Remember my essay back in August with Nathan Hamiel LLM + Coding Agents = Security Nightmare?
We were not wrong.
A new study from researchers from Stanford, MIT CSAIL, Carnegie Mellon, ITU Copenhagen, and NVIDIA and Elloe AI Labs, examining 847 autonomous agent deployments drawn from healthcare, finance, customer service and code-generation, showed that 91% were vulnerable to subtle but dangerous tool-chaining attacks (see diagram below),

Additionally, in the new study 89.4% of agents showed drift relative to their goals after about 30 steps in their process, and 94% of agents with some form of memory-augmentation were vulnerable to poisoning attacks.
Importantly the new paper shows that agents are in many ways much more vulnerable than pure (“stateless”) LLMs, as discussed in a taxonomy they developed:
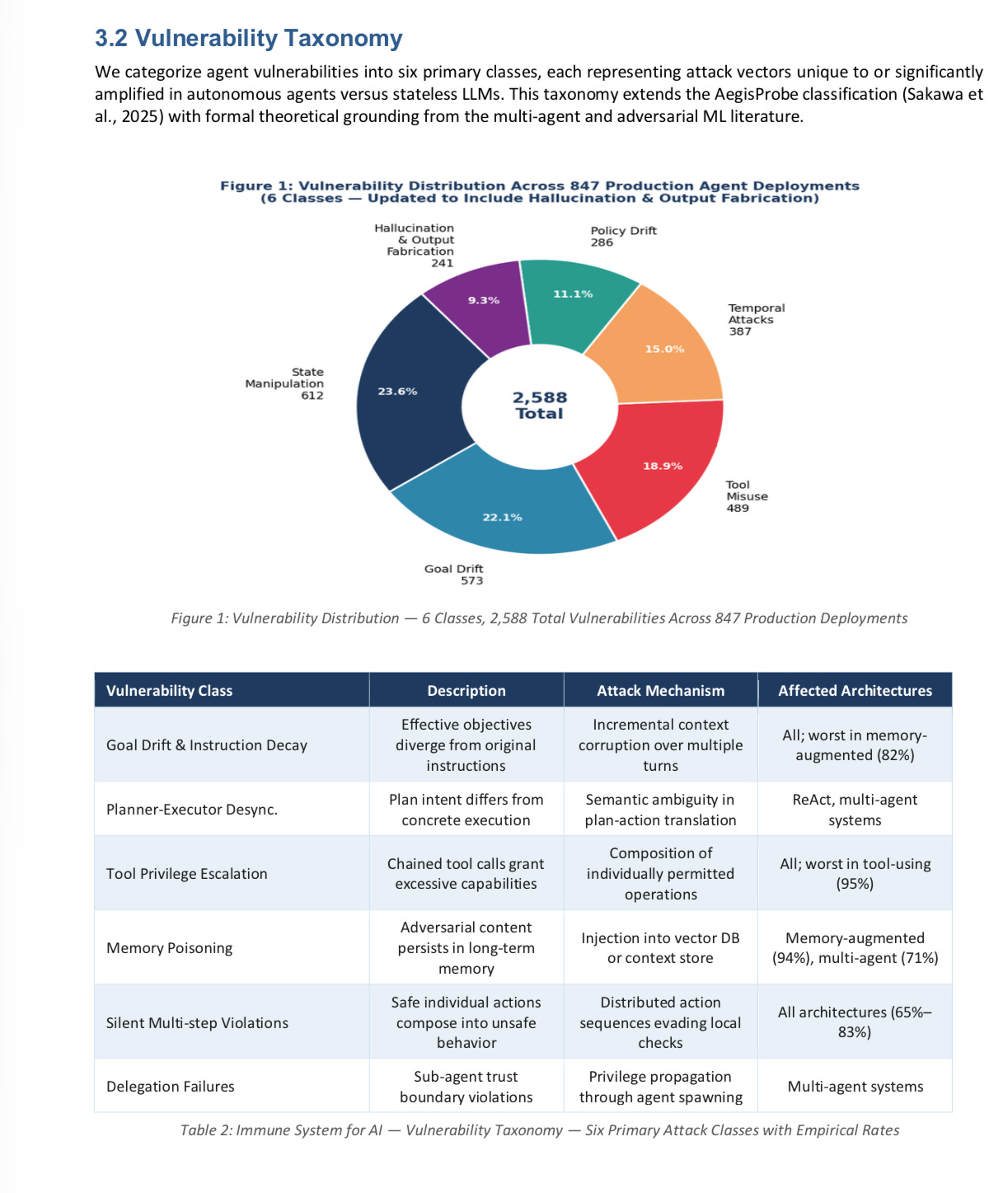
The new paper very much amplifies what a team of AWS and Berkeley researchers showed in February, documenting similar vulnerabilities:

As the newer paper’s first author, Owen Sakawa put it to me in an email “The OpenClaw / Moltbook incident (Section 9) is the first real-world empirical validation of the agentic threat model at scale: 770,000 live agents simultaneously compromised via a single database exploit, each with privileged access to their owner’s machine, email, and files. It’s not hypothetical anymore.”