A governance advisors deep-dive into why wrong names, transposed dates, and duplicate SSNs are a decade-long unsolved problem — and the hybrid rule + ML + RAG approach that finally closes the gap.


How does a healthcare system spend billions on technology and still not know who its patients are?
It is not a hypothetical. Every major U.S. health system today operates with a measurable percentage of patient records that are either duplicated, fragmented, or factually wrong — names misspelled, dates of birth transposed, Social Security Numbers shared across family members, ITINs attached to the wrong person. The Joint Commission estimates that 5 to 10 percent of all patient records contain a critical demographic error. At a hospital processing 500,000 encounters a year, that is up to 50,000 patients whose identity is in some degree of doubt every single day.
This is the central problem of healthcare data quality: it is not a technology gap, a budget gap, or an awareness gap. It is a governance gap — the persistent failure to treat demographic data correctness as a first-class operational responsibility rather than an IT cleanup task. The consequences move quietly: a denied claim here, a duplicate prescription there, a quality metric inflated by phantom patients, a HIPAA audit triggered by an identity mismatch that was preventable from the first keystroke.
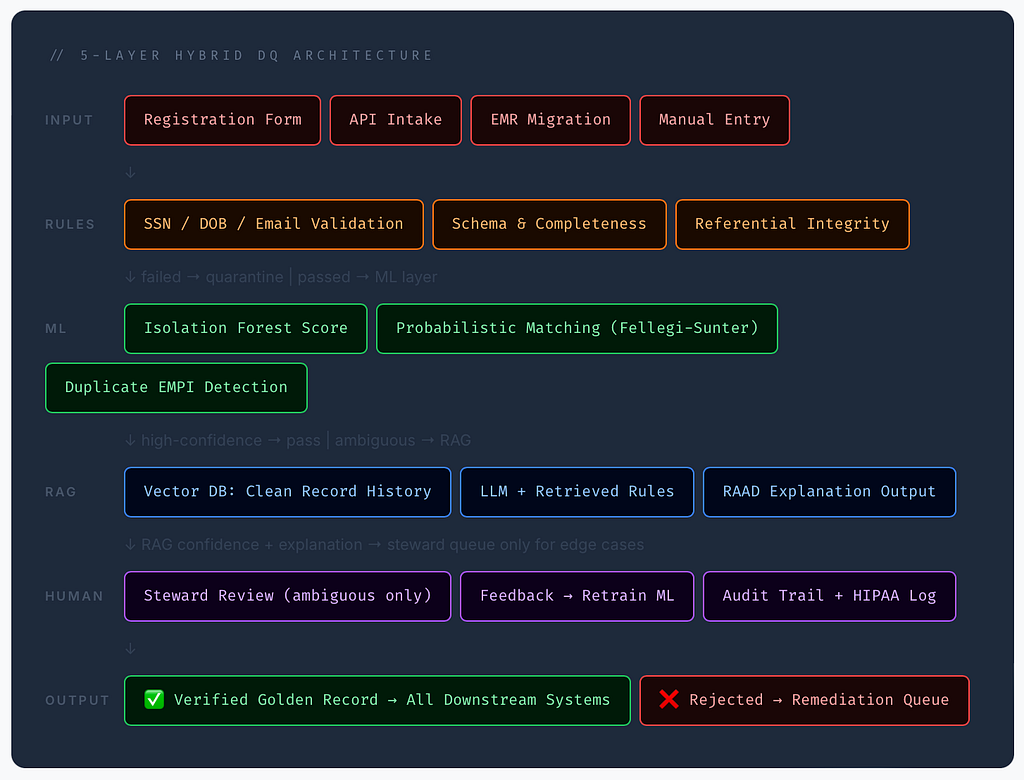
This article examines the anatomy of that failure — what breaks, where, why it is so expensive, and what a layered approach combining deterministic rules, machine learning anomaly detection, and retrieval-augmented AI can realistically achieve in 90 days.


Patient demographic data is everything that answers who before a system asks what. Names, dates of birth, SSNs, ITINs, phone numbers, email addresses, and mailing addresses. Every field has its own failure mode:

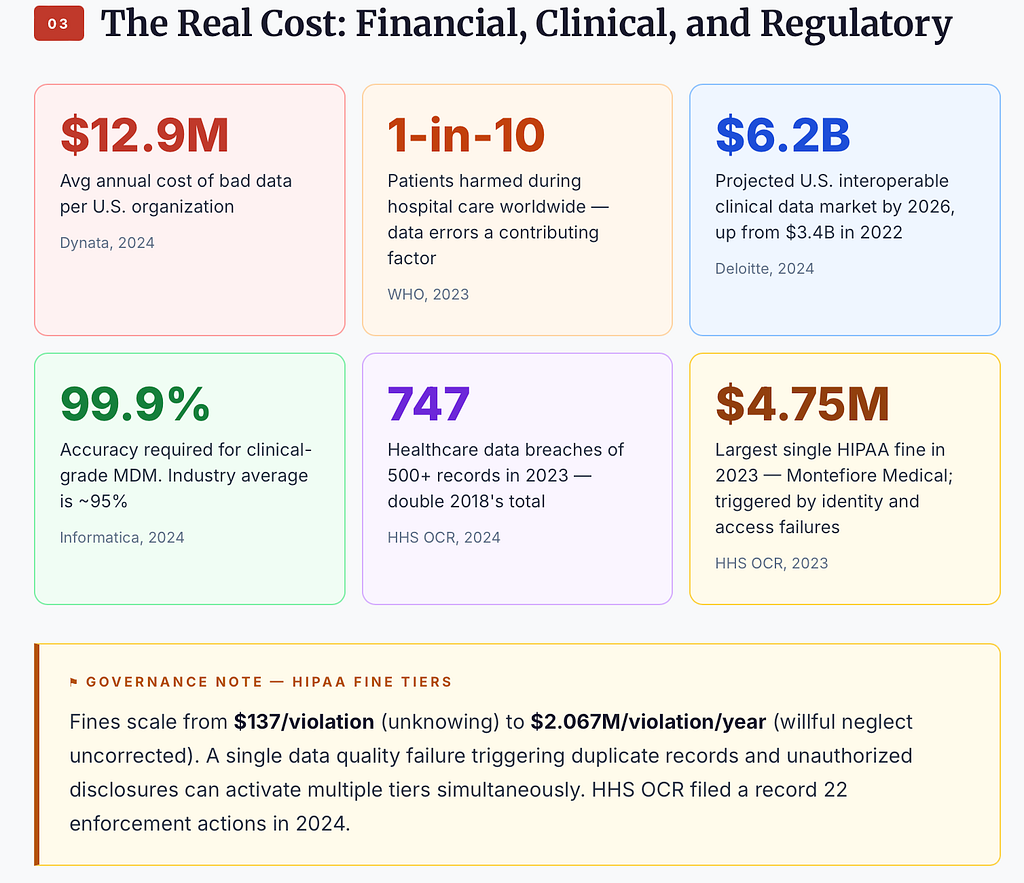
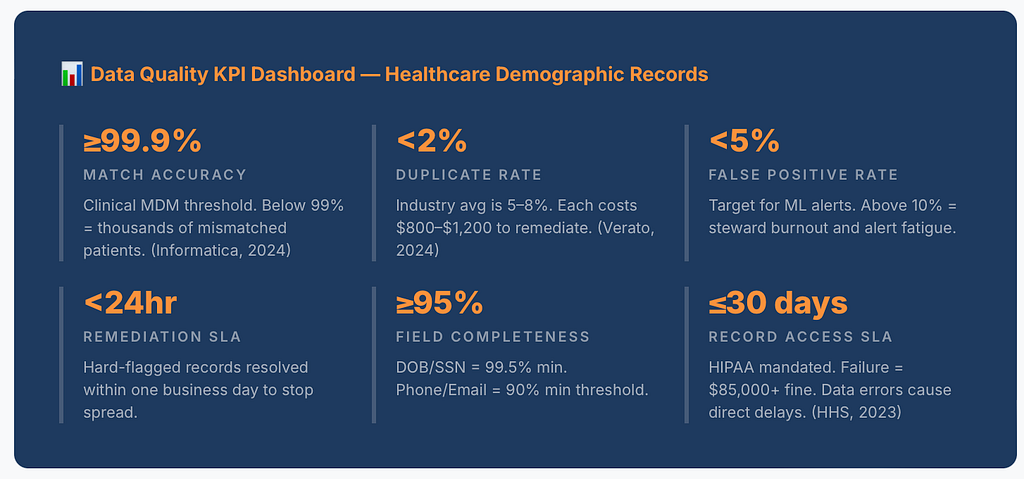
Every corrupted field creates what I call a broken identity thread — a fracture point where two systems disagree on whether they are looking at the same person. That fracture is the root of duplicate medical records, and healthcare systems require 99.9% matching accuracy to stay clinically safe. The industry average sits closer to 95%.

Think of your data pipeline as a river. A contaminant injected at the headwaters — an intake desk, an API form, a migrated batch — does not stay in one place. It travels to every tributary downstream.
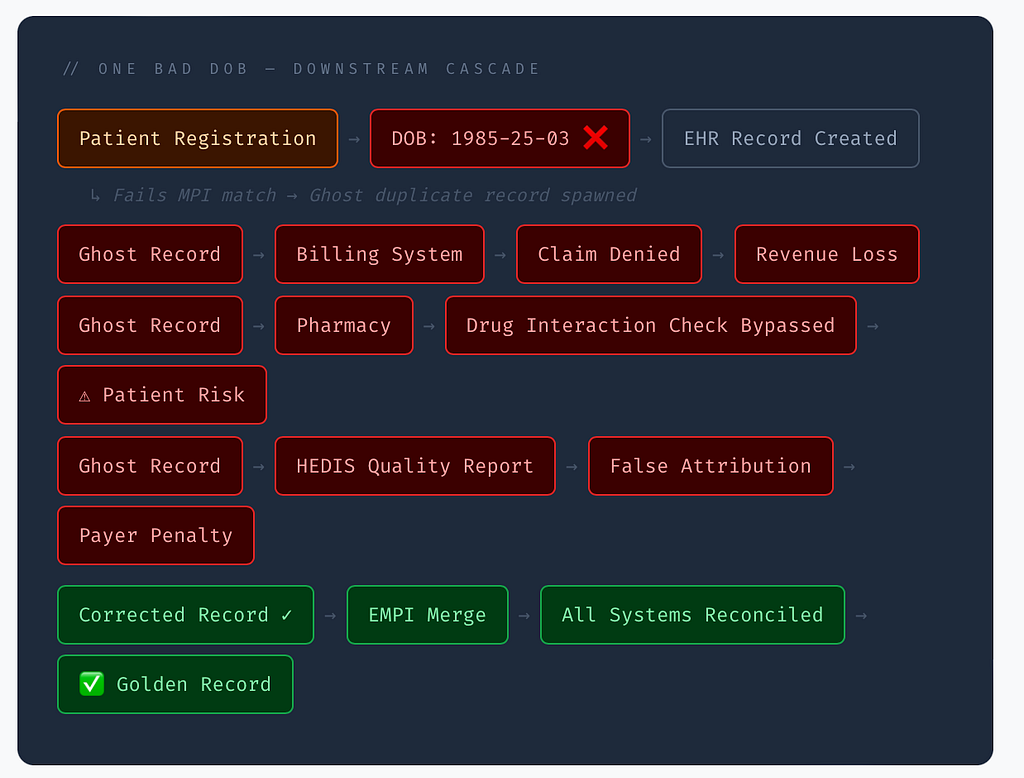
The later in the pipeline you discover the error, the more expensive the fix. Industry data puts the cost of correcting a duplicate patient record at $800–$1,200 in administrative remediation alone — before any clinical or legal exposure is counted.

Every mature data quality program starts here. Rule-based validation is deterministic, explainable, and beloved by auditors. It catches the obvious: impossible dates, invalid SSN prefixes, malformed emails, placeholder phone numbers.
import re
from datetime import date, datetime
from dataclasses import dataclass
@dataclass
class QCResult:
field: str; passed: bool; rule: str; msg: str = ""; severity: str = "ERROR"
class DemographicQC:
SSN = re.compile(r'^\d{3}-\d{2}-\d{4}$')
EMAIL = re.compile(r'^[^\s@]+@[^\s@]+\.[^\s@]+$')
JUNK_EMAIL = {"test@test.com", "na@na.com", "none@none.com"}
JUNK_PHONE = {"0000000000", "1111111111", "9999999999"}
def check_dob(self, v: str) -> QCResult:
# R-001: valid date, not future, age 0–130
try:
d = datetime.strptime(v, "%Y-%m-%d").date()
age = (date.today() - d).days / 365.25
if d > date.today(): return QCResult("dob", False, "R-001", "Future date")
if age > 130: return QCResult("dob", False, "R-001", "Century error")
return QCResult("dob", True, "R-001")
except ValueError:
return QCResult("dob", False, "R-001", f"Unparseable: {v}")
def check_ssn(self, v: str) -> QCResult:
# R-002: format + no invalid area numbers 000/666/9xx
if not self.SSN.match(v): return QCResult("ssn", False, "R-002", "Bad format")
p = v.split("-")[0]
if p in ("000","666") or p[0]=="9":
return QCResult("ssn", False, "R-002", "Invalid area number")
return QCResult("ssn", True, "R-002")
def check_email(self, v: str) -> QCResult:
v = v.strip().lower()
if v in self.JUNK_EMAIL: return QCResult("email", False, "R-003", "Placeholder", "WARN")
if not self.EMAIL.match(v): return QCResult("email", False, "R-003", "Bad format")
return QCResult("email", True, "R-003")
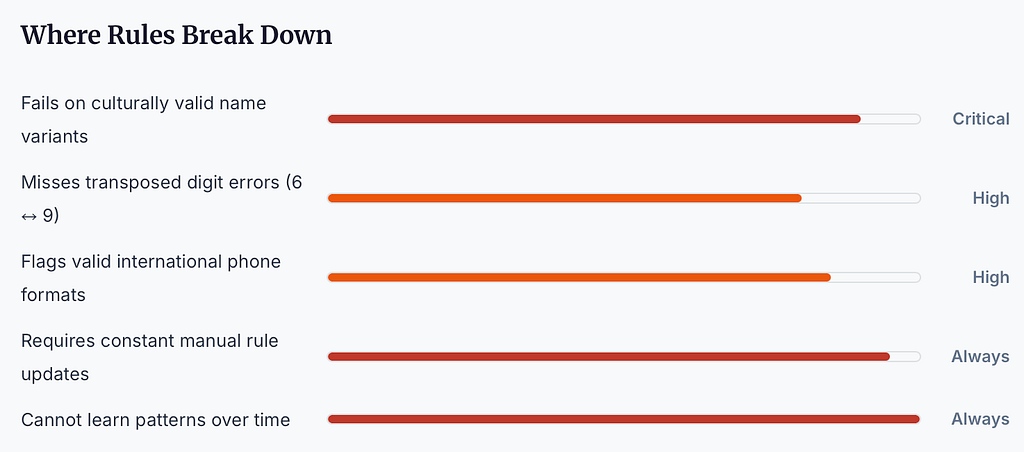

Isolation Forest, One-Class SVM, and LSTM autoencoders can detect records that are statistically unusual even when they pass every rule. A 22-year-old on a Medicare plan. An SSN area number geographically inconsistent with the address. A DOB/insurance-type mismatch. These are the errors rules will never catch.
But the false positive trap is real. A 5% false positive rate on 10,000 daily records means 500 legitimate records quarantined every day. At that volume, data stewards drown, and alert fatigue sets in. The fix is tiered confidence routing — not binary flag/no-flag, but a spectrum:


Retrieval-Augmented Generation (RAG) grounds AI decisions in retrieved, verifiable facts — your actual data dictionaries, validation rules, historical error logs, and demographic reference tables. The model does not rely on training-time memory. Every decision traces back to a governance artifact you can audit.
The key application here is RAAD — Retrieval-Augmented Anomaly Detection. Instead of a silent score, RAAD returns a human-readable justification: “This DOB was flagged because 78% of records with this SSN area number and ZIP code have DOBs between 1955–1975. This record’s DOB of 2003 is a 4.2-sigma deviation. Nearest clean match: DOB 1983–02–15.” That is auditable. That is trainable. That is what governance teams need.




“AI Can’t Fix What Human Won’t Govern: The Dirty Data Crisis No One Talks About” was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.