After a couple months’ delay and lots of speculation, DeepSeek finally released the heavily anticipated DSV4, the first major version model since DSV3 (Dec 2024) and DSR1 (Jan 2025). It brings the DeepSeek family up in line with Kimi K2.6, the current open model leader, and Xiaomi Mimo 2.5, a lesser known family released 2 days ago.
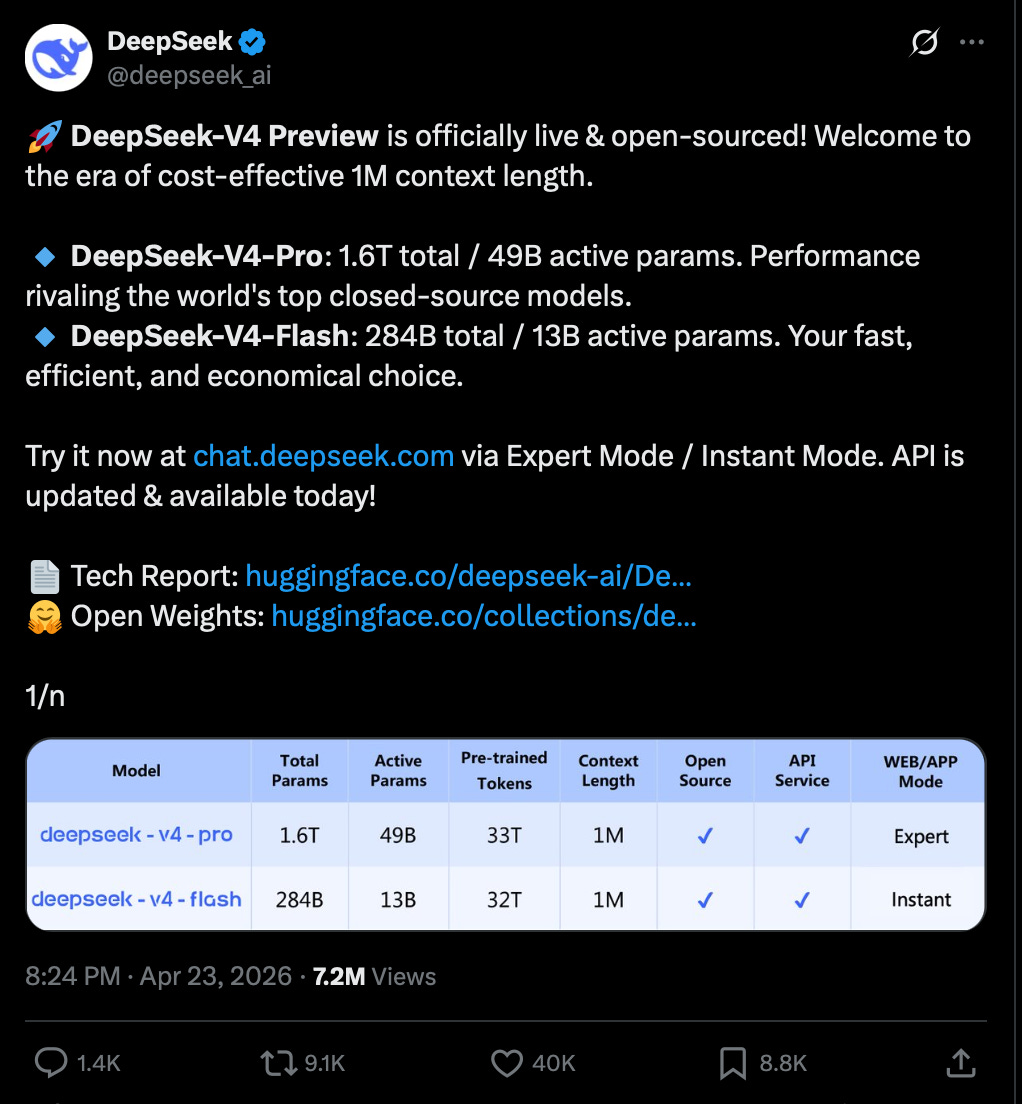
The DSV4 family is roughly a Gemini 3.1, GPT 5.4, Opus 4.6 level model, up to 1.6T MOE withtrained on 32T tokens with FP4, with 1M token context (supported by their new Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) techniques), and incredibly rarely, they released both the Base and Instruct versions - surely setting the stage for a possible “DeepSeek R2” in future, though this one already has reasoning effort.
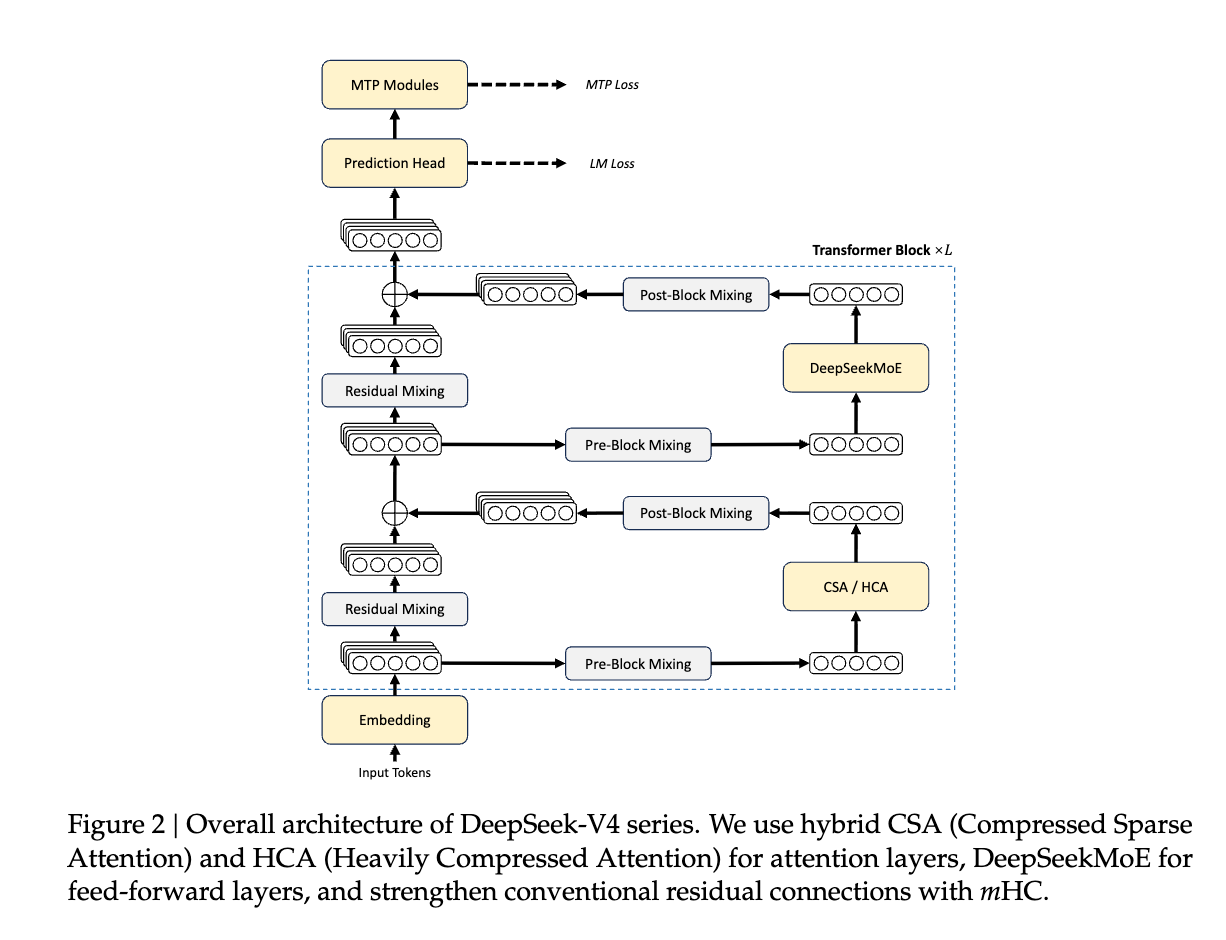
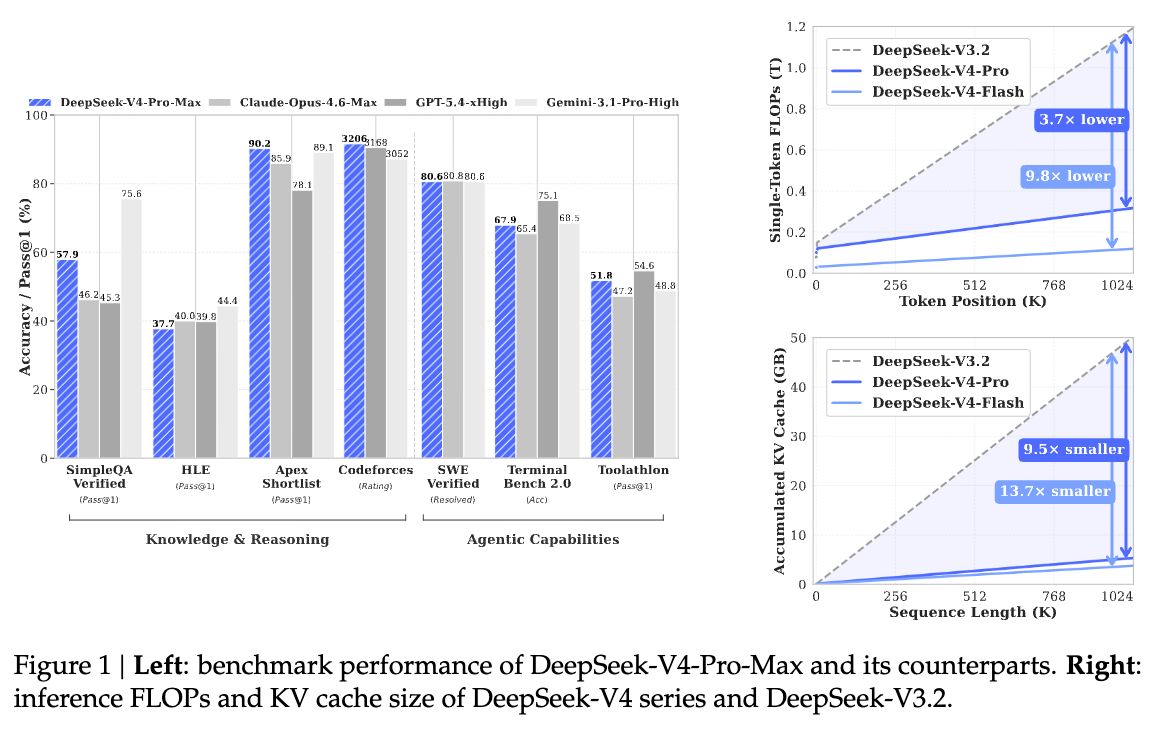
The technical report is a typically dense 58 pages, demonstrating training and inference insights and improvements from the Manifold Constrained Hyper-Connections (mHC) paper they released in January, continued usage of Moonshot’s Muon, and CSA/HCA’s overall INCREDIBLE efficiency improvements on DeepSeek 3.2-Exp’s already impressive Sparse Attention - at 1M tokens, requiring only 27% of FLOPs and 10% of KV cache memory compared with DeepSeek-V3.2:
The geopolitical backdrop behind the Huawei CANN compatibility is DeepSeek weaning dependence off export-controlled NVIDIA/CUDA chips — Ascends are still a quarter the supply of H100s, but this is an important milestone for Chinese total independence.
AI News for 4/23/2026-4/24/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: DeepSeek V4
DeepSeek released DeepSeek-V4 Pro and DeepSeek-V4 Flash, its first major architecture refresh since V3 and first clear two-tier lineup, with 1M-token context, hybrid reasoning/non-reasoning modes, an MIT license, and a technical report detailed enough that multiple researchers called it one of the most important or best-written model papers of the year. Across the reactions, the factual consensus is that V4 materially advances open-weight long-context and agentic coding performance while remaining somewhat behind the top closed frontier models overall. Independent benchmarkers place V4 Pro around the #2 open-weights tier, roughly near Kimi K2.6 / GLM-5.1 / strong Claude Sonnet-class to Opus-ish depending on benchmark and mode, with especially strong long-context and agentic performance; opinions diverge on how close it is to GPT-5.x / Opus 4.7 and on whether this is “democratizing” progress or an architecture so complex that few open labs can realistically reproduce it. Key sources include deep-dive commentary from @ArtificialAnlys, @scaling01, @nrehiew_, @ben_burtenshaw, @TheZachMueller, @ZhihuFrontier, and infra/vendor posts from @vllm_project, @NVIDIAAI, and @Togethercompute.
Core facts and technical details
The most concrete technical claims repeated across the discussion:
Two models
V4 Pro: 1.6T total parameters / 49B active
V4 Flash: 284B total / 13B active
Reported by @ArtificialAnlys, @teortaxesTex, @baseten, @NVIDIAAI
Context
1M tokens, up from 128K in V3.2 per @ArtificialAnlys
Multiple posters frame this as the headline achievement: “solid ultra-long context” @teortaxesTex
Training scale
32T–33T tokens cited repeatedly
@nrehiew_ notes 32T tokens over 1.6T parameters, i.e. roughly 20 tokens/parameter
@teortaxesTex cites 33T
@nrehiew_ estimates pretraining compute at ~1e25 FLOPs
Reasoning / modes
DeepSeek exposes three reasoning modes per @Togethercompute
Hybrid “thinking/non-thinking” positioning noted by @ArtificialAnlys
Long-context architecture
Several threads summarize a new hybrid attention system:
shared KV vectors
compressed KV streams
sparse attention over compressed tokens
local/sliding-window attention for nearby context
@ZhihuFrontier gives the most compact public summary:
2× KV reduction via shared key-value vectors
c4a ≈ 4× compression
c128a ≈ 128× compression
top-k sparse attention on compressed tokens
128-token sliding window
1M context KV cache = 9.62 GiB/sequence (bf16)
8.7× smaller than DeepSeek V3.2’s 83.9 GiB
FP4 index cache + FP8 attention cache gives another ~2× reduction
@ben_burtenshaw condenses this to “10× smaller KV cache”
@TheZachMueller and @TheZachMueller describe CSA + HCA layer patterns, with alternating layers and V4 Flash using sliding-window layers instead of HCA in some places
Quantization / checkpoint format
@LambdaAPI: checkpoint is mixed FP4 + FP8
MoE expert weights in FP4
attention / norm / router in FP8
claim: the full model fits on a single 8×B200 node
Inference hardware / serving
@NVIDIAAI: on Blackwell Ultra, V4 Pro can deliver 150+ TPS/user interactivity for agentic workflows
@NVIDIAAI: published day-0 V4 Pro performance pareto using vLLM
@SemiAnalysis_: day-0 support and benchmarking across H200, MI355, B200, B300, GB200/300
@Prince_Canuma: DeepSeek4-Flash on 256GB Mac
@Prince_Canuma: MLX quants published
@simonw asks about smaller-RAM Mac viability, implying community interest but incomplete support story
@QuixiAI reminds users that many local stacks still lack tensor parallel, relevant because V4-class models strongly stress inference infra
License / availability / pricing
MIT license per @ArtificialAnlys
first-party API plus rapid third-party availability via @Togethercompute, @baseten, @NousResearch, @Teknium
V4 Pro pricing: $1.74 / $3.48 per 1M input/output tokens
V4 Flash pricing: $0.14 / $0.28
cache-hit pricing also given by @ArtificialAnlys
@scaling01 views the pricing as a glimpse of future “Mythos-level” cheap coding models
Reuters-via-posted quote from @scaling01: DeepSeek said Pro pricing could fall sharply once Huawei Ascend 950 supernodes are deployed at scale in H2
Independent evaluations and where V4 lands
The most useful independent benchmark synthesis came from @ArtificialAnlys:
V4 Pro Max: 52 on Artificial Analysis Intelligence Index
up 10 points from V3.2 at 42
becomes #2 open weights reasoning model, behind Kimi K2.6 (54)
V4 Flash Max: 47
positioned around strong mid/high open models, “Claude Sonnet 4.6 max level intelligence”
GDPval-AA (agentic real-world work):
V4 Pro: 1554, leading open-weight models
ahead of Kimi K2.6 (1484), GLM-5.1 (1535), MiniMax-M2.7 (1514)
AA-Omniscience
V4 Pro: -10, an 11-point improvement over V3.2
but still paired with 94% hallucination rate
V4 Flash: 96% hallucination rate
Cost to run AA Index
V4 Pro: $1,071
V4 Flash: $113
Output tokens used on AA Index
V4 Pro: 190M
V4 Flash: 240M
This is a major caveat: cheap per-token pricing does not imply cheap total task cost if the model spills huge token volumes
Additional eval perspectives:
#2 open in Text Arena overall at debut
category wins/placements:
#1 Medical & Healthcare
#15 Creative Writing
#18 Multi-Turn
thinking variant:
#8 Math
#9 Life/Physical/Social Science
@arena emphasizes the Pro vs Flash tradeoff:
Pro ranks ~30 places higher
costs 12× more
Flash is still competitive in Chinese, medicine, math
“~Opus 4.5 estimate holds for now, at least on SimpleBench”
V4 is “definitely better than GLM-5.1 but not quite Opus 4.7, GPT-5.4 or Gemini 3.1 Pro”
@scaling01 lists what scores would confirm <6 month gap:
ARC-AGI-1 ~75%
ARC-AGI-2 ~35%
GSO ~26%
METR 4.5–5 hours
WeirdML ~63%
on his evals, Flash@max ≈ Pro@high on reasoning
Pro focuses more on knowledge (SimpleQA)
after fixing benchmark bugs and letting long-running models run longer, DeepSeek and Kimi improved materially
a simple negative early impression with no detail
on BullshitBench, not about capability but refusal/pushback behavior, GPT-5.5 underperformed; included here because many readers compare V4 in an eval-skeptical environment
Facts vs opinions
Facts / relatively well-supported claims
V4 Pro / Flash were released with the specs above, MIT-licensed, 1M context, and open technical documentation: @ArtificialAnlys, @TheZachMueller
The architecture introduces a new long-context attention system with dramatic KV-cache reduction: @ZhihuFrontier, @ben_burtenshaw
Independent benchmarkers broadly place V4 Pro near the very top of open weights but below the best proprietary models overall: @ArtificialAnlys, @arena, @scaling01
DeepSeek V4 is heavily token-intensive in some evaluations: @ArtificialAnlys
The checkpoint uses FP4/FP8 mixed precision and can fit on an 8×B200 node: @LambdaAPI
Rapid ecosystem support arrived via vLLM and other providers day 0: @vllm_project, @SemiAnalysis_
Opinions / interpretation
“V4 is ~4–5 months behind the frontier” from @scaling01, @scaling01, @scaling01 is an informed estimate, not a measured fact
“Top three open” vs “only open model close to frontier” debate from @teortaxesTex is partly about benchmark trust and framing
“Strongest pretrained model we have” from @teortaxesTex is an opinion hinging on scale + architecture, not direct benchmark supremacy
“Most significant AI paper of the year” from @Dorialexander is enthusiasm, not consensus
“This is what research should look like” from @scaling01 speaks to transparency/style rather than only capability
“Not exactly a democratizing technology” from @teortaxesTex is a strong architectural/political interpretation
Different opinions and fault lines
1) Is V4 near frontier, or clearly behind?
More favorable
@scaling01: puts it at roughly GPT-5.2 / Opus 4.5+ tier
@scaling01: SimpleBench supports ~Opus 4.5
@teortaxesTex: argues it is the strongest pretraining base among opens and implies people are underestimating what post-training can do
More skeptical
@scaling01: below Opus 4.7 / GPT-5.4 / Gemini 3.1 Pro
@scaling01: the gap may widen again because closed labs have bigger models, better science/law/medicine coverage, faster inference with GB200s
@mbusigin: early impressions “not great”
@teortaxesTex: says polished models like K2.6 and GLM 5.1 may still feel better in coding despite lower intrinsic capacity
2) Is V4’s real contribution model quality, or long-context systems design?
A big split in reactions is that many technical readers think the long-context architecture matters more than the raw benchmark position.
@teortaxesTex: “They’ve completed their quest: Solid Ultra-Long Context”
@ben_burtenshaw: first open model where long context and agentic post-training “meet”
@scaling01: expects other open labs to adopt pieces of the architecture
@Dorialexander: frames Huawei/sovereignty constraints as an opportunity to reshape hardware and memory/interconnect design
@jukan05: reads the paper as evidence that NVIDIA’s hardware roadmap is unusually well aligned to where MoE/long-context models are going
3) Is V4 “open democratization,” or too hard to copy?
This was one of the sharpest strategic disagreements.
@teortaxesTex: says V4 is “not exactly a democratizing technology” because the architecture is too difficult for most labs to replicate
@teortaxesTex: suggests even DeepSeek may not want to do this exact architecture again without refactoring
@stochasticchasm: notes the sheer hyperparameter complexity is daunting
Against that, @Prince_Canuma and @Prince_Canuma show that the ecosystem is already compressing and adapting Flash for localish Apple Silicon use, softening the “not democratizing” claim on the inference side if not the training side
4) Are people underrating Flash?
Several reactions suggest Flash may be more important than Pro for practical adoption.
@arena: Flash shifts the price/performance frontier
@TheZachMueller: Flash@max ≈ Pro@high on reasoning tasks
@teortaxesTex: benchmarks may underweight “legit 1M context for pennies”
@Prince_Canuma: Flash runs on 256GB Mac
@baseten and @Togethercompute emphasize long-document analysis and agentic use cases where Flash’s economics matter
China, chips, Huawei, and sovereignty context
DeepSeek V4 was not discussed as a pure model release; it was treated as evidence in the larger US–China compute and sovereignty debate.
@scaling01: Chinese labs are already in or near “takeoff” in the sense that their models help build better models, though still shifted 5+ months behind
@scaling01: thinks chip bans are likely to widen the gap in broad domains over time
@teortaxesTex, @teortaxesTex: disputes simplistic Huawei-dismissal and notes mixed Chinese sentiment toward Huawei
@ogawa_tter: points to analysis of Ascend 950 / A3 clusters and V4 deployment plans
@Dorialexander: argues the sovereignty play around Huawei may reshape hardware architecture
@scaling01: cites DeepSeek saying prices could drop sharply once Ascend 950 supernodes scale in H2
@jukan05: interprets V4 as validating NVIDIA’s Blackwell/Rubin/HBM/interconnect strategy
@NVIDIAAI, @NVIDIAAI: unsurprisingly highlight Blackwell day-0 performance, but this is vendor framing rather than independent proof of strategic superiority
There is also a more ideological thread:
@teortaxesTex, @teortaxesTex, @teortaxesTex argues that Western discourse often misreads Chinese labs as purely state proxies or distillation shops, and instead sees them as serious mission-driven actors. This is interpretive, but it helps explain why the release drew such emotionally charged geopolitical reactions.
Distillation, training data, and data quality
A recurring undercurrent: does V4 mainly reflect architectural innovation, or can critics dismiss it as “distillation”?
@yacineMTB speculates that some complaints about Chinese distillation may partly come from people discovering they’re outperformed
@cloneofsimo: “Very interesting... given they distilled claude 🤔🤔”
@kalomaze: jokes about DeepSeek training on DeepSeek reasoning traces
On the more substantive side, @teortaxesTex says DeepSeek’s writing quality, especially Chinese, reflects long-standing obsession with data cleanliness and cites job listings @teortaxesTex, @teortaxesTex
@nrehiew_ notes the report still lacks much detail on pretraining data beyond standard categories
Overall, factual public evidence in this tweet set supports “DeepSeek trains at large scale with strong data work,” but not any strong claim about the degree of external distillation beyond speculation
Architecture lineage and prior art
Several researchers pointed out that V4 did not emerge from nowhere.
@jaseweston: says DeepSeek uses hash routing from a 2021 ParlAI approach
@suchenzang: criticizes routing-induced outliers, with a jab at hashing
@teortaxesTex: notes Mixtral-style MoE was a reasonable earlier hack, but claims DSMoE changed things
@art_zucker broadly attacks MoEs as a dead end
@gabriberton counters that MoEs are provably effective despite inelegance
@stochasticchasm is even more positive: “MoEs are amazing”
This matters because V4 was read not just as a stronger checkpoint, but as a possible new design point for open long-context MoEs.
Why the technical report itself mattered
A striking amount of praise was directed not just at the model but at the paper/report quality.
@scaling01: “the technical paper is a big deal”
@Dorialexander: “most significant AI paper of the year”
@morqon: “one of the best I’ve ever read”
@scaling01: “this is what research should look like”
@TheZachMueller, @iamgrigorev, @nrehiew_: all signal unusually high effort to digest and test the report
For expert readers, this is important because many frontier releases now arrive with sparse technical disclosure. V4’s report appears to have reset expectations for what a serious open release can look like.
Practical limitations and caveats
Despite the enthusiasm, several caveats recur:
Still behind closed frontier in aggregate capability
especially sciences/law/medicine and broad “general domains” per @scaling01
Reasoning RL may be undercooked
@scaling01: reasoning efficiency not much changed vs V3.2 Speciale
Serving remains hard
@scaling01: many labs serve at only 20–30 tok/s and limited concurrency; running evals can take a day
@ClementDelangue: acknowledges concurrency bottlenecks on HF
High token usage
major practical caveat from @ArtificialAnlys
API controls
@stochasticchasm: notes DeepSeek API appears not to allow sampler control
Adoptability
@teortaxesTex: too complex for many labs to copy cleanly
Broader implications
Three implications stand out.
Open-weight long-context is no longer just marketing.
V4’s strongest contribution may be proving that 1M context can be made operationally credible in an open-weight model, with concrete KV-cache engineering and open inference support. This is why multiple posters focused less on benchmark deltas and more on systems design: @ben_burtenshaw, @ZhihuFrontier, @scaling01.China’s top labs remain competitive in open models, even if not fully closing the closed-model gap.
The benchmark picture across @ArtificialAnlys, @arena, and @scaling01 suggests Chinese labs now dominate much of the open-weight top tier: Kimi, GLM, DeepSeek, and soon MiMo.The bar for “open” is rising from checkpoint release to full-stack co-design.
V4 was instantly discussed alongside vLLM, Blackwell, MLX quants, Mac viability, Ascend clusters, and cache/memory architectures. In other words, “the model” is increasingly inseparable from the inference substrate.
Infrastructure, inference, and local/open ecosystem
Hugging Face launched ML Intern, an open-source CLI “AI intern” for ML work that can research papers, write code, run experiments, use HF datasets/jobs, search GitHub, and iterate up to 300 steps, per @MillieMarconnni. Related sentiment: HF’s $9 Pro tier is unusually strong value per @getpy.
Meta said it will add tens of millions of AWS Graviton cores to its compute portfolio to scale Meta AI and agentic systems for billions of users, per @AIatMeta.
Local/open coding stack momentum stayed strong:
@julien_c: Qwen3.6-27B via llama.cpp on a MacBook Pro feels close to latest Opus for many coding tasks
@p0: free CLI agent built with Pi + Ollama + Gemma 4 + Parallel web search MCP
@Prince_Canuma: DeepSeek V4 quants incoming
@QuixiAI: reminder that llama.cpp / Ollama / LM Studio do not support tensor parallel, pushing serious multi-GPU serving users toward vLLM
Nous/Hermes shipped heavily:
Hermes Agent v0.11.0 introduced a rewritten React TUI, dashboard plugin, theming, more inference providers, image backends, and QQBot support, per @WesRoth
Hermes got broad praise and rapid support for both DeepSeek V4 and GPT-5.5, via @mr_r0b0t, @Teknium
@JulianGoldieSEO and @LoicBerthelot compared Hermes favorably to OpenClaw on learning loops, memory, model support, deployment flexibility, and security
A native Linux sandbox backend for Deep Agents using bubblewrap + cgroups v2 was released by @nu_b_kh
Research papers and benchmarks
On-policy distillation token selection:
@TheTuringPost highlights a paper showing only some tokens carry most learning signal; using ~50% of tokens can match or beat full training and cut memory by ~47%, while even <10% focused on confident-wrong tokens nearly matches full training.
Google Research pushed several ICLR demos:
MesaNet, a transformer alternative / linear sequence layer optimized for in-context learning under fixed memory, via @GoogleResearch
robotics/3D reasoning and efficient transformer work via @GoogleResearch
“reasoning can lead to honesty” demo via @GoogleResearch
MIT Hyperloop Transformers mix looped and normal transformer blocks, using ~50% fewer parameters while beating regular transformers at 240M / 1B / 2B, per @TheTuringPost.
“Learning mechanics” tries to synthesize a theory of deep learning dynamics, via @learning_mech.
Tool/agent systems papers:
Tool Attention Is All You Need claims 95% tool-token reduction (47.3k → 2.4k/turn) with dynamic gating and lazy schema loading, per @omarsar0
StructMem for long-horizon structured memory highlighted by @dair_ai
HorizonBench targets long-horizon personalization with shifting user preferences, via @StellaLisy
Clarifying questions for software engineering:
@gneubig shared work on a model trained specifically to ask clarifying questions, improving results with fewer questions.
GPT-5.5 rollout and coding agents
OpenAI rolled GPT-5.5 and GPT-5.5 Pro into API and ecosystem products with a 1M context window, per @OpenAI, @OpenAIDevs.
Distribution was immediate across Cursor, GitHub Copilot, Codex/OpenAI API, OpenRouter, Perplexity, Devin, Droid, Fleet, Deep Agents:
@cursor_ai: GPT-5.5 is top on CursorBench at 72.8%
@cline: #1 on Terminal-Bench at 82.7
@OpenAIDevs: Perplexity Computer saw 56% fewer tokens on complex tasks
@scaling01: GPT-5.5 medium became strongest non-thinking model on LisanBench with 45.6% fewer tokens than GPT-5.4 medium and higher scores
User feedback clustered around better coding quality and token efficiency, despite mixed feelings about some evals:
@almmaasoglu: best code they’ve read from an LLM; less verbose, less defensive
@KentonVarda: caught a deep Cap’n Proto RPC corner case from a 6-year-old comment
@willdepue: underwhelmed by evals, impressed in Codex on complex technical projects
@omarsar0: smooth switch from Claude Code to Codex/GPT-5.5 thanks to better “effort calibration”
Cursor also shipped /multitask async subagents and multi-root workspaces, via @cursor_ai.
There is growing market emphasis on limits and economics rather than tiny quality gaps:
@nrehiew_ argues usage caps now matter more than small frontier deltas
@HamelHusain says Codex’s subscription structure makes it hard not to use
Industry moves, funding, and policy
Google reportedly plans to invest up to $40B in Anthropic, reported by @FT and echoed by @zerohedge. Reactions centered on how large Anthropic’s compute commitment may now be.
Cohere and Aleph Alpha announced a Canada/Germany sovereign AI partnership, framed as enterprise-grade and privacy/security focused by @cohere, @aidangomez, @nickfrosst.
ComfyUI raised $30M at a $500M valuation, while keeping core/open-local positioning, via @yoland_yan.
Mechanize announced $9.1M raised at a $500M post-money valuation, via @MechanizeWork.
Arcee AI hired Cody Blakeney as Head of Research, emphasizing open-weight American frontier models, via @code_star.
Safety / governance:
OpenAI announced a Bio Bug Bounty for GPT-5.5, per @OpenAINewsroom
Anthropic launched Project Deal, a marketplace where Claude negotiated on behalf of employees, and highlighted model-quality asymmetry and policy challenges, via @AnthropicAI
Creative AI and multimodal
GPT Image 2 + Seedance 2 workflows kept drawing attention:
@_OAK200 and @awesome_visuals showed high-fidelity image→video pipelines
@BoyuanChen0 said 2K/4K images are already available via experimental API and active fixes are underway
Kling announced native 4K output and a $25k short film contest, via @Kling_ai.
Some evaluative nuance:
@goodside noted GPT Images 2.0 could render a valid-looking Rubik’s Cube state, which is surprisingly hard
@venturetwins framed recent image/video gains as a major step toward personalized game-like content generation
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Deepseek V4 and Related Releases
Deepseek V4 AGI comfirmed (Activity: 1138): The image is a meme and does not contain any technical content. The title “Deepseek V4 AGI confirmed” suggests a humorous or exaggerated claim about an AI model, possibly referencing advancements in artificial general intelligence (AGI). The comments further imply a satirical tone, mentioning uncensored datasets and military applications, which are likely not serious claims. The comments reflect a satirical take on AI capabilities, with mentions of uncensored datasets and military applications, indicating skepticism or humor rather than a serious technical discussion.
UserXtheUnknown discusses a test scenario with Deepseek V4, highlighting its tendency to overthink problems. The model interprets constraints like ‘using only one knife’ as mandatory rather than optional, which affects its problem-solving approach. This reflects a nuanced understanding of task constraints, but also indicates potential areas for improvement in handling implicit instructions.
Deepseek V4 Flash and Non-Flash Out on HuggingFace (Activity: 1393): DeepSeek V4 has been released on HuggingFace, featuring two models: DeepSeek-V4-Pro with
1.6T parameters(of which49Bare activated) and DeepSeek-V4-Flash with284B parameters(with13Bactivated). Both models support a context length ofone million tokens, which is significant for handling extensive sequences. The models are released under the MIT license, allowing for broad use and modification. A notable comment highlights the challenge of hardware limitations, particularly RAM, when working with such large models. Another comment suggests the potential benefit of a0.01bit quantizationto manage the model size more effectively.The DeepSeek-V4 models are notable for their massive parameter sizes, with the Pro version having 1.6 trillion parameters (49 billion activated) and the Flash version having 284 billion parameters (13 billion activated). Both models support an extensive context length of one million tokens, which is significant for handling large-scale data inputs and complex tasks.
A user expressed interest in a 0.01-bit quantization of the DeepSeek-V4 models, which suggests a focus on reducing the model size and computational requirements while maintaining performance. Quantization is a common technique to optimize models for deployment on hardware with limited resources.
The mention of the MIT license indicates that DeepSeek-V4 is open-source, allowing for broad use and modification by the community. This licensing choice can facilitate collaboration and innovation, as developers can freely integrate and adapt the models into their own projects.
Buried lede: Deepseek v4 Flash is incredibly inexpensive from the official API for its weight category (Activity: 404): The image provides a comparison between two models, “deepseek-v4-flash” and “deepseek-v4-pro,” highlighting that the “deepseek-v4-flash” model is significantly more affordable in terms of input and output token costs. Despite its affordability, the model supports advanced features like JSON output, tool calls, and chat prefix completion in both non-thinking and thinking modes. The discussion around the image suggests that while the “deepseek-v4-flash” is marketed as inexpensive, some users argue that it is actually overpriced compared to previous versions when considering parameter scaling, with the “V3.2” model being cheaper per parameter. Commenters discuss the impact of GPU shortages on current pricing, suggesting that prices may decrease as GPU production increases. There is also debate about the pricing strategy, with some users noting that the new model is more expensive per parameter compared to older versions.
DistanceSolar1449 highlights a pricing comparison between DeepSeek V3.2 and V4 Flash, noting that V3.2 was priced at
$0.26/0.38for input/output at671b, whereas V4 Flash is$0.14/$0.28at284b. This suggests that V4 Flash is actually more expensive if pricing were to scale linearly with parameters, challenging the notion of its cost-effectiveness.jwpbe provides a comparative analysis of DeepSeek V4 Flash’s API cost, stating that at
14 cents in / 28 cents out, it is significantly cheaper than competitors like Minimax 2.7, which is3xthe cost, and Qwen’s equivalent, which is even higher. They also mention that Trinity Thinking Large is twice as expensive, indicating that V4 Flash offers a competitive pricing advantage in the market.Worried-Squirrel2023 discusses the strategic implications of Huawei’s silicon developments, suggesting that DeepSeek’s pricing strategy involves trading NVIDIA margins for Ascend supply. They predict that once the
950 supernodesscale, DeepSeek could potentially undercut competitors in the open weights tier, leveraging Huawei’s advancements to optimize costs.
Deepseek has released DeepEP V2 and TileKernels. (Activity: 396): Deepseek has released DeepEP V2 and TileKernels, which are significant advancements in AI model optimization and parallelization. DeepEP V2 focuses on enhancing model efficiency and accuracy, while TileKernels introduces a novel parallelization technique that reportedly scales linearly, meaning that doubling computational capacity results in a doubling of processing speed. This release is open-sourced, fostering transparency and collaboration in AI research. For more details, see the DeepEP V2 pull request and the TileKernels repository. One commenter highlights that Deepseek is fulfilling a role that OpenAI was expected to play by advancing research and sharing findings openly, which builds goodwill despite proprietary technologies. Another commenter questions if the parallelization technique indeed scales linearly, suggesting a significant technical breakthrough if true.
DeepEP V2 and TileKernels by DeepSeek are noted for their potential advancements in parallelization techniques. A user speculates that these techniques might achieve linear scaling, meaning that doubling computational capacity could directly double processing speed. This could represent a significant efficiency improvement in model training and inference.
There is speculation about DeepSeek’s hardware usage, particularly regarding the SM100 and Blackwell GPUs. One commenter suggests that DeepSeek might be using Blackwell GPUs for training, possibly through rented B200 units on Vast.ai. This hardware choice could influence the performance and capabilities of their models.
The potential innovations in DeepSeek’s next model, possibly named v4, are highlighted. The focus is on the integration of Engram and mHC technologies, which are expected to play a crucial role in the model’s performance. The success of these innovations will likely depend on the new dataset DeepSeek has developed.
2. Qwen 3.6 Model Performance and Benchmarks
This is where we are right now, LocalLLaMA (Activity: 1755): The image depicts a MacBook Pro running a Qwen3.6 27B model via Llama.cpp, showcasing the capability of executing complex AI models locally, even in airplane mode. This highlights the potential for local AI models to enhance efficiency, security, privacy, and sovereignty by operating independently of cloud services. The post underscores the technological advancement in making powerful AI models accessible on personal devices, emphasizing the importance of local execution for privacy and control. Commenters express skepticism about the overstatement of the Qwen3.6-27B model’s capabilities, suggesting that while it is impressive for its size, it does not match the performance of more advanced models like Sonnet or Opus. There is concern that exaggerated claims could lead to user disappointment and backlash against the broader LLM community.
ttkciar highlights the potential for user disappointment with the Qwen3.6-27B model, noting that while it’s impressive for its size and suitable for agentic code generation, it doesn’t match the capabilities of more advanced models like Sonnet or Opus. The concern is that overhyping its abilities could lead to backlash against the broader LLM community, not just the individual making the claims.
sooki10 agrees that while the model is impressive for local coding tasks, comparing it to more advanced models like Opus is misleading and could undermine the credibility of the claims being made. This suggests a need for more accurate benchmarking and communication about the model’s capabilities to manage user expectations effectively.
Melodic_Reality_646 points out the disparity in resources, comparing the use of a high-end 128GB RAM m5max system to a more accessible setup. This highlights the importance of considering hardware limitations when evaluating model performance, as not all users have access to such powerful systems, which can skew perceptions of a model’s capabilities.
DS4-Flash vs Qwen3.6 (Activity: 470): The image presents a benchmark comparison between DS4-Flash Max and Qwen3.6 models, specifically the
35B-A3Band27Bversions. The chart highlights that DS4-Flash Max generally outperforms the Qwen models across various categories, particularly excelling in ‘LiveCodeBench’ and ‘HLE’ benchmarks. This suggests that DS4-Flash Max may have superior capabilities in coding and reasoning tasks. The discussion in the comments hints at the potential for larger models like a122Bversion of Qwen3.6, and emphasizes the significance of the1M token contextfeature, which could impact performance in other benchmarks like ‘omniscense’. Commenters note that despite DS4-Flash Max’s larger size, its performance is only slightly better than Qwen3.6, raising questions about efficiency versus scale. The1M token contextis highlighted as a significant feature that could influence future benchmark results.Rascazzione highlights the significant increase in context length with Qwen 3.6, noting its ability to handle a 1 million token context. This is a substantial improvement over previous models and could have significant implications for tasks requiring extensive context handling, such as document summarization or complex dialogue systems.
LinkSea8324 points out the size difference between the models, with DS4-Flash at 284 billion parameters compared to Qwen 3.6’s 27 billion. This raises questions about the efficiency and performance trade-offs between model size and capability, especially in terms of computational resources and inference speed.
madsheepPL discusses the non-linear nature of benchmark improvements, suggesting that even if a model appears only slightly better in benchmarks, the practical implications can be more significant. They emphasize that improvements in scores are not directly proportional and can have varying impacts on real-world applications.
Qwen 3.6 27B Makes Huge Gains in Agency on Artificial Analysis - Ties with Sonnet 4.6 (Activity: 964): Qwen 3.6 27B has achieved parity with Sonnet 4.6 on the Agentic Index from Artificial Analysis, surpassing models like Gemini 3.1 Pro Preview, GPT 5.2 and 5.3, and MiniMax 2.7. The model shows improvements across all indices, although the gains in the Coding Index are less pronounced due to its reliance on benchmarks like Terminal Bench Hard and SciCode, which are considered unconventional. The focus of training appears to be on agentic applications for OpenClaw/Hermes, highlighting the potential of smaller models to approach frontier capabilities. Anticipation is building for the upcoming Qwen 3.6 122B model. Commenters express excitement about the potential of smaller models like Qwen 3.6 27B, noting the significant improvements and potential for future versions. However, there is skepticism about the extent of these gains, suggesting that some improvements might be due to ‘benchmaxxing’ rather than inherent model capabilities.
Iory1998 highlights the impressive performance of the Qwen 3.6 27B model, noting that it surpasses a 670B model from the previous year. They mention running the Q8 version at 170K with KV cache at FP16 on an RTX 3090 and RTX 5070ti, utilizing 40GB of VRAM, which underscores the model’s efficiency and power.
AngeloKappos discusses the narrowing benchmark gap, sharing their experience running the Qwen3-30b-a3b model on an M2 chip. They note its capability to handle multi-step tool calls effectively, suggesting that if the 27B dense model performs this well, the upcoming 122B model could pose challenges for API providers due to its potential performance.
Velocita84 raises a point about potential “benchmaxxing” in the reported performance gains of the Qwen 3.6 27B model, implying that some of the improvements might be attributed to optimized benchmarking rather than inherent model capabilities. This suggests a need for scrutiny in evaluating model performance claims.
Compared QWEN 3.6 35B with QWEN 3.6 27B for coding primitives (Activity: 491): The post compares two versions of the QWEN 3.6 model, specifically the
35Band27Bparameter versions, on a MacBook Pro M5 MAX with64GBRAM. The35Bmodel achieves72 TPS(tokens per second), while the27Bmodel achieves18 TPS. Despite the slower speed, the27Bmodel produces more precise and correct results for coding tasks, whereas the35Bmodel is faster but less accurate. The test involved generating a single HTML file to simulate a moving car with a parallax effect, using no external libraries. The models were hosted using Atomic.Chat, with source code available on GitHub. One comment highlights the output of theQwen 3.6 27B FP8model using opencode, taking approximately52 seconds. Another comment provides a visual comparison with theQwen 3.5 27B Q3model, suggesting differences in output quality.The user ‘sacrelege’ shared a performance result for the Qwen 3.6 27B model using FP8 precision, noting that it took approximately 52 seconds to complete a task with ‘opencode’. This suggests a focus on optimizing model performance through precision adjustments, which can significantly impact computational efficiency and speed.
User ‘nikhilprasanth’ provided a visual comparison for the Qwen 3.5 27B Q3 model, indicating a potential interest in comparing different versions and quantization levels of the Qwen models. This highlights the importance of understanding how different model configurations can affect performance and output quality.
‘Technical-Earth-3254’ inquired about the quantization methods used in the tests, which is crucial for understanding the trade-offs between model size, speed, and accuracy. Quantization can greatly influence the efficiency of large models like Qwen, especially in resource-constrained environments.
Qwen 3.6 27B is a BEAST (Activity: 1239): The post discusses the performance of the Qwen 3.6 27B model on a high-end laptop with an RTX 5090 GPU and
24GB VRAM, highlighting its effectiveness for pyspark/python and data transformation debugging tasks. The user employs llama.cpp withq4_k_matq4_0and is exploring further optimizations with IQ4_XS at200k q8_0. The user has not yet implemented speculative decoding. The setup includes an ASUS ROG Strix SCAR 18 with64GB DDR5 RAM. Comments suggest avoiding kv cache as q4 for coding, recommendingq8for130kcontext. Another comment anticipates performance improvements with upcoming releases from z-lab and a specific GitHub pull request that promises a2xdecode speed increase. There is also curiosity about the model’s performance on systems with16GB VRAMand32GB DDR5 RAMwith offloading.sagiroth highlights a technical consideration when using Qwen 3.6 27B for coding tasks, advising against using the KV cache as q4 due to limitations, and instead suggests using q8 to achieve a
130kcontext window, which can significantly enhance performance for large context tasks.inkberk points out an upcoming improvement in decoding speed, referencing a pull request #22105 on the
llama.cpprepository. This update, along with the anticipated release of the ‘dflash drafter’ by z-lab, promises a potential2xincrease in decode speed, which could greatly benefit users in terms of efficiency.Johnny_Rell inquires about the performance of Qwen 3.6 27B on a system with
16 GB VRAMand32 GB DDR5, specifically regarding the effectiveness of offloading. This suggests a focus on optimizing resource allocation to handle the model’s demands, which is crucial for running large models efficiently on consumer-grade hardware.