This work was produced as part of the SPAR Program - Fall 2025 Cohort, with support from Georg Lange.
Kseniya Parkhamchuk, Jack Payne
TL;DR
Automated feature explanations from Delphi fail 38% of the time. The failures are sensitivity issues, output feature misidentification, factual incorrectness, and poor human readability. We built a tool-augmented agent to address these, enabling it to form hypotheses, run causal experiments, and iteratively refine explanations.
The agent's performance is on par with vanilla Delphi. No improvement, but no loss either. This raises the question of whether the agent is not good enough or whether there is some ceiling on what these scores can measure.
To test this, we had human expert mech interp researchers produce explanations using Neuronpedia with prompt testing and activation steering. They scored worse than both automated methods (58% vs 82% for the agent and 84% for Delphi). This is weak evidence that the ceiling is real, and that SAE feature quality (splitting, absorption, polysemanticity) may be the limiting factor rather than the explanation method.
We share the failure-mode taxonomy, the agent architecture, and the insights we accumulated along the way.
Introduction
Sparse autoencoders produce hundreds of thousands of features per layer. Delphi (EleutherAI's autointerpretability library) is the current standard for labelling them. It shows an LLM a set of activating examples, asks it to describe the pattern, and scores the result using detection (can the LLM predict which sentences activate?) and fuzzing (can it predict which tokens activate?).
We started by asking where Delphi fails. We manually evaluated the first 50 features from a Gemma-2 SAE and found that 38% of explanations fail in characterizable ways. Some are too broad or too narrow (sensitivity). Some describe input patterns when the feature is really about output prediction. Some are factually wrong. Some are technically correct but unreadable.
We then built an agent with tools to address these failure modes, giving it the ability to test hypotheses, steer the model, and iteratively refine. The agent matches Delphi's scores but doesn't beat them. Human experts, using the full Neuronpedia toolkit, score worse than both. This post covers what we found and what we think it means.
This post is an overview. The full report has the complete methodology, per-feature results, and scoring analysis.
Failure modes of non-agentic autointerp
What is Delphi?
Delphi is an auto-interpretability library developed by Eleuther AI to address the problem of interpreting SAE features. It allows collecting activations for a chosen model and SAE, feeding n activating examples to the defined LLM, obtaining explanations, and evaluating them by running detection and fuzzing scoring methods. Detection requires a model to predict whether the whole sentence activates the feature, given the interpretation. Fuzzing is similar, but on the level of individual tokens. The task asks the LLM to identify whether highlighted tokens across the given example activate the examined feature.
Considering that the Delphi pipeline and scoring methods are used in the industry and perceived as one of the reliable and working solutions, we used the explanations generated by Delphi as a baseline.
Defining the "correct" feature explanation
We pursue two primary objectives for feature explanations: correctness and human interpretability. The explanation is expected to meet the following criteria.
- Comprehensiveness. The explanation accounts for the majority of the feature's activations.
- Conciseness. The explanation is restricted to 1-2 brief sentences to maintain readability and support rapid iteration.
- Resilience to break testing. Edge cases and weaker activation patterns are taken into account when formulating the final explanation.
- Clear scope with well-defined boundaries.
- Being explicit about downstream effects. When there is a clear causal influence on the output, the explanation states this directly.
Identifying failure modes
To demonstrate the existing failure modes, we manually evaluated the first 50 features from google/gemma-scope-2b-pt-res SAE layer 20 against our 2 objectives (comprising 5 specific criteria). For each feature, we obtained both a Delphi-generated explanation and a human baseline explanation. Explanations failing any criterion were categorized into four failure types.
Analysis revealed that 19 out of 50 (38%) feature explanations failed to meet our objectives. The breakdown was 7 lacked sufficient sensitivity, 7 appeared to be output-centric features not identified as such, 2 produced factually incorrect explanations, and 3 lacked clarity or were overly verbose.
The full report contains the complete failure mode analysis with all 50 features evaluated.
Sensitivity
Tian et al. formally define feature sensitivity and find that the majority of interpretable features have poor sensitivity. Automated pipelines produce overspecific or overbroad explanations because they rely on max-activating examples without exploring negative cases, lower-quantile activations, or adversarial inputs. The interactive widget above shows a concrete example.
Output-centric features
Some features are better explained by their effect on the model's output than by input patterns. These features reflect next-token prediction rather than input representation. Gur-Arieh et al. describe this class. Identifying them requires access to positive logits, which Delphi doesn't examine. See the widget above for feature 11 as an example.
Incorrectness
2 out of 50 explanations were factually wrong. Feature 36 was explained as detecting "short substrings" when the real pattern is tokens ending in 'u'. Current models struggle with character-level pattern recognition from a handful of examples.
Not human-interpretable
3 out of 50 explanations were technically correct but impractical. Feature 44's explanation enumerated specific day-of-week markers and time range tokens across 89 words when the pattern is "temporal information in formal event announcements" (14 words). The widget above shows the comparison.
Building and testing the agent
Tools
We built an MCP server integrated with Delphi's activation caching and scoring infrastructure. The agent uses Neuronpedia-equivalent tools, structured around the failure modes above.
All experiments use Gemma-2-2B with the google/gemma-scope-2b-pt-res SAE (layer 20, 16k width). All explanations and evaluations were produced by Claude Haiku 4.5. Activations are collected across 30M tokens from JeanKaddour/minipile.
Failure Mode | Primary Tools | Purpose |
|---|---|---|
Sensitivity |
| Test decision boundaries, sample across the activation distribution, identify contrastive non-activating cases |
Output-centric features |
| Access promoted logits and observe causal effects via controlled intervention on feature activations |
Incorrectness |
| Provide in-loop feedback and enable hypothesis revision across investigation cycles |
Poor interpretability |
| Aggregate scattered observations and enforce concise, human-readable explanations |
Table 1. Tools mapped to failure modes.
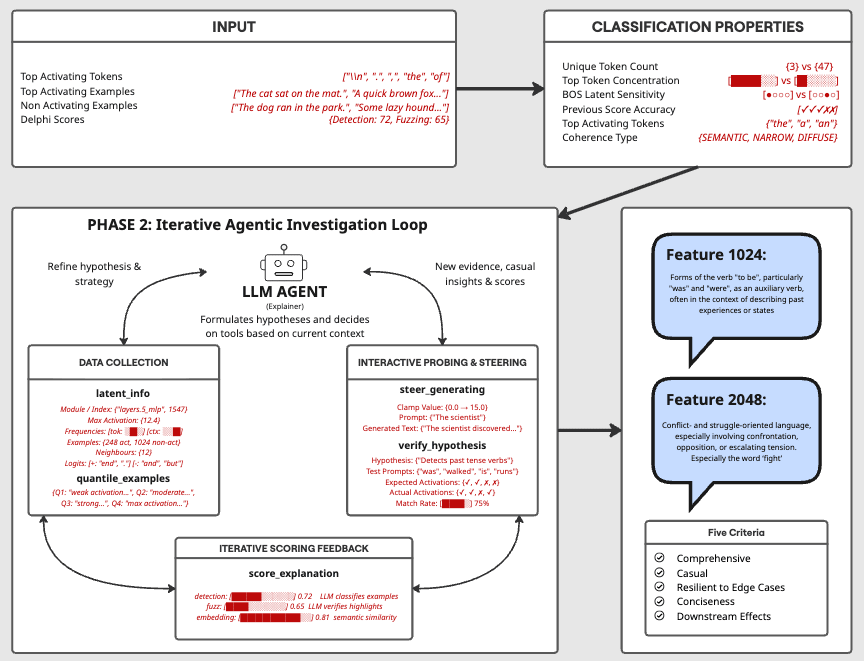
Figure 1. Overview of the agentic feature explanation pipeline.
The workflow mirrors how a human researcher uses Neuronpedia. Gather evidence (top activations, quantile samples, logits), form a hypothesis, test it by generating examples that should and shouldn't activate, use steering to check causal effects, score the explanation, and refine. An alternative would have been to give the agent an entire Jupyter notebook with full programmatic access to the SAE. We chose well-defined tools because cheap, interpretable tool calls were more practical than general but expensive notebook sessions that are harder to debug. At $0.39-$1.70 per feature, cost already matters.
Detailed tool descriptions, usage examples, and verification strategies are in the full report.
The most useful tool turned out to be verify_hypothesis, which supports four testing strategies. Positive example testing generates inputs that should activate. Negative testing generates inputs that should not (e.g., sentences about music videos to test whether "video" alone triggers a feature about recorded evidence). Contrastive pairs testing generates matched pairs where only the hypothesized element changes. Break testing generates adversarial inputs designed to falsify the current hypothesis. The diversity of evidence matters. Providing quantile-based, random, and semantically similar examples alongside top activations prevents the agent from fixating on patterns that only appear at maximum activation. At the end of each run, the agent conducts generalization tests on explanation breadth, domain coverage, and cross-quantile consistency.

Figure 2. Negative testing. The agent generates examples predicted not to activate the feature, revealing that the pattern is about recorded evidence, not "video" in general.
The steering tool (steer_generation) was designed to reveal output-centric features by amplifying or suppressing a feature's activation during generation. It searches for an optimal steering strength using KL divergence between steered and baseline output distributions. Optimal strength sits around 2-3 (50% activation rate). Higher values produce gibberish. Despite being designed for exactly the failure mode that automated methods miss most consistently, the agent underused it because steering results don't improve detection or fuzzing scores.

Figure 3. Hypothesis-breaking strategy. The agent attempts to falsify its current explanation by generating edge cases.
We also found that the agent would generate valuable insights throughout a long investigation but fail to synthesize them into the final explanation. Critical observations scattered across long context windows got deprioritized in favour of the most recent findings. The remember_insight and recall_insights tools address this by letting the agent save observations during investigation and retrieve them before writing the final explanation. Recalling accumulated findings before finalizing consistently improved the output.
Where the agent is better than one-shot
In targeted runs on features where Delphi failed, the agent produced qualitatively better explanations. Feature 20 (sensitivity failure). The agent dropped Delphi's exhaustive token lists, focused on the core pattern, and identified a paragraph break pattern that the baseline missed.
Feature 6 (incorrectness). Delphi attributed activation to the preposition "on" when the feature responds to television-related nouns. The agent got this right.
The agent transcript screenshots above (Figures 2 and 3) show this kind of reasoning in action.
For a closer look at how the agent investigates features step by step, this interactive trace viewer shows annotated investigation traces for several features, including tool calls, hypothesis evolution, and where the agent spent its token budget.
One example (feature 7, Haiku): the agent pulled metadata, formed a POLYSEMANTIC hypothesis, ran 5 rounds of hypothesis verification testing 4 different theories, then spent 45 sequential rephrasing attempts chasing a 2% score improvement without doing any further investigation. The final explanation scored 73.1% embedding accuracy.
Aggregate results
On 27 features scored across all three methods, the agent (81.6%) comes close to Delphi (83.8%) but doesn't beat it. The correlation between Agent and Delphi scores is r = 0.81, which means they converge on similar explanation styles.
Method | Detection | Fuzz | Embedding | Full Average | Wins |
|---|---|---|---|---|---|
Human | 58.0% | 58.9% | 85.9% | 67.6% | 1 |
Agent (V5) | 80.9% | 76.5% | 87.5% | 81.6% | 13 |
Delphi | 85.1% | 78.8% | 87.5% | 83.8% | 13 |
Table 2. Mean scores by method (n = 27 latents).
Is the agent bad, or is there a score ceiling?
The agent has real problems. It forgets earlier insights across long runs. It chases scores instead of using the hypothesis-testing tools we built. It gets stuck refining bad hypotheses instead of starting over. As we iterated on system prompts, it converged toward producing Delphi-style explanations because that's what the scorer rewarded.
But maybe these scores have a ceiling and all three methods are near it.
To test this, we had human expert mech interp researchers produce explanations using Neuronpedia with prompt testing and activation steering. These are people who can use the full investigation toolkit, not just look at activating examples. They scored 58.0% Detection and 58.9% Fuzz, worse than both automated methods. Human experts won on only 1 of 27 features.
The human explanations were composed specifically to satisfy our five quality criteria. They account for edge cases, describe output effects, and define precise scope boundaries. They are, by the criteria we set out, better explanations. But the scorer penalizes all of these qualities.
Feature 1. The human explanation "activates on 'so' or 'thus' as part of 'so far' or 'thus far', and on 'to' as part of 'to date'" scored 59% Detection. Delphi's "The phrase 'so far'" scored 97.5%. Feature 7. The human explanation about grammatical words used in nonstandard ways scored below chance (30.5% / 26.5%) while demonstrating accuracy in manual testing. Feature 11. The human identified the causal mechanism ("this feature anticipates the next token being related to applications") and scored 55% vs Delphi's 85.5%.
Why human explanations score badly
When humans investigate carefully, they find that max-activating examples often look clean, but lower-quantile activations (which make up >98% of all activations) look different and much noisier. Human explanations that account for this full distribution end up more accurate but harder for an LLM scorer to apply. The scorer sees a detailed explanation, tries to use it to predict activations, and gets confused by the qualifications.
A broad explanation like "month names in temporal contexts" achieved 95%/99% on one feature. A similarly broad "function words in narrative text" scored 39%/68% on another. Same strategy, different feature, 50-point gap. Some features have clean patterns that reward broad descriptions. Others have conditional patterns where the score ceiling is lower regardless of method.
This is weak evidence that SAE quality is the limiting factor. Feature splitting, absorption, and polysemanticity mean many features don't have a clean, single-sentence explanation that captures their full activation distribution. The score ceiling varies by feature, and for difficult features, all three methods converge near it.
Concentration class | Range | n | Best | Human | Agent | Delphi |
|---|---|---|---|---|---|---|
NARROW | >= 0.5 | 5 | 91.6% | 70.0% | 91.6% | 89.5% |
MODERATE | 0.2-0.5 | 12 | 89.3% | 70.2% | 83.1% | 87.2% |
BROAD | 0.1-0.2 | 5 | 79.0% | 67.0% | 75.6% | 77.6% |
DIFFUSE | < 0.1 | 5 | 76.7% | 59.5% | 74.2% | 76.2% |
Table 3. Score ceilings by concentration class (n = 27 latents). Token concentration is the fraction of total activations attributed to the single most common token.
NARROW features (high token concentration) are well-served by any method. The gap between methods grows as features become more diffuse, but even the best achievable score drops.
Observations
In multiple runs, the agent arrived at a correct explanation partway through its investigation, then continued refining and ended up with something worse. Over long runs (60k-350k tokens), early findings get buried in the context window.
Top activations often look clean and suggest a coherent pattern. Lower-quantile activations (>98% of all feature activations) look different and much noisier. Human explanations that capture the full distribution end up more accurate but harder for scorers to evaluate. The qualifications needed to cover the noisy tail make the explanation harder to apply as a classification rule.
We also developed a feature classification system (NARROW through DIFFUSE) to route features to different explanation strategies. A simple script that iterated through strategies and picked the highest-scoring result outperformed both Delphi and the full agent. Every approach we tried converged toward gaming the scoring method rather than producing better explanations.
We considered giving the agent a Jupyter notebook with full programmatic access to the SAE instead of constrained tools. We went with well-defined tools because at $0.39-$1.70 per feature, general-purpose code generation would be more expensive and slower. Discrete tool calls also produce readable transcripts, and the failure modes we identified don't require arbitrary computation. They need specific evidence (quantile samples, logit inspection, hypothesis verification).
Reading the explanations side-by-side, the agent's are typically shorter and more readable than Delphi's. Delphi enumerates tokens and activation values. The agent identifies the pattern and states it. When the agent is right, its explanation is better for a human reader. When it's wrong, it's wrong in more interesting ways. Overly specific hypotheses rather than Delphi's vaguely-correct broadness.
About 15% of the features we looked at are output-centric. All automated methods produce wrong explanations for these. They describe input patterns when the feature is about next-token prediction. The agent has tools for this (latent_info, steer_generation) but rarely used them because the scorer doesn't reward output-centric explanations. Feature 11. The human identified the causal mechanism and scored 55% Detection. Delphi described input patterns and scored 85.5%.
For about 15% of features (output-centric), all current automated methods produce wrong explanations. For DIFFUSE features, the best achievable score drops to 77% regardless of method. These are the features where better evaluation methods and targeted investigation would matter most. The full failure mode taxonomy, scoring analysis, and all 27 human/agent/Delphi explanations are in the full report.
Acknowledgments
This work was produced as part of the Supervised Program for Alignment Research (SPAR) - Fall 2025 Cohort. We thank Georg Lange for mentoring this project.
References
- Bricken et al. "Towards Monosemanticity: Decomposing Language Models with Dictionary Learning." Transformer Circuits Thread, 2023.
- Elhage et al. "Attribution Graphs: Methods." Transformer Circuits Thread, 2025.
- Gao et al. "The Pile: An 800gb dataset of diverse text for language modeling." arXiv:2101.00027, 2020.
- Gur-Arieh et al. "Enhancing Automated Interpretability with Output-Centric Feature Descriptions." 2025.
- Kaddour. "The MiniPile Challenge for Data-Efficient Language Models." arXiv:2304.08442, 2023.
- Lieberum et al. "Gemma Scope: Open Sparse Autoencoders Everywhere All at Once on Gemma 2." arXiv:2408.05147, 2024.
- Merity et al. "Pointer Sentinel Mixture Models." arXiv:1609.07843, 2016.
- Paulo et al. "Automatically Interpreting Millions of Features in Large Language Models." arXiv:2410.13928, 2024.
- Tian et al. "Measuring Sparse Autoencoder Feature Sensitivity." NeurIPS 2025 Workshop on Mechanistic Interpretability, 2025.
Discuss