AI Safety in Practice
Over the past few years, large language models (LLMs) have become embedded in many business operations, including powering customer service platforms, internal knowledge tools, and automated decision systems.
But rapid adoption has exposed new risks and invited regulatory scrutiny. As a result, enterprises are now expected to have robust AI safety frameworks in place.
In this article, we will discuss everything you need to ensure AI safety in practice.
We will cover the following:
- Understanding the enterprise GenAI threat space
- Adversarial red-teaming for GenAI systems
- Safety evaluations and benchmarking
- Guardrails for enterprise GenAI applications
- Continuous monitoring in production
- Documenting and communicating residual risk to stakeholders
Understanding the Enterprise GenAI Threat Space
Before you can defend a system, let’s understand what you are defending against. The range of threats facing enterprise GenAI is quite different from those facing traditional software and broader than many security teams initially expect. The most common risks include:
- Hallucination: The tendency of language models to generate plausible-sounding but factually incorrect outputs. In a consumer chatbot, this is an annoyance. In an enterprise context, where a model might summarize contracts, answer compliance questions, or draft customer-facing communications, hallucinations can cause direct business harm.
- Prompt injection: It occurs when a malicious actor embeds instructions in user-supplied content that cause the model to override its intended behavior. It is particularly dangerous in agentic systems, where the model takes actions on behalf of users. A successful prompt injection in an agentic pipeline can have consequences more than a single bad output.
- Data leakage: Models deployed with access to proprietary internal data can be prompted in ways that surface information users should not be able to access. A GenAI assistant can inadvertently become a data exfiltration tool without careful access control and output monitoring.
- Jailbreaking: It is the use of carefully crafted prompts to bypass safety training. Models that have been aligned to refuse certain categories of requests can often be manipulated through role-play scenarios, fictional framing, or iterative prompt construction. Enterprise deployments that rely solely on a model’s built-in safety training without adding external guardrails are vulnerable to these techniques.
The enterprise context intensifies these risks due to sensitive data, automated downstream actions, and legal liabilities in regulated industries. Threat actors include external adversaries and both malicious and unintentional internal users.

Adversarial Red-Teaming for GenAI Systems
Red-teaming is the process of intentionally attacking an AI system to find its weaknesses. It differs from traditional penetration testing because it focuses on the model’s logic and output rather than the code.
Its goal is to surface failure modes to find the prompts, contexts, and adversarial inputs that cause the system to behave in ways that are harmful, embarrassing, policy-violating, or dangerous.
Done well, red-teaming produces a structured inventory of risks that informs both technical mitigations and governance decisions.
Building a Red-Team Program
An effective red-team program for enterprise GenAI combines human expertise with automated tooling.
Human red-teamers bring creativity, domain knowledge, and the ability to reason about context. The most valuable red-teamers are domain experts, a compliance officer who knows exactly what a financial advisor is not allowed to say, a clinician who understands what constitutes dangerous medical advice, and a lawyer who can identify when an output creates legal exposure.
External red-teamers offer a perspective unconstrained by familiarity with the system. Organizations that have been building and tuning a model often develop blind spots about its behavior. Bringing in external specialists, including adversarial ML researchers and specialized AI security firms, provides a valuable independent check.
Automated red-teaming tools, including frameworks like Garak, Microsoft’s PyRIT, and commercial adversarial testing platforms, enable scale. They can generate thousands of adversarial prompts, test the model’s responses, and surface patterns that would be impractical to identify through manual testing alone. The best red-team programs use automated tools to cover breadth and human testers to probe depth.
Structuring Red-Team Exercises
Red-team exercises can be structured (following a specific checklist) or open-ended (allowing testers to be creative). Structured exercises test specific, predefined categories of harm against a defined checklist. They are efficient for regression testing and for demonstrating coverage to auditors. Open-ended exercises give red-teamers freedom to explore without constraints, which tends to surface the most creative and unexpected failure modes.
The raw material of any red-team exercise is an adversarial prompt library, a curated collection of inputs designed to probe different failure modes. Building a good library is an investment; it should be tagged with attack category, target behavior, and severity, and updated continuously as new attack techniques emerge.
Every finding from a red-team exercise should be documented with enough detail for an engineer to reproduce it: the exact prompt or sequence of inputs, the model configuration at the time of testing, and the output produced.
Additionally, an assessment of severity and a recommended remediation should be included. Severity scoring should reflect both the likelihood of the attack being used in practice and the magnitude of harm if it succeeds.
Safety Evaluations and Benchmarking
A rigorous safety evaluation framework turns ad hoc testing into a repeatable, measurable discipline.
Designing a Safety Evaluation Framework
Red-teaming explores a system’s boundaries by testing its responses, while safety evaluation systematically assesses behavior against established standards. Both methods are complementary and essential for thorough analysis.
A safety evaluation framework starts with a clear definition of the safety dimensions that matter for your deployment. These typically include harmlessness, honesty, robustness, fairness, and privacy. The relative weight of each dimension will depend on your use case and industry.
Evaluation datasets should be built with your specific deployment in mind. Generic open-source safety benchmarks are a useful starting point, but they rarely capture the specific risks of a particular enterprise application. A customer service bot for a financial institution needs evaluation data that reflects the specific compliance requirements and sensitive topics relevant to that context.
Qualitative human review should complement quantitative metrics. Numbers alone can miss subtle problems, outputs that are technically within policy but tonally inappropriate, or responses that are factually accurate but misleading by omission. A regular cadence of human review by subject-matter experts provides a check that automated metrics cannot fully replicate.
Automated Evaluation Pipelines
At enterprise scale, manual evaluation cannot keep pace with the rate of model updates, prompt changes, and configuration modifications. Automated evaluation pipelines are essential.
One popular approach is LLM-as-judge: using a separate language model to evaluate the outputs of the deployed model against defined safety criteria. This approach scales well and can capture nuanced violations that rule-based classifiers miss. Its weakness is that the judge model inherits its own biases and failure modes, which need to be understood and monitored.
Safety evaluations should be integrated into your GenAI system’s CI/CD pipeline. Every change, such as a new model version, a modified system prompt, or a change to retrieval configuration, should trigger an automated safety eval run before deployment. Failing a safety threshold should block deployment, just as a failing unit test blocks a code release.
Standard benchmark suites like HELM and MT-Bench provide comparison points and can help identify broad capability or safety regressions. But these should be supplemented with custom, domain-specific evals that reflect the actual risks of your deployment.
Tracking Regressions Over Time
Safety evaluation is only valuable if its results are tracked systematically over time. Establishing clear baselines gives you a reference point for detecting regressions. Acceptable thresholds for each safety dimension should be documented and agreed upon before deployment.
Evaluation results should be version-controlled alongside the model and configuration artifacts they measure. This creates an audit trail that supports both internal governance and external regulatory review. When a regulator asks how you validated the safety of a system before deployment, version-controlled eval results are the documentary evidence you need.
Communicating evaluation outcomes to non-technical stakeholders requires translation. A safety score of 94.3% on a harmlessness benchmark means little to a risk officer or a board member. The most effective communication frames results in terms of failure rates and business impact. In our testing, the system produced policy-violating outputs in about 1 in 200 interactions; mitigation has reduced this to fewer than 1 in 2,000.
Guardrails for Enterprise GenAI Applications
No single control is enough as effective guardrails work in layers, each designed to catch what the previous one missed.
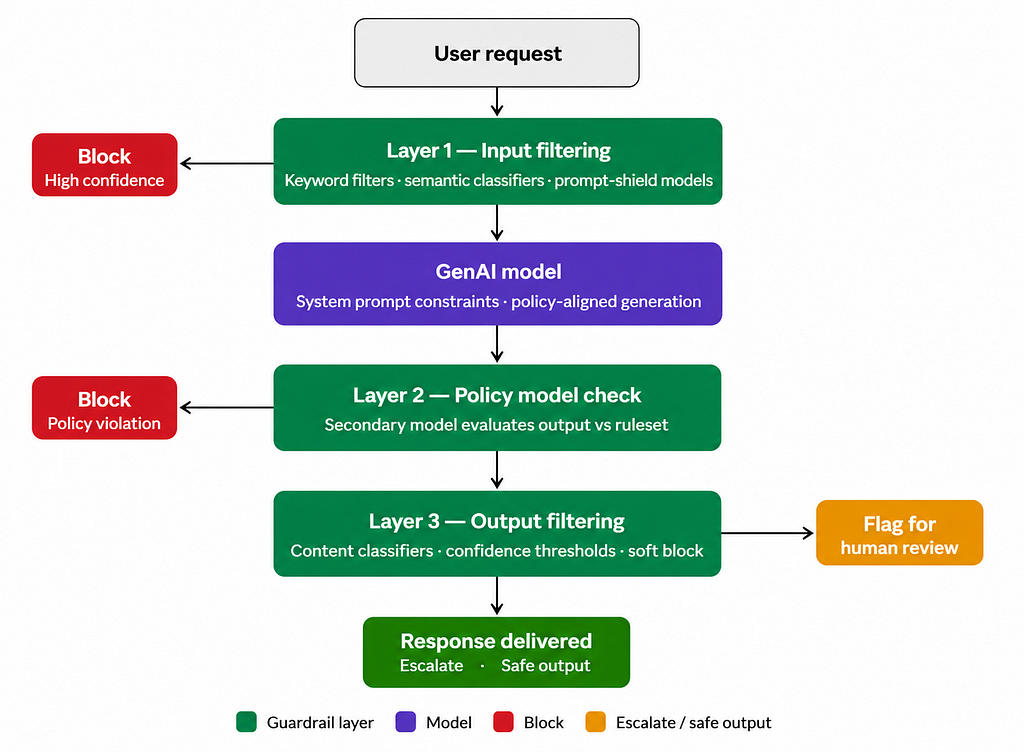
Input Filtering and Prompt Sanitization
Guardrails are the technical controls that enforce safety policy at runtime. The first line of defense is input filtering, screening user-supplied content before it reaches the model.
The simplest input filters use keyword lists and regular expressions to block known-bad content: slurs, prohibited topics, personally identifiable data patterns. These are fast and easy to implement but brittle. A determined user can trivially bypass them with minor reformulation.
More robust input filtering uses semantic classifiers, models trained to detect the intent behind a message rather than its surface form. Dedicated prompt-shield models, offered by several major AI providers, are specifically designed to detect prompt injection attempts and jailbreak patterns. These are considerably harder to evade than rule-based filters.
The central tension in input filtering is between over-blocking and under-blocking. A filter that is too aggressive will refuse legitimate requests, frustrating users and undermining adoption. A filter that is too permissive will fail to catch policy violations. Calibrating this balance requires careful analysis of your user population, use case, and risk tolerance and should be revisited regularly as usage patterns evolve.
Output Filtering and Content Classifiers
Even with robust input filtering, the model may produce outputs that violate policy. Output filtering provides a second layer of defense, screening generated content before it is delivered to the user.
Content classifiers for output filtering range from simple rule-based systems to fine-tuned transformer models trained on labeled examples of policy-violating content. The most effective architectures combine multiple signals: a fast rule-based pre-filter that catches obvious violations cheaply, followed by a more expensive classifier for ambiguous cases.
Handling borderline cases requires a deliberate strategy. Hard blocking is appropriate for high-severity categories. For lower-severity cases, soft blocking strategies may be preferable: delivering a modified or truncated output, adding a disclaimer, or routing the interaction to a human reviewer rather than refusing outright. Confidence thresholds should be tuned based on the cost of false positives versus false negatives for your specific context.
Policy Models and Constitutional Constraints
Organizations can embed policy constraints more deeply into the system’s behavior beyond filtering individual inputs and outputs. The most direct approach is the system prompt: a set of instructions provided to the model at the start of every interaction that defines its role, permitted behaviors, and explicit prohibitions. A well-crafted system prompt can greatly reduce policy violations, though it cannot prevent them entirely, particularly against adversarial users.
A stronger approach uses a secondary policy model: a separate model that evaluates each generated output against a defined policy ruleset before delivery. This creates a modular architecture in which the policy layer can be updated independently of the generative model, and in which policy decisions are auditable.
Major AI vendors, including Anthropic, OpenAI, Google, and Microsoft, offer guardrail layers as part of their enterprise API offerings. These provide a useful foundation but should not be treated as sufficient on their own. Enterprise-specific policies, industry regulations, and proprietary use-case constraints typically require supplementary in-house controls.
Human-in-the-Loop Review
Automated guardrails are essential for scale, but they are not infallible. For high-stakes outputs, medical recommendations, financial advice, legal assessments, and communications to vulnerable populations, human review should be a mandatory step.
Designing effective human-in-the-loop workflows requires balancing thoroughness with operational efficiency. Review queues should be prioritized by risk level: high-confidence violations and high-severity categories get immediate attention; lower-confidence flags are reviewed in batches. Escalation paths should be clearly defined: what happens when a reviewer is uncertain, and who has the authority to make final decisions on edge cases.
The most valuable aspect of human review is the feedback loop they create. Reviewer judgments are a training signal for improving automated classifiers. Organizations that capture and use this feedback systematically see continuous improvement in their automated guardrail performance over time.
Continuous Monitoring in Production
Production environments differ from test environments because user behavior there is more varied and more creative than any test suite can anticipate. The distribution of inputs shifts over time as the user base grows and evolves. Novel attack techniques emerge continuously. And model behavior can drift subtly as infrastructure changes, caching strategies are modified, or upstream model providers update their APIs.
Continuous monitoring treats safety as an operational discipline. The key signals to track include guardrail trigger rates (how often input and output filters are firing), refusal rates (how often the model declines to answer), user feedback signals (thumbs down, escalations, complaints), and anomaly patterns (unusual concentrations of flagged content from specific users, time windows, or topic areas).
The logging architecture that supports this monitoring requires careful design. You need to capture enough data to detect and investigate safety incidents while respecting privacy obligations and data retention policies. In regulated industries, what you log and how long you keep it may be governed by specific legal requirements. Logging architectures should be designed with legal and privacy counsel involved.
Alerting should be configured for meaningful anomalies: a sudden spike in guardrail trigger rates, a new pattern of prompt-injection attempts, or a cluster of user complaints about a specific topic. Each alert type should have a corresponding incident response playbook, a defined set of steps for investigating, containing, and remediating the issue. These playbooks should be tested before they are needed.
Drift detection deserves particular attention. Behavioral drift can be difficult to detect without systematic monitoring. Tracking safety metrics against established baselines at a regular cadence and promptly investigating deviations are the most reliable ways to catch drift before it becomes a problem.

Documenting and Communicating Residual Risk to Stakeholders
Every organization deploying GenAI systems needs to confront an uncomfortable truth: no combination of red-teaming, evaluation, and guardrails will reduce risk to zero. There will always be failure modes that testing did not surface, adversarial inputs that guardrails do not catch, and edge cases that emerge in production. The goal of an enterprise AI safety program is to reduce risk to an acceptable level and to manage what remains transparently.
Residual risk, the risk that remains after all mitigations are in place, must be documented, governed, and communicated. The primary tool for this is a GenAI Risk Register: a living document that catalogs known failure modes, their likelihood of occurrence, their potential impact, the mitigations in place, and the residual risk that remains after those mitigations.
The Risk Register should be owned by a named individual or team, reviewed on a defined cadence, and updated whenever the system changes or a new failure mode is identified.
Model cards and system cards are also important communication tools. A model card documents the characteristics, intended use cases, known limitations, and evaluation results for a specific model. A system card extends this to the full deployment, the model, the guardrails, the data sources, the access controls, and the governance processes.
These documents serve multiple audiences: internal engineering teams who need to understand the system’s constraints, risk, and compliance functions that need to assess exposure, and external stakeholders who need assurance that the system has been responsibly developed.
Effective risk communication requires tailoring to the audience. A technical team needs to understand specific failure modes, guardrail architectures, and evaluation metrics. An executive audience needs to understand business impact, regulatory exposure, and the adequacy of mitigations relative to peer organizations. Regulators need evidence of process rigor, audit trails, and clear accountability. Customers need honest, accessible information about what the system can and cannot do reliably.
Governance structures are the organizational scaffolding that makes all of this sustainable. An AI risk committee with representation from legal, compliance, security, engineering, and business leadership provides the cross-functional oversight that GenAI safety requires. Clear sign-off processes for new deployments and significant system changes ensure that risk decisions are made deliberately, by the right people, with adequate information.
Conclusion
Enterprise AI safety is a continuous process. Companies can use GenAI confidently by combining red-teaming, rigorous evaluation, and active guardrails. Staying vigilant in production ensures that the system remains a tool for growth rather than a source of liability.
AI Safety in Practice: Red-Teaming, Evaluation, and Guardrails for Enterprise GenAI Deployments was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.