AI-assisted development has lowered the barrier to building software. It hasn’t eliminated the need to build it well.
Vibe coding the now-common practice of using AI to generate and refine entire features via natural language prompts, pioneered in early 2025 by Andrej Karpathy’s description of a workflow where you ‘fully give in to the vibes’ [1] has quietly become one of the most significant shifts in how software development happens today. The term has since been recognized by Merriam-Webster and Collins as an official entry [14][15], and major vendors including IBM, GitHub, and Google Cloud now publish official guides around it [2][3][4]. Developers move faster. Non-developers build things that previously required a technical team to handle the development. The feedback loop from idea to running code has collapsed from days to minutes.
But speed without established standards is how a working prototype becomes an unmaintainable liability. The Software Development Lifecycle (SDLC) exists for exactly this reason: not to slow us down, but to ensure what we build survives contact with the real world. And it applies to vibe coding just as much as it applies to any other methodology [6][7].
To be precise vibe coding is an implementation method of directing AI to generate, iterate, and refine code through natural language rather than writing it by hand. The SDLC is the governance framework that surrounds that act.
This is a guide to applying each phase of the SDLC to an AI-assisted workflow, written for engineering leaders and senior practitioners who are already using AI tools and need a disciplined framework for doing so at scale. For each phase: what it looks like in practice, what the AI can do for us, and where we still need to think for ourselves.
This article is about making the SDLC and Vibe Coding work together. It does not argue against vibe coding. It argues that vibe coding without SDLC discipline is how fast teams become slow teams, and slow teams become rewrite teams.
The AI handles the syntax. The SDLC handles the stakes.
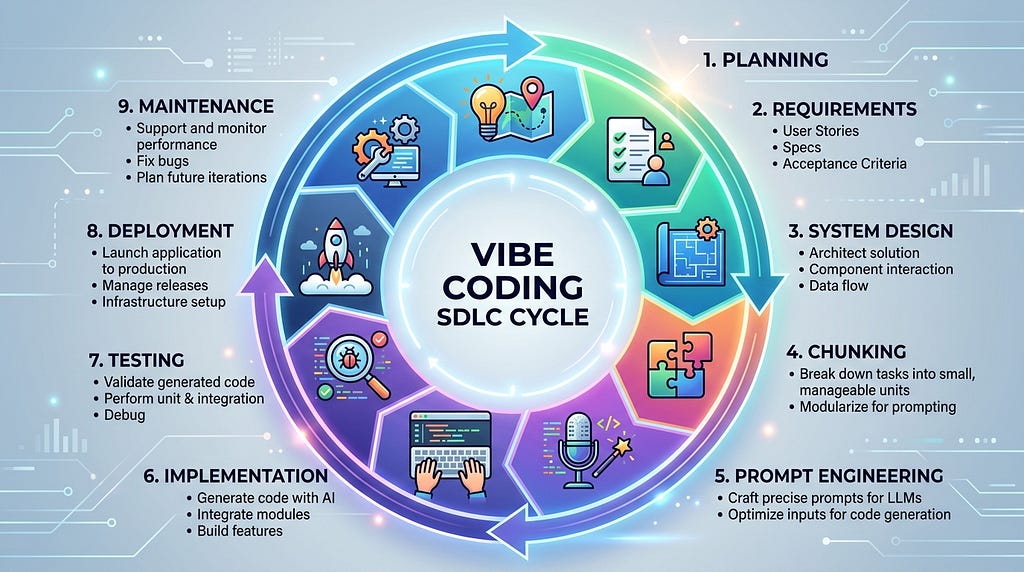
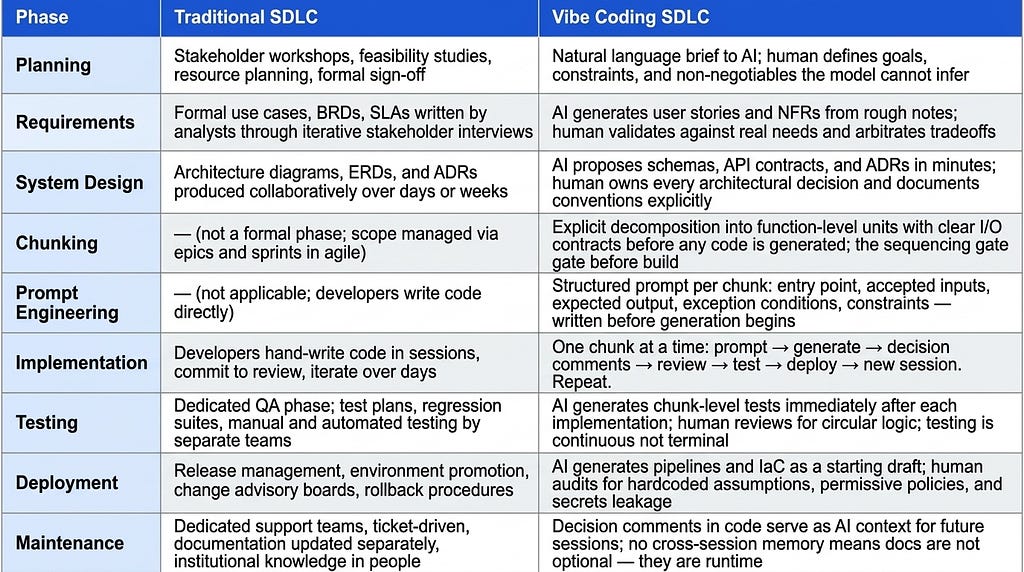
Traditional SDLC vs. Vibe Coding SDLC at a Glance
Each phase below is covered in depth in the sections that follow.

Phase 1: Planning
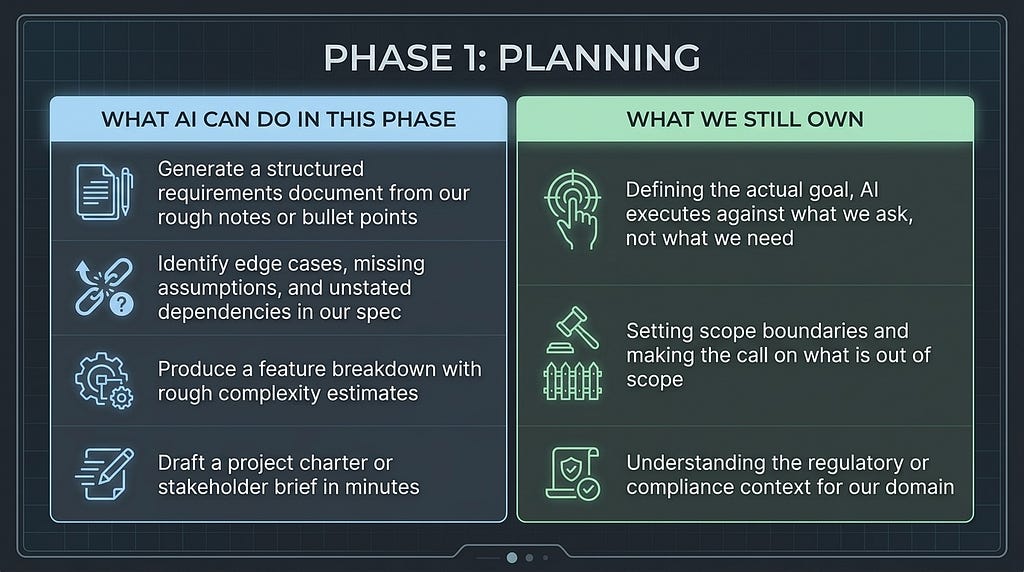
Why this phase survives the AI revolution
Planning is the phase most likely to be skipped in a vibe coding session. The temptation is immediate: an idea surfaces, the model is ready, and a complete functional application can be running in twenty minutes. The problem is that “running” and “correct” are different things.
Before prompting for a single line of code, we need answers to a short set of questions. What problem does this solve? Who uses it? What does success look like? What are the hard constraints, performance thresholds, compliance requirements, integration dependencies, future enhancement possibilities?
These are not questions that AI can answer. They are human decisions. Decisions made at the planning stage cost almost nothing to change. The same decisions embedded in 4,000 lines of generated code cost significantly more. As current SDLC and vibe-coding frameworks note, AI accelerates execution but does not remove the need for deliberate planning [6][7].
Phase 2: Requirements
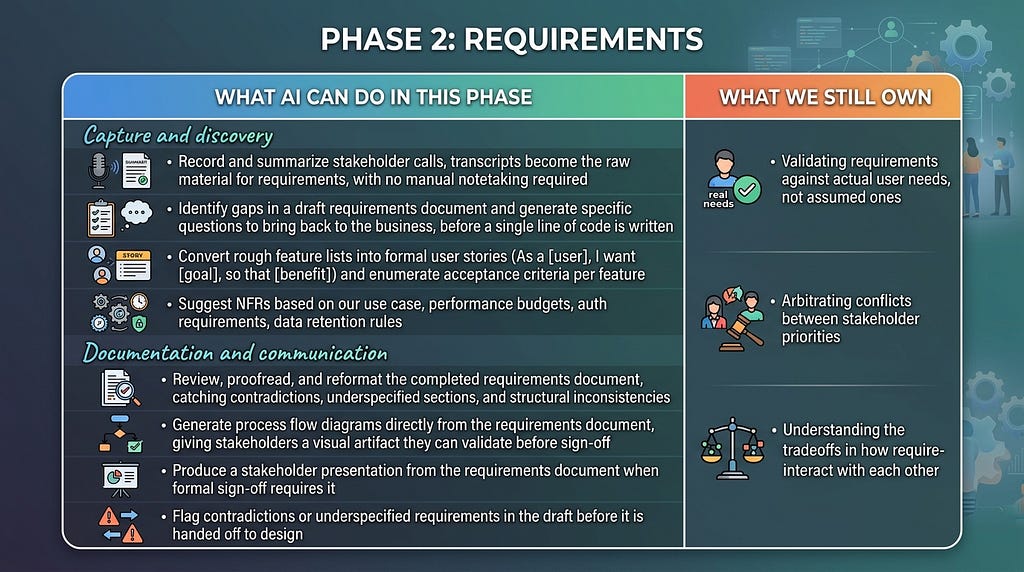
Precision at this stage prevents ambiguity at every stage
Requirements analysis is the discipline of turning a goal into a specification precise enough to build from. In traditional software development, this phase involves stakeholder interviews, use case modeling, and sign-off documents. In vibe coding, it is the difference between prompts that produce coherent software and prompts that produce eloquent confusion.
The quality of AI output is a direct function of the quality of our requirements. Vague inputs produce vague outputs, except the outputs will look confident and complete, which is the more dangerous failure mode.
A well-structured requirements phase for a vibe coding project should produce three things: a list of functional requirements (what the system does), non-functional requirements (NFRs how well it does it, covering performance, security, and scalability), and a clear articulation of what the system does not do.
Phase 3: System Design
Architecture decisions outlive the code that implements them
This is the phase where the most consequential mistakes happen in vibe coding workflows. Not because developers don’t think about design, but because AI models are very good at generating locally reasonable code that doesn’t compose well at scale [12].
Consider a concrete example: When a model is asked to build a user authentication system it will produce one instantly. When asked separately to build a notification system, it will produce another. But, when asked to integrate them both, it will often produce something that technically works but shares no coherent data model, duplicates business logic, and introduces three different patterns for error handling, each internally consistent, none consistent with the others. The problem isn’t the code, it’s the absence of an architecture that governed the code generation.
System design in a vibe coding context means establishing the architecture before we generate the components. Define the data models first. Establish the API contract. Decide where the state lives. The right patterns should be decided and documented explicitly so every subsequent prompt session operates against the same blueprint.
AI is an excellent implementation engine. It is a poor architect, because architecture requires holding the whole system in mind simultaneously, understanding constraints outside the current context window, and making decisions that optimize for long-term maintainability over short-term functionality [11].
What AI can do in this phase
Research and evaluation
– Research the latest advancements, known issues, and community-reported limitations of the chosen technology stack, use search-enabled AI tools to ensure current awareness, not just training-data recall
– Identify architectural patterns that have evolved since the initial design decision and present a structured comparison of the original approach versus the alternative, with explicit strengths, weaknesses, and migration considerations
– Cross-reference the requirements document against the proposed architecture and flag any missed requirements, incorrect assumptions, or implementation gaps before design is finalized
– Produce architecture decision records (ADRs) based on stated constraints, capturing the rationale for decisions made and alternatives considered
Design artifacts and security
– Generate entity-relationship diagrams, data flow diagrams, and architecture diagrams from the design description, visual artifacts stakeholders can review and validate before implementation begins
– Propose API endpoint structures, REST conventions, and schema definitions from the data model description
– Identify security gaps in the proposed architecture, authentication boundaries, data exposure risks, privilege escalation paths, and missing encryption at rest or in transit. Treat this as a first-pass review, not a substitute for a formal security assessment
– Identify potential scaling bottlenecks and single points of failure in the described architecture
What we still own
– The architecture itself, what connects to what, why it connects that way, and what the constraints are that future sessions must respect
– Technology selection we make the call, we own the reasoning, and we live with the consequences when the ecosystem evolves
– Establishing and enforcing the conventions that govern all subsequent code generation every session that deviates from the blueprint without authorization creates debt we will pay later

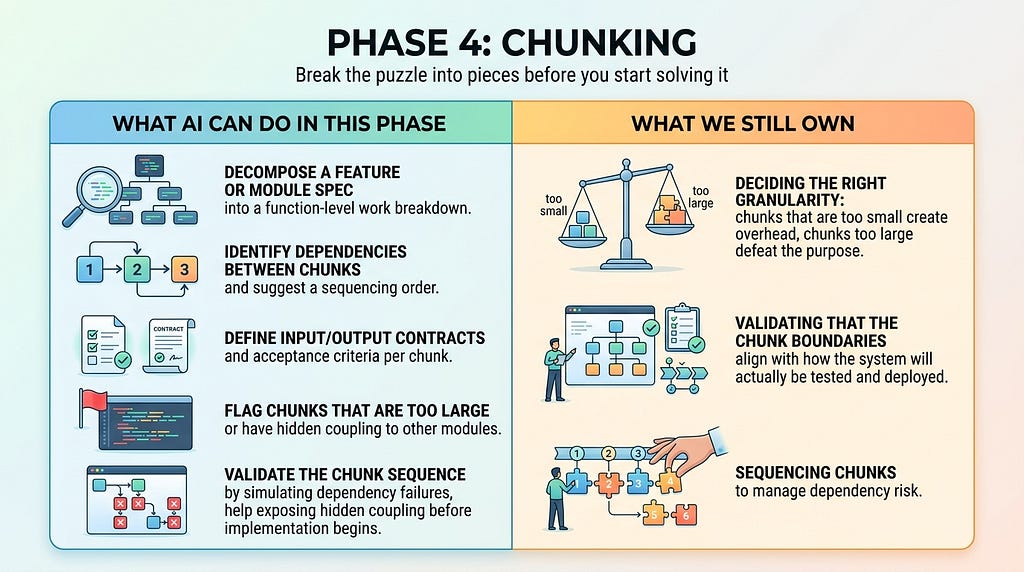
Phase 4: Chunking
Break the puzzle into pieces before we start solving it
This phase does not exist in classical SDLC literature. It should. And for vibe coding specifically, it may be the single most important step between design and implementation.
Think of a large software project as a jigsaw puzzle. We would never try to solve a thousand-piece puzzle by grabbing random pieces and forcing connections. Instead, we work a section at a time, the border first, then a recognizable cluster, then another. Each completed section is verified, stable, and understood before we build adjacent to it. Vibe coding without chunking is the equivalent of dumping all the pieces on the table and asking the AI to solve the whole thing in one prompt. We may get something that looks like a picture from a distance. It will not hold together under pressure.
Chunking is the discipline of decomposing our system design into the smallest independently buildable, testable, and deployable units, down to the function level if necessary, before a single line of code is generated. Each chunk should have a clear input, a clear output, a defined scope, and a measurable success criterion. If we cannot articulate what done looks like for a chunk, the chunk should be considered too large or too vague.
Don’t build a palace all at once. Build one pillar, review it, test it, deploy it. Then build the next. The puzzle is solved one section at a time.
The practical output of a chunking session is a work breakdown of an ordered list of discrete units, each small enough to generate in a single focused session, test in isolation, and ship independently. A user authentication module is not a chunk. The function that validates a token, the function that creates a session, and the middleware that enforces auth on a route those are the chunks. Each one can be built, reviewed, and confirmed before the next depends on it.
This approach transforms the implementation loop from a high-stakes single pass into a repeating, low-risk cycle: build one chunk, test it, deploy it, learn from it, then move to the next. Errors are caught at the chunk boundary rather than discovered deep in an integrated system where root causes are opaque. Progress is visible and measurable at every step. And when something breaks, as things do the blast radius is one chunk, not the whole codebase.
Phase 5: Prompt Engineering
The quality of our output is bounded by the quality of our input
Prompt engineering is not a soft skill. In a vibe coding workflow it is a key technical discipline with measurable consequences. Every chunk identified in the previous phase now needs a prompt. The precision of that prompt directly determines the quality, completeness, and correctness of the generated code.
Most developers under specify the prompts. They describe the goal but leave the boundaries implicit, assume the model will infer the context, and skip the exception conditions because it seem obvious. The AI fills those gaps confidently, fluently, and often incorrectly. A well-constructed prompt eliminates the gaps before the model has a chance to fill them with assumptions.
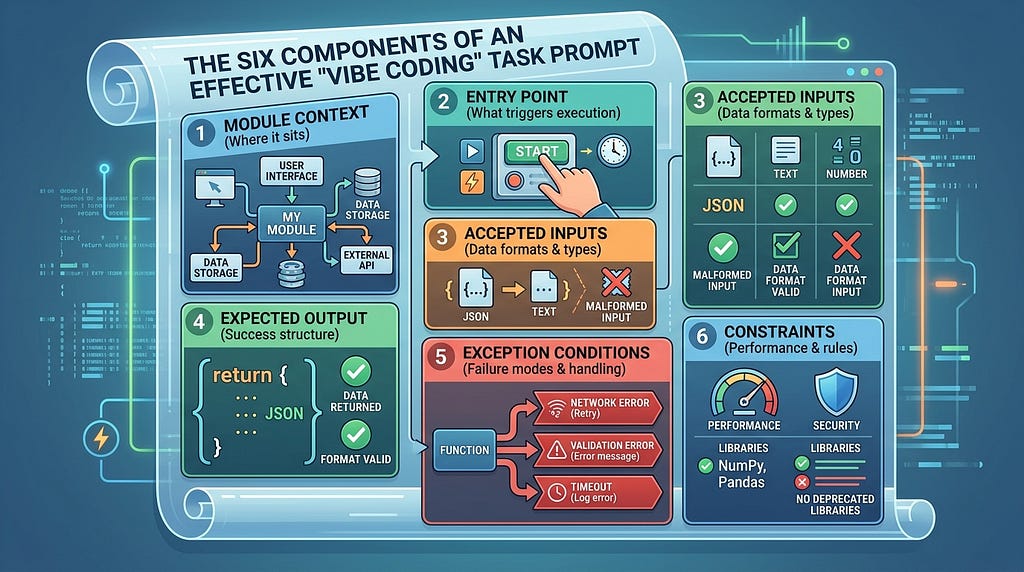
An effective prompt for a vibe coding implementation task is structured like a function contract expressed in plain language. It should specify six things explicitly, in this order:
Module context: Where the chunk sits in the broader system and what it connects to
Entry point: Where execution begins, what triggers this function or module
Accepted inputs: Data types, formats, valid ranges, and what constitutes a malformed input
Expected output: Exact return structure, data types, and success conditions
Exception conditions: Every failure mode, edge case, and error state, with explicit handling instructions
Constraints: Performance requirements, security considerations, libraries to use or avoid
The difference between a vague prompt and a structured one is not the length. It is the specificity. A prompt that says ‘build a function to validate a user token’ will produce something that works in the happy path. A prompt that specifies the token format, the expiry logic, the behavior on a malformed token, the behavior on an expired token, and the error objects to return for each failure mode will produce something that is actually production-ready.
A prompt that describes the happy path gets us a happy-path code. Every exception condition we omit is a gap the model fills with its best guess.
Prompt structure also serves a documentation function. A well-formed prompt, saved alongside the code it generated, is an exact record of the intent behind the implementation. When a future session needs to extend or debug that chunk, feeding it the original prompt alongside the code gives the AI the full context of what was intended, not just what was produced. The prompt is the spec. Treat it accordingly.

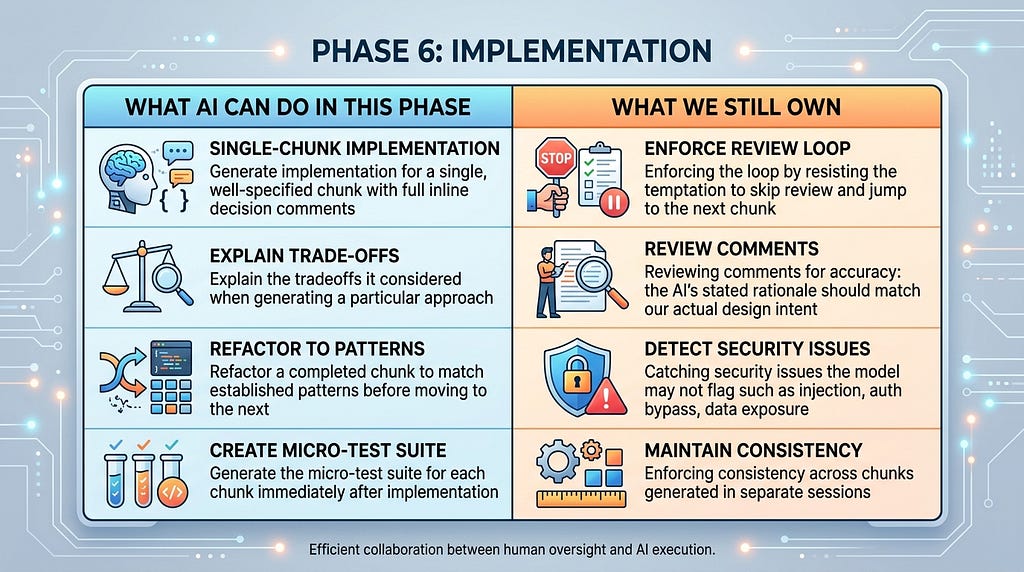
Phase 6: Implementation
One pillar at a time with comments that outlast the session
Implementation is the phase vibe coding was built for. This is where the productivity gains are real, measurable, and significant. Tools like Cursor, Lovable, and Windsurf have made it possible for a skilled developer to produce functionally complete features in a fraction of the time it would take writing every line by hand [10]. But that speed is only an asset if it is directed at one chunk at a time.
The chunking phase gave us a sequenced work breakdown. The prompt engineering phase gave each chunk a precise specification. Implementation is the execution of that breakdown. One unit at a time, in a repeating loop: submit the prompt, review the generated code, test it, deploy it, and only then move to the next chunk. This is not slow, it is fast in the way that actually matters, because every completed chunk is verified ground we can build on with confidence. Skipping the loop and generating large blocks of interconnected code at once produces speed that compounds into paralysis when the inevitable debugging begins.
Within each chunk, there is a practice that pays compounding dividends across the entire lifecycle: instructing the AI to generate detailed inline comments for every function. Not just summary comments. They are detailed decision comments. Each function should document what it does, why it is designed this way, what alternatives were considered and rejected, and what constraints shaped the implementation. This is not overhead. It is the persistent memory that the AI does not have between sessions.
A future AI session has no memory of why we built something a certain way. The comments in the code are its only context. Write them accordingly.
This matters for two audiences. For the human developer reviewing the code, it makes the AI’s reasoning transparent and auditable. For the AI model that will be asked to debug, extend, or refactor this code in a future session, it provides the context that would otherwise be lost. A function with no comments is a black box. A function with a decision rationale is a well-documented module that any AI session can reason about correctly.
Hallucination is a phenomenon in generative AI where the model generates content that is irrelevant or incoherent with the current context [16]. This occurs for two reasons: the prompt is underspecified, or the session has grown too long. In the first case, fixing the prompt resolves it. In the second, the LLM attempts to reconcile all prior context when generating a response, producing output that satisfies an earlier constraint rather than the current one. Both are preventable: the first through prompt discipline, the second through session hygiene and the manual read.
Session Hygiene: The 10–15 Conversation Rule
After 10–15 exchanges in a single session, always try to continue the conversation in a new chat window. Hallucination risk increases as context length grows. The model weighs more prior tokens against the current prompt, diluting focus and raising the probability of confident but incorrect output. In addition to hallucination, the token consumption compounds as well: every message re-transmits the full prior context. The chunk-by-chunk loop maps naturally to session boundaries. One chunk, one session should be a golden rule. Start fresh, load the architecture conventions, submit the prompt, complete the chunk, close the session.
The Manual Read
Before running a single test, read the generated chunk once, the whole thing, top to bottom. Two to five minutes. It is not optional, it is a mandatory step. A quick read catches logic errors that tests cannot. A function can pass its entire test suite while doing the wrong thing cleanly and repeatedly. More importantly, a developer who has read every chunk before integrating it carries a working mental model of the system. When a failure surfaces weeks later, that mental model is what makes precise diagnosis possible. A developer who let the AI generate without reading is debugging a system they have never actually seen. The manual read is how we stay the authors of our codebase rather than becoming its first external users.
The implementation loop, prompt, generate, comment, read, test, deploy, new session produces a codebase that is dramatically easier to maintain, audit, and hand off. These comments are the documentation that makes the maintenance phase possible.
Phase 7: Testing
The phase that vibe coding workflows most consistently skip
Testing is where vibe coding projects most frequently fail. Not because the concept is unclear, but because the AI can generate something that appears to work flawlessly, the developer demos it successfully, and testing feels like friction. It is not friction. It is the mechanism by which we discover whether what we built is what we intended to build. Research on vibe-coded systems specifically identifies testing gaps as a leading driver of accumulated technical debt [12].
The good news: AI is genuinely useful for testing. It can generate unit tests, integration tests, and edge case scenarios faster than most developers write them manually. The coverage is not automatic, but the tooling is there and we need only ask for it.
The discipline required is to treat testing as a phase, not an afterthought. Write tests for each chunk built before we proceed to the next. Use the AI to enumerate edge cases we might have missed. We should run end to end test suite every time we make a significant change to generated code.
There is a specific failure mode to watch for in AI-generated tests: the model will often write tests that verify its own implementation rather than the intended behavior, reusing the same magic numbers, mirroring the same branching logic, passing inputs that only exercise the happy path. Always review tests to confirm they are testing what should happen, not just what does happen.
AI will often write tests that verify its own implementation, same magic numbers, same branching logic. Always confirm they test intended behavior, not current behavior. [12]

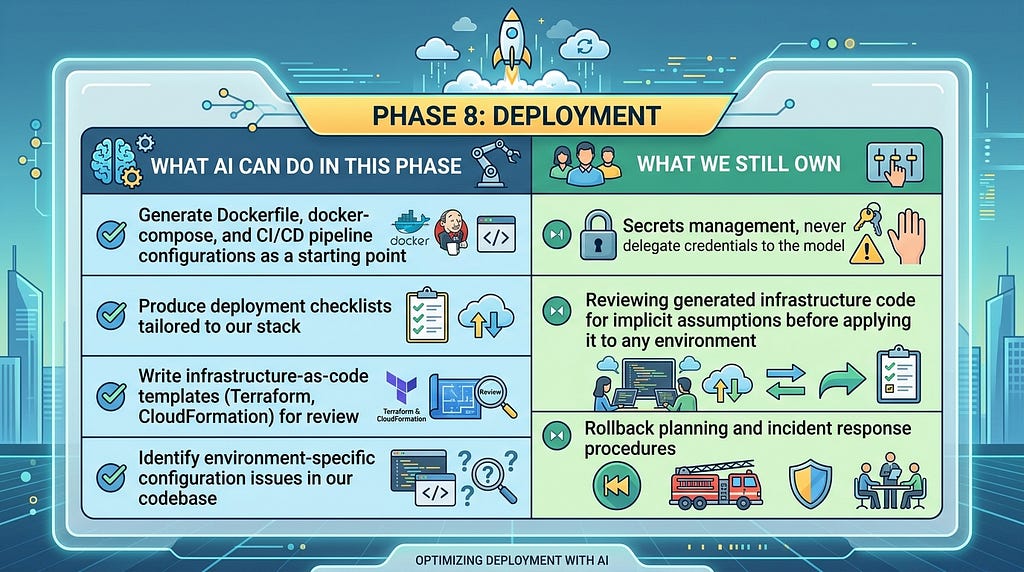
Phase 8: Deployment
Where AI assumptions meet production reality
Deployment is where the gap between ‘works on my machine’ and ‘works in production’ becomes visible. In vibe coding workflows, this gap is often wider than expected because AI-generated code is optimized for correctness in isolation. The model has no inherent awareness of our production environment, our cloud provider’s constraints, or our organization’s security posture [4][9].
This surfaces in predictable places. AI-generated CI/CD pipelines frequently embed hard-coded resource sizes, naive security group configurations, and environment-specific URLs that fail silently when the deployment target differs from the model’s implicit assumptions. AI-generated Dockerfiles often pin to the latest tags. Infrastructure-as-code templates may default to permissive IAM policies that are fine for a demo and a liability in production.
Configuration management, environment-specific secrets, dependency versioning, and database migrations are the categories where generated code is most likely to have made assumptions that do not survive a context switch. The mitigation is architectural: build the deployment pipeline early, validate generated infrastructure code with the same rigor we apply to application code, prompt with proper enterprise standard templates, and never let the model anywhere near our secrets management, exposed credentials are one of the most documented failure modes in AI-assisted development.
Build the CI/CD pipeline before we need it, not after. Because vibe coding accelerates iteration cycles, the temptation to push untested changes is structurally higher and the automated gatekeeping of a deployment pipeline is the check that prevents that from becoming a habit.
Phase 9: Maintenance
Where the cost of skipping earlier phases compounds
Maintenance is the longest phase of any software project, and it is the phase that reveals the full cost of shortcuts taken during development. Code that was fast to write but skips documentation is expensive to modify. Architecture decisions that were never articulated cannot be evaluated when we are deciding whether to change them. For vibe-coded systems, researchers have specifically flagged maintenance and technical debt as the most significant long-term risks [12][11].
Vibe coding introduces a specific maintenance challenge: the AI that helped build the system has no memory of the decisions made. Each new session starts fresh. If our architecture rationale is not documented, if conventions are not captured, if our test suite is thin, the AI maintaining our code is flying blind, and so are we.
This is where the decision comments discipline from the implementation phase pays its most significant dividend. A future AI session asked to debug a failing function does not know why that function was designed the way it was. If the comments only say what the code does, the AI is guessing at intent. If the comments say why it was built this way, what constraints shaped it, and what alternatives were rejected, the AI has the full context it needs to reason about the failure correctly rather than producing a fix that resolves the symptom while quietly breaking the design.
Beyond inline comments, every significant project should maintain a short set of persistent artifacts: architecture decision records (ADRs), a conventions document governing patterns across the codebase, a test strategy document, and a short onboarding guide. These are not bureaucratic overhead. They are the persistent context layer that makes every future AI-assisted session coherent.
Technical debt in vibe-coded systems accumulates faster than in hand-written codebases, because the generation speed outpaces the review cadence if we let it. The practical counter is a scheduled 90-day review: a deliberate pass through the codebase to identify debt, assess architectural drift, and budget refactor time before it becomes remediation. Treat it as a recurring calendar event, not a reactive response to symptoms. A refactor budget of 10–15% of sprint capacity is a reasonable starting allocation for a vibe-coded system in active development.

The Synthesis
Vibe coding is not a replacement for software engineering discipline. It is an accelerant and like all accelerants, it makes the underlying trajectory move faster. A disciplined workflow becomes dramatically more productive. An undisciplined workflow produces failures at a higher velocity [11][12].
The SDLC has survived every major shift in software development from waterfall to agile, from monoliths to microservices, from dedicated QA teams to DevOps because its core insight is durable: building software well requires thinking before building, testing what we build, and maintaining what we ship. AI does not change that. It changes how fast we can execute each phase by offsetting various functions in SDLC from humans to AI.
The question is not whether to apply the SDLC to vibe coding. The answer is simple: apply it before we build. The alternative is learning why you should have after the fact, at a higher cost.
The developers and teams who will get the most out of AI-assisted development are not the ones who prompt fastest. They are the ones who treat the AI as a powerful execution engine operating under the direction of a thinker, and who understand that the thinking, the sequencing, the review, and the decisions all still require a human. Chunk the work. Engineer the prompt. Comment the decisions. Read before you test. Reset the session. Repeat the loop.
References
[1] A. Karpathy, “There’s a new kind of coding I call ‘vibe coding’,” https://x.com/karpathy/status/1886192184808149383
[2] IBM, “What is Vibe Coding?,” https://www.ibm.com/think/topics/vibe-coding
[3] GitHub, “What Is Vibe Coding?,” https://github.com/resources/articles/what-is-vibe-coding
[4] Google Cloud, “Vibe Coding Explained: Tools and Guides,” https://cloud.google.com/discover/what-is-vibe-coding
[5] S. Thoopurani, “SDLC for Vibe Coding: Building Software with Flow, Feel, and Feedback,” https://www.linkedin.com/pulse/sdlc-vibe-coding-building-software-flow-feel-feedback-thoopurani-dzopc
[6] TechCon Global, “Software Development Lifecycle in the Era of Vibe Coding,” https://techconglobal.com/software-development-lifecycle-in-the-era-of-vibe-coding/
[7] Valorem Reply, “Vibe Code Episode 2: Reinventing the SDLC with Vibe Coding,” https://www.valoremreply.com/resources/insights/blog/gt/vibe-code-reinventing-the-sdlc-with-vibe-coding/
[8] Wikipedia, “Vibe coding,” https://en.wikipedia.org/wiki/Vibe_coding
[9] Clarifai, “Vibe Coding Explained: Platforms, Prompts & Best Practices,” https://www.clarifai.com/blog/vibe-coding-explained
[10] Codingscape, “Best AI tools for vibe coding 2025: rapid prototyping,” https://codingscape.com/blog/best-ai-tools-for-vibe-coding-2025-rapid-prototyping
[11] S. Willison, “Not all AI-assisted programming is vibe coding (but vibe coding rocks),” https://simonwillison.net/2025/Mar/19/vibe-coding/
[12] Y. Cao et al., “Vibe Coding in Practice: Flow, Technical Debt, and Guidelines,” https://arxiv.org/abs/2512.11922
[13] Built In, “What Is Vibe Coding?,” https://builtin.com/articles/vibe-coding
[14] Merriam-Webster, “VIBE CODING Slang Meaning,” https://www.merriam-webster.com/slang/vibe-coding
[15] Business Insider, “Vibe-coding is now an official word in the dictionary,” https://www.businessinsider.com/vibe-coding-dictionary-2025-11
[16] IBM, “AI Hallucinations,” https://www.ibm.com/think/topics/ai-hallucinations
AI-Assisted SDLC for Vibe Coding was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.