the knowledge corpus : a theme hypergraph that captures inter-chunk narrative themes, and an an entity hypergraph that encodes fine-grained multi-entity relations within each chunk. Queries are processed in two stages: first matching theme keywords to retrieve relevant hyperedges (themes), then using those as “anchors” to guide a focused recall of entities. This theme-driven, detail-recall strategy enforces semantic alignment from global context down to specifics, improving coherence and reducing hallucinations.

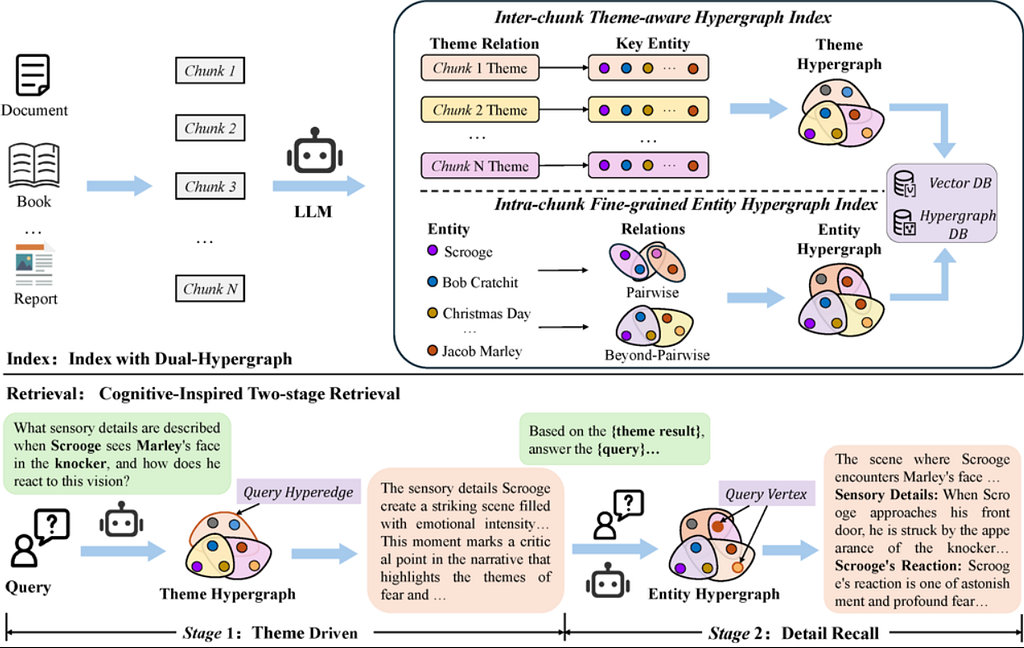
The theme hypergraph is built by splitting documents into overlapping chunks and using an LLM to extract each chunk’s latent theme and its key entities. Formally, each chunk (c_i) yields a theme hyperedge (h_i) whose nodes are the theme-related entities. In practice the code in cograg prompts a base LLM (e.g. GPT-4o) to answer “What is the main theme?” for each chunk, and to list the entities associated with that theme. Those theme–entity groupings become hyperedges in the theme hypergraph. Separately, the entity hypergraph is built within each chunk to capture detailed semantics. For each chunk, the LLM extracts all mentioned entities (people, concepts, events, etc.) and then prompts for their pairwise and group relations. These relations become low-order (binary) and high-order (multi-entity) hyperedges linking the chunk’s entities. In this way the index encodes both global narrative structure (themes across chunks) and local semantic structure (entity relations within chunks).
Document Ingestion and Chunking
Cog-RAG begins by loading each input document and splitting it into overlapping chunks (using a fixed-size sliding window) to preserve semantic continuity. Each chunk (a few hundred words long) becomes the basic unit of knowledge in the system. In practice, the raw text of each chunk is stored (e.g. in a key-value store or file) for later retrieval, along with its position in the original document. This chunking ensures that subsequent processing (extraction, indexing, embedding) works on manageable pieces while maintaining context overlap between adjacent chunks.
Theme and Entity Extraction
For each chunk, Cog-RAG uses an LLM (via a prompt-based “semantic parsing” step) to identify the chunk’s latent theme and the key entities related to that theme. Specifically, a predefined “theme extraction” prompt is sent to the LLM with the chunk text; the LLM outputs a short theme label or summary of the chunk. It then extracts or lists the most important entities (people, concepts, objects, etc.) that are tied to that theme. In effect, each chunk yields: (1) a theme string and (2) a set of entity names relevant to that theme. These outputs become the semantic descriptors of the chunk.
For example, a chapter of A Christmas Carol might yield a theme like “Fearful Ghost Encounter” with key entities {Scrooge, Marley’s Ghost, chains, moaning sound}. These themes and entities serve as the nodes and hyperedges of Cog-RAG’s indexing structure.
Dual-Hypergraph Index Construction
Cog-RAG builds two complementary hypergraph indexes from the extracted themes and entities: a Theme Hypergraph (global structure) and an Entity Hypergraph (fine-grained detail). Both are stored in a hypergraph database (e.g. HypergraphDB), enabling graph queries and “diffusion” over the graph.
- Theme Hypergraph (Inter-Chunk Structure): Each chunk’s theme becomes a hyperedge in the theme hypergraph. The vertices of this hyperedge are the chunk’s key entities. In other words, for chunk cᵢ with theme Tᵢ and entities {e₁,…,eₖ=}, the theme hypergraph adds a hyperedge labeled Tᵢ connecting the entity vertices. This links all entities that share a common theme across chunks. Since themes capture high-level storyline or topic (e.g. “fear”, “Romanticism”), the theme hypergraph encodes the global narrative or thematic structure of the corpus. Each hyperedge carries metadata (its theme string and source chunk), and the graph supports queries like “which chunks relate to the theme X?”.
- Entity Hypergraph (Intra-Chunk Relations): Within each chunk, Cog-RAG also builds a fine-grained entity hypergraph. First, the same or a second LLM prompt extracts all relevant entities from the chunk text (not just theme-linked ones). These become the vertex set for that chunk’s subgraph. Then Cog-RAG prompts the LLM (or uses heuristics) to identify relations among entities: simple pairwise relations (edges connecting two entities) and higher-order relations (hyperedges connecting three or more entities that co-occur or interact). For example, in a chunk about a ghost encounter, there might be pairwise edges like (Scrooge–Ghost) and a hyperedge (Scrooge–Ghost–Chains) representing a multi-entity relation. All such intra-chunk relations form hyperedges in the entity hypergraph. The entity hypergraph thus models high-order semantic associations (beyond binary links) among entities. It is stored in the same hypergraph database, with each vertex labeled by the entity name and each hyperedge labeled by the relation type or context.
Together, the theme hypergraph captures “macro” cross-chunk coherence (themes linking entities across the corpus), while the entity hypergraph captures “micro” intra-chunk details (entity relationships within each chunk). This dual structure mirrors the human cognitive process of first identifying broad themes and then recalling details under those themes.
Embedding Generation and Vector Store
For retrieval, Cog-RAG also creates embedding vectors of the indexed elements. In practice, each theme hyperedge and each entity vertex (or even each chunk’s text) is encoded by an embedding model (e.g. an OpenAI text-embedding model). These embeddings are stored in a vector database (such as FAISS, Pinecone, or the NanoVectorDB used in the reference code). For example, the theme string “Fearful Ghost Encounter” or the text of its chunk can be embedded and indexed, and each entity name (e.g. “Scrooge”) has an embedding as well. This allows semantic similarity search over the hypergraph components. In Cog-RAG’s implementation, the theme hyperedges (identified by their theme text) are inserted into a vector DB; likewise, the entity vertices (identified by entity names or descriptions) are inserted into a vector DB. When a new document is ingested, its chunks’ themes and entities are upserted into the theme and entity vector indexes so future queries can match them.
Two-Stage Query Processing
At query time, Cog-RAG follows a “theme-first, detail-second” retrieval strategy. Given a natural-language query Q, the system proceeds as follows:
- Keyword Parsing: An LLM processes Q with a prompt to extract two sets of keywords: theme keywords (general concepts or topics in the query) and entity keywords (specific names or details). For example, Q = “What sensory details describe Marley’s face?” might yield theme keywords = {“sensory details”} and entity keywords = {“Marley”}.
- Stage 1 — Theme Hypergraph Retrieval: The theme keywords are used to query the theme hypergraph via the vector store. The system embeds the theme-keyword string(s) and performs a nearest-neighbor search against the theme-hyperedge embeddings. The top k matching hyperedges (themes) are retrieved. These hyperedges represent chunks whose themes best match the query’s concepts. For each retrieved theme hyperedge, Cog-RAG then performs a diffusion step: it collects all the entity vertices incident on that hyperedge (i.e. the chunk’s key entities) from the theme hypergraph. In effect, diffusion gathers the entities related to the activated themes. The set of retrieved hyperedges plus their incident entities form a theme-driven context. This context (including the text of the related chunks if needed) is passed to the LLM as “Stage 1 evidence,” and an initial answer is generated (often a thematic outline of the response).
- Stage 2 — Entity Hypergraph Retrieval: Next, the system refines the answer with entity-level details. Using the entity keywords from step 1, Cog-RAG embeds them and searches the entity hypergraph vertices. It retrieves the top m matching entity vertices (i.e. specific entities from the corpus) via the entity vector store. For each such entity, a second diffusion is performed: the hypergraph is queried for all hyperedges incident on that entity, and for each such hyperedge all its other vertices (entities) are gathered. This collects related entities and concepts surrounding the matched entities.
- Context Composition: The theme-driven context (from Stage 1) and the fine-grained entity context (from Stage 2) are combined. All retrieved themes, entities, and their associated text contexts form the final “context window.” This enriched, structured context is fed into the LLM as evidence and instructions, along with the original query. The LLM then generates the final answer. Critically, Stage 2 is “theme-aligned” by design: it uses the Stage 1 themes to guide which entities are brought in, ensuring the detailed answer stays on-topic.
Each stage produces intermediate results: Stage 1 yields an initial theme-guided answer, and Stage 2 refines it into a detailed final answer. The “diffusion” steps in each stage ensure that related nodes in the hypergraphs are included, mimicking human associative reasoning. Throughout this process, the vector database enables semantic matching of keywords to themes/entities, and the hypergraph database provides the graph structure for diffusion and neighbor lookups.
Answer Generation (LLM Phase)
After retrieval, Cog-RAG calls a generative LLM (e.g. GPT-4 or a local LLM) with a prompt that includes the composed context from both stages. The context may consist of retrieved sentences or summaries from chunks, along with signals about the activated themes and entities. The LLM uses this evidence to produce a coherent answer to the query. Because the context was gathered in a structured, theme-aligned way, the answer is more coherent and fact-based. In formula form (from the paper): the final answer A is generated by LLM from the query Q, the set of Stage-2 entities V_e, their diffusion neighbors V’, and the Stage-1 theme context C:
Answer = LLM(Q; ThemesContext, EntitiesContext, DiffusedContext)
Thus Cog-RAG’s generation is fully “retrieval-augmented”: no generation occurs before the retrieval.
Data/Compute Flow
Putting it all together, a high-level data flow is:
Document → Chunks → (LLM parsing) → Theme/Entity data → Dual-Hypergraph indices + Vector indices
.At query time:
Query → (LLM parsing) → Theme/Entity keywords → Vector search (themes, then entities) → Hypergraph diffusion → Context assembly → LLM answer.
The cograg GitHub repository provides a ready-to-use implementation of this framework. It is written in Python (3.10+) and integrates with any LLM or embedding model via user-provided functions. Core components include the CogRAG class (main interface), QueryParam (to configure modes like "cog" for two-stage retrieval), and EmbeddingFunc (wrapper for embedding API). Under the hood, prompt.py defines the LLM prompts for extracting themes, entities, and keywords, while operate.py orchestrates indexing/retrieval and storage.py manages the hypergraph database (storing embeddings and adjacency lists). In practice one initializes CogRAG with an LLM function and an embedding function, then inserts documents and queries. For example, using OpenAI’s GPT-4o and embeddings one might do:
from cograg import CogRAG, QueryParam
from cograg.utils import EmbeddingFunc
import openai, os
# Initialize Cog-RAG with OpenAI LLM and embeddings
llm_model = lambda prompt: openai.ChatCompletion.create(
model="gpt-4o-mini", messages=[{"role":"user","content": prompt}],
temperature=0.7, api_key=os.getenv("OPENAI_API_KEY")
).choices[0].message.content
emb_model = openai.Embedding.create # wrapper to generate embeddings
rag = CogRAG(
working_dir="./rag_cache",
llm_model_func=llm_model,
embedding_func=EmbeddingFunc(
embedding_dim=1536,
max_token_size=8192,
func=lambda texts: emb_model(input=texts, model="text-embedding-3-small", api_key=os.getenv("OPENAI_API_KEY"))["data"]
),
)
rag.insert("Your document content here. This could be multiple paragraphs or files.")
response = rag.query(
query="Summarize the main themes and details.",
param=QueryParam(mode="cog") # two-stage theme-entity retrieval
)
print(response) # expects the answer structured by Cog-RAG
In this code, the LLM and embedding functions are wrapped to match CogRAG’s API. Error handling (not shown) should catch API failures and retry as needed. The rag.insert(...) call runs the hypergraph indexing: splitting text into chunks, extracting themes/entities via LLM calls, and building the internal indices. The rag.query(...) call then executes the cognitive retrieval pipeline.
To integrate CogRAG with LangChain, one can wrap it as a custom Retriever or Chain. For example, you could subclass langchain.retrievers.BaseRetriever to call rag.query() under the hood:
from langchain.retrievers.base import BaseRetriever
from langchain.schema import Document
class CogRAGRetriever(BaseRetriever):
"""LangChain retriever wrapping a CogRAG instance."""
def __init__(self, cograg):
self.cograg = cograg
def get_relevant_documents(self, query):
result = self.cograg.query(query=query, param=QueryParam(mode="cog"))
answer = result.get("answer", "")
return [Document(page_content=answer)]
This CogRAGRetriever can then be plugged into a LangChain RetrievalQA or used in an agent. For instance, RetrievalQA.from_chain_type(llm=OpenAI(), retriever=CogRAGRetriever(rag)) would route queries through CogRAG before generating the final answer. In this way, CogRAG serves as the retrieval component in a LangChain pipeline, providing enriched context that is then fed to the LLM for answer generation.
In summary, Cog-RAG represents a significant advance in RAG architecture. By modeling corpus knowledge as a theme-driven hypergraph and mimicking top-down cognition, it aligns global and local semantics. Empirically, Cog-RAG “consistently outperforms all baselines”. In dense, domain-specific benchmarks (e.g. medical QA), it improves over the previous Hyper-RAG by over 20%. These gains come at the cost of more complex indexing (extra LLM calls to build hypergraphs) and storage (maintaining two graph structures). In production, best practices would include: batching and parallelizing LLM calls during index build, caching embeddings/hyperedges, monitoring retrieval latencies, and securing API keys (e.g. via environment variables). One should also consider the choice of embedding model and vector store for scalability and cost.
Trade-offs: Cog-RAG’s dual-hypergraph yields richer retrieval but requires careful tuning of hyperparameters (chunk size, top-k, diffusion breadth) and more compute for index creation. It works best when documents have coherent structure; in weakly structured or open-domain corpora, theme extraction may be noisy. Best practices include validating the theme/entity extraction prompts on sample data, and possibly filtering low-confidence extractions. For security, avoid leaking sensitive content in LLM prompts and enforce access controls on the vector DB. Overall, Cog-RAG’s code is modular and production-ready (with async support and logging), and it can be readily updated as new LLMs or vector stores emerge. When integrated in a LangChain pipeline, it provides a principled, hierarchical retrieval layer that can dramatically improve answer quality, especially for complex queries.
Cog-RAG: Cognitive-Inspired Dual-Hypergraph RAG was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.