
1. Introduction: Why Multi-Cloud Became Inevitable
The enterprise data platform supported multiple regions and distinct business units. Data workloads were distributed across geographically separated operating environments. The initial platform strategy assumed a single cloud provider would be sufficient. This assumption broke down as regional, regulatory and commercial constraints increased. Vendor concentration created operational and commercial risk at scale. Data residency requirements prevented certain datasets from leaving specific jurisdictions.
Figure 1: High-level architecture diagram
Mergers and acquisitions introduced platforms already committed to different cloud providers. Long-term legacy contracts limited the ability to fully standardise infrastructure. Multi-cloud adoption emerged as a response to these constraints and not architectural ambition. The decision was owned at the platform leadership level with clear accountability for outcomes.
2. Enterprise Context and Operating Constraints
Operation of the data platform was across multiple cloud providers including AWS, Azure and GCP. Each cloud environment supported different business units and regional workloads. Dozens of data pipelines powered both operational processes and analytical reporting. Pipelines handled continuous data ingestion as well as scheduled batch workloads. There were significant volumes of data which moved between environments on a recurring basis.
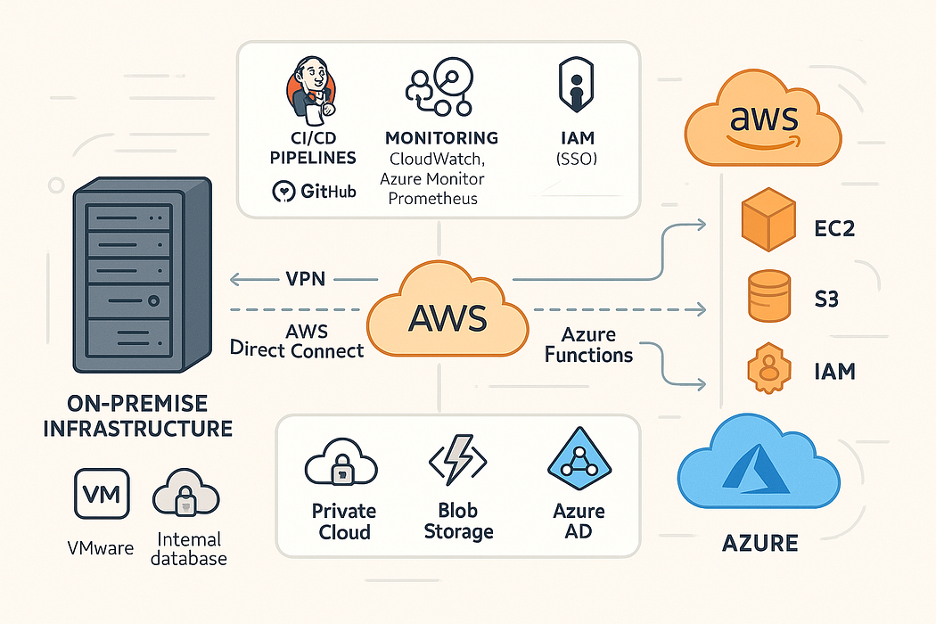
Figure 2: Enterprise context
Strict latency and availability SLAs governed business-critical workloads. Cloud spending was monitored closely, with enforced cost controls across providers. Security models differed between platforms and thus required careful alignment. Identity and access management needed to function consistently across clouds. Engineering teams operated at varying levels of cloud and data platform maturity. Architectural decisions balanced reliability, cost, security and delivery velocity.
3. Why “One Platform Everywhere” Did Not Work
Initial strategy aimed to standardise data tooling across all cloud platforms. A single platform was expected to simplify operations and reduce cognitive load. In practice feature parity varied significantly between cloud providers. Certain services performed well in one cloud but poorly in others. Performance tuning required cloud-specific expertise despite shared tooling. Operational overhead increased due to platform-specific workarounds.
Forced uniformity obscured platform strengths and weaknesses. Complexity shifted rather than being reduced. The approach limited teams’ ability to respond to local constraints. The strategy was reassessed based on operational evidence. Interoperability was prioritised over strict standardisation across environments.
4. Architectural Principles That Scaled
Architecture was designed around cloud-agnostic data contracts rather than shared infrastructure. Data producers and consumers interacted through well-defined schemas and interfaces. This reduced direct dependencies between teams and cloud platforms. Ingestion, processing and consumption layers were intentionally loosely coupled. Failures in one layer did not automatically propagate to others. Control plane responsibilities were separated from the data plane.

Figure 3: Data control management
Orchestration, metadata and governance logic were centralised where possible. Data processing remained local to each cloud environment. Open data formats such as Parquet and Delta Lake were used as standards. These formats enabled portability and reduced vendor lock-in. Principles applied simplified change management across platforms. Overall system resilience improved as architectural coupling decreased.
5. Data Movement, Cost, and Reliability Trade-offs
Cross-cloud data transfer was treated as an exception rather than the default. Data was processed as close as possible to where it was ingested. With this approach there was reduced latency and unnecessary egress costs were avoided. Cost visibility differed significantly across cloud providers. Comparable workloads produced different cost profiles in each environment. Network boundaries introduced new reliability failure modes. Transient connectivity issues affected pipeline stability. Retry strategies were implemented to handle temporary failures safely. Buffering mechanisms reduced the impact of downstream outages. Observability was improved through consistent logging and monitoring. These controls reduced operational risk without over-engineering solutions.
Figure 4: Data storage architecture
6. Governance, Security and Ownership Across Clouds
Consistent data governance standards were enforced across all cloud environments. Cloud-native tooling differences required abstraction at the policy level. Governance rules were defined centrally and implemented locally. Aligning identity and access management across providers was a significant challenge. Access controls had to remain consistent despite different security models. Clear ownership was assigned for every pipeline and dataset.

Figure 5: How real-time context feeds inform a central policy engine
Ownership included accountability for quality, cost and availability. Auditing requirements applied equally across distributed platforms. End-to-end lineage was established across cloud boundaries where possible. Measures that were put in place increased confidence in data handling and compliance. Trust in the platform improved among technical and non-technical stakeholders.
7. Outcomes: What Improved and What Didn’t
Platform resilience improved through reduced reliance on a single cloud provider. Vendor dependency risk was materially lowered at the platform level. Newly acquired systems were integrated more quickly into the data estate. Teams avoided forced migrations that would have disrupted business operations. Operational complexity increased due to additional platforms and tooling. Support and troubleshooting required broader skill sets. Some efficiency was traded for increased flexibility and resilience. Trade-offs such as these were accepted as necessary for long-term stability.
8. What I’d Do Differently Next Time
Data contracts would be defined and agreed earlier across all platforms. Schema ownership would be clarified before scaling pipeline development. Cross-cloud observability would be prioritised from the outset. Monitoring and alerting were initially fragmented across providers. Earlier investment would have reduced blind spots during incidents. Cost ownership would be made explicit at the team and domain level. Teams would be accountable for cross-cloud spend decisions. Changes like these would have improved control without reducing flexibility.
9. Conclusion: Multi-Cloud Is an Operating Model, Not a Pattern
Multi-cloud is an operating model rather than a reusable architecture pattern. Success depended more on discipline than on specific tooling choices. Architectural clarity proved more important than platform uniformity. Clear boundaries reduced unnecessary coupling between cloud environments. Optionality was treated as a strategic goal, not an engineering luxury. Complexity was introduced only where it delivered measurable resilience. Trade-offs were evaluated continuously rather than assumed upfront. Multi-cloud enabled flexibility while requiring stronger governance. Long-term value came from intent and execution but not platform count.
References
Aaniket P., 2025. A guide to the Multicloud Strategies of AWS, Azure, and Google Cloud. https://content.techgig.com/career-advice/mastering-multicloud-strategies-a-deep-dive-into-aws-azure-and-google-cloud/articleshow/123634580.cms
Eric B., 2022. Data, Control, Management: Three Planes, Different Altitudes. https://thenewstack.io/data-control-management-three-planes-different-altitudes/
Ismail K., 2025. Hybrid Cloud Architecture Explained: Why It’s the Future of Enterprise IT. https://medium.com/@ismailkovvuru/hybrid-cloud-architecture-explained-why-its-the-future-of-enterprise-it-b0a977fa05f7
Zhu, Y., Wang, H., Hu, Z., Ahn, G.J., Hu, H. and Yau, S.S., 2025, October. Efficient provable data possession for hybrid clouds. In Proceedings of the 17th ACM conference on Computer and communications security (pp. 756–758). https://www.researchgate.net/figure/Cloud-data-storage-architecture-for-hybrid-clouds_fig1_242538412
Coston, I., Hezel, K.D., Plotnizky, E. and Nojoumian, M., 2025. Enhancing secure software development with AZTRM-D: An AI-integrated approach combining DevSecOps, risk management, and zero trust. Applied Sciences, 15(15), p.8163. https://www.mdpi.com/2076-3417/15/15/8163
Follow me on LinkedIn:
Building Multi-Cloud Architectures was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.