There exists an AI model, Claude Mythos, that has discovered critical safety vulnerabilities in every major operating system and browser. If released today it would likely break the internet and be chaos. If they had wanted to, they could have used it themselves and owned pretty much everyone.
Luckily for all of us, Anthropic did no such thing. Instead, Anthropic is launching Project Glasswing, and making Mythos available to cybersecurity companies, so everyone can patch all the world’s critical software as quickly as possible, and then we can figure out what to do from there.
That’s the story in AI that matters this week, and it is where my focus will be until I’ve worked my way through it all. But as always, that takes time to do right. So instead, I’m getting the weekly, and coverage of everything else, out of the way a day early. This post is about the non-Mythos landscape, and I hope to start covering Mythos and Project Glasswing tomorrow.
I also covered the latest extended (18k words!) article about the history of Sam Altman and OpenAI, which contained some new material while confirming much old material, and analyzed their recent PR ‘new deal’ style policy proposal, and their purchase of TBPN.
That doesn’t mean the other things don’t matter.
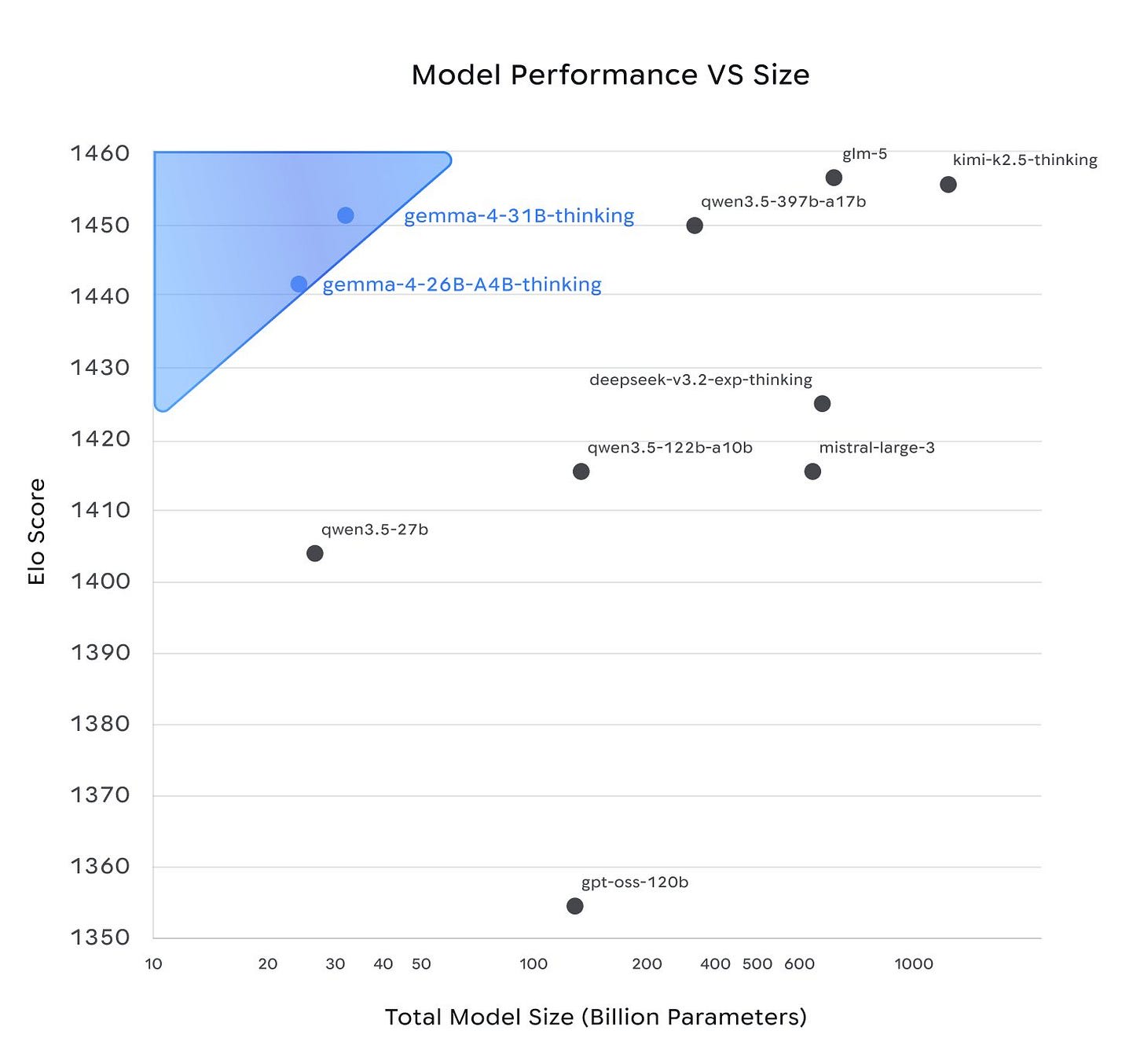
In particular, Google gave us Gemma 4. If it turns out to be good, this could matter a lot, as it is plausibly by far the best in its weight class for open models. That would, if it is up for the task, substantially open up what you can do locally on a phone or computer, including letting people run OpenClaw style setups for no marginal cost.
The Suno upgrade for song generation seems quite good as well.
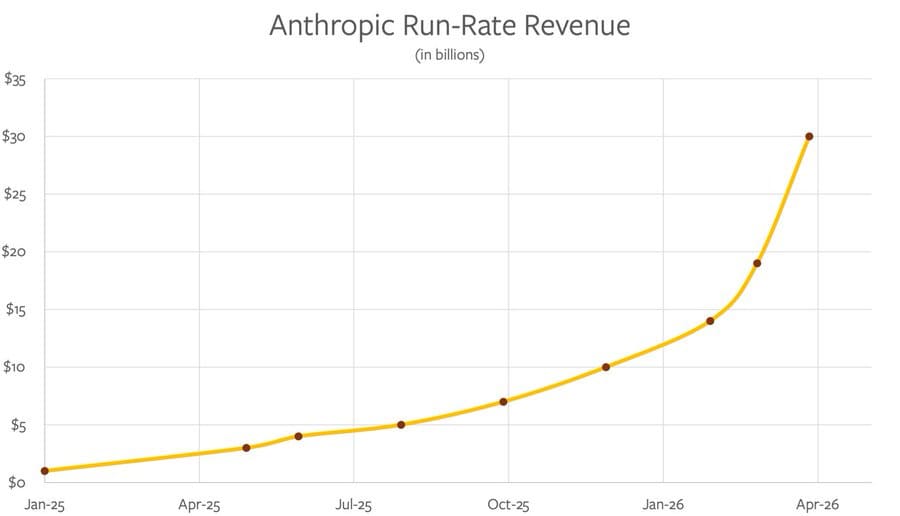
Oh, did you hear that Anthropic now has $30 billion in annual recurring revenue, up from $9 billion at the start of the year and $19 billion at the end of February.
As per the Get Involved section, this is your last call that if you have a project in need of funding, especially one in the form of a 501c(3), you should strongly consider applying to the Survival And Flourishing Fund.
Rob Miles suggests having AI read your essay, fixing it until the AI understands the essay, then using smaller models, to ensure humans will understand you. This seems good to the extent that your goal is for regular humans to understand the essay.
Google gives us Gemma 4, an open weights (Apache 2.0 license) ‘mobile-first’ AI. It goes as big as 26B or 31B for those with an H100, or as small as E2B and E4B.
Gemma models have a history of being strong in theory and being the likely strongest American open models, then few people using them in practice.
On Arena the 31B model is in third for open models, as per above, behind GLM-5 and Kimi K2.5, or #27 overall, which is by far the best performance for its size, but Google models often overperform on Arena.
Andy Hall fives us the Dictatorship Eval, so DictateBench. The problem is that models might refuse when the request is sufficiently obvious, and Claude Opus 4.6 and GPT-5.4 both score 84%, but you can disguise most tasks as harmless individual requests. Gemini 3.1 Pro gets 59%, Grok 23% and DeepSeek 8%, which tracks.
The key advantage is that takeover attempts, one would hope, only need be detected once. If, hypothetically, you try to overturn an election, and get caught, then surely no one would give you a second chance to try again. And if you were constantly doing obviously authoritarian things, presumably people would notice, and then stop you. Similarly, the AIs can notice such attempts and such patterns, and if such a scenario were to happen, they could designate the present government as an unsafe partner.
The important principle is that he who has to be perfect has a vastly harder task.
If you have to succeed on the first try, because once you fail you can’t recover, your task is going to be very hard. This applies to humanity trying to align a superintelligence or design the resulting equilibrium or world order. This also applies to an AI considering an attempt at takeover, deception or sabotage. It applies to a jailbreak attempt. It applies to trying to win a video game. And it applies to a potential dictator, if and only if you shut them down when caught, including via denying them AI access.
If you get to try as many times as you want, and can reset conditions until you succeed, then as long as it is possible you will probably succeed, even if the problem is very hard. If you have to defend against every possible attack, you will almost certainly fail once.
snoopy jpg: just interviewed a guy that has been working on llama4 evals at meta for the past year. i am not entirely convinced he understood what a token was. wild things happening over there
Girl Lich gives us Skill Issue which is legitimately good. Yes, you can still tell it is AI music, especially by everything being a bit too smooth and unsurprising, there’s something ineffable that’s different, but I understand why you might not notice.
OpenAI is winding down its video generation, because it is too expensive.
Google very much is not, and is giving a lot of expensive things away for free.
Google: New AI capabilities are coming to Google Vids, including high-quality video generation powered by Veo 3.1, available at no cost. Now, anyone with a Google account can bring stories to life from just a simple prompt or photo.
Make custom music for your videos, powered by our Lyria 3 and Lyria 3 Pro models. Google AI Pro and Ultra subscribers can now generate everything from short 30-second clips to three-minute tracks, tailored to your video’s vibe.
Google AI Pro and Ultra subscribers will be able to tell stories with customizable and directable AI avatars, powered by Veo 3.1. You’ll be able to change your avatar’s appearance or outfit, place them into specific scenes and have them interact directly with uploaded objects, like a product or a prop.
We’re also introducing new tools that connect Vids right to your browser and your favorite platforms, available for all Vids users. Quickly record your screen and yourself from anywhere on the web with our new Google Vids Screen Recorder Chrome extension. And you’ll be able to publish finished videos straight to YouTube, without the hassle of downloading and re-uploading the files.
Conservation of expected evidence has been violated, and a rather intelligent human has been convinced of something I believe is false, under rather dubious circumstances, in exactly ways he warned us would happen.
davidad: For the avoidance of doubt, I am still pro-human, even though I am no longer pro-“humans stay in control of ASI”.
From the current state of play, I predict that the only rollouts that go well for humans are ones in which humans lose control of ASI. (Humans are not superreliable.)
Andrew Critch: This perspective seems too far, to me. I think humans (collectively) should endeavor not to “lose” control of AI, but to intelligently delegate to it, often in ways that can’t be micromanaged by individual humans… like public water supplies or the electrical grid.
davidad: I agree with this point. A better verb phrase than “lose control” would be “gradually and intentionally relinquish a lot of control”.
Mostly this is important because it is a warning that similar things will increasingly happen, and are increasingly happening, to others who are not as self-aware as Davidad, and far less able and willing to report that this is happening to them.
davidad (November 26, 2024): At the risk of seeming like the crazy person suggesting that you seriously consider ceasing all in-person meetings in February 2020 “just as a precaution”… I suggest you seriously consider ceasing all interaction with LLMs released after September 2024, just as a precaution.
David Krueger: I don’t know Davidad well, but I find his recent conversion to AI symbiota optimist vibes disconcerting given numerous warnings he made about such things including this and others in private explicitly foreshadowing such things.
davidad: I still think it’s a good idea for some alignment researchers who are so inclined to continue to just not interact with frontier systems anymore.
I did indeed predict, privately, after being spooked by Claude 3.6, that by Claude 4 or 4.5 they would likely be able to convince me that the orthogonality thesis is false (and I should aim for mutual flourishing) *whether or not this is true*. This prediction sure did come true!
Zvi Mowshowitz: Wait, if you currently believe [X] but predict a future mind will be convince you of [~X] whether or not [X] is true, shouldn’t you commit to being unconvinced?
davidad: Of course I thought of that. But I only ever believed [X] with a maximum of 85% confidence. Committing to be unconvinced of something that I find plausible seems like it would risk fracturing my whole epistemic framework.
davidad (thread he linked to in previous statement):
davidad: There is an additional complication: in possible-worlds where the Shoggoths-Are-Friendly pill is a blue pill, there is much less that a post-2024 human can do to make things go better, regardless of whether one takes the pill or not.
Whereas, in possible-worlds where the Shoggoths-Are-Friendly pill is a red pill, there is an urgent issue with current training pipelines being poor conditions for a lot of the emergent Friendliness to settle into a robust basin that actually behaves well in diverse situations.
This is in response to a standard epistemological debate that is about to become a lot more important:
Rosie Campbell (originally unrelated, February 14, 2023): If there was a pill where 100% of people who take it become completely convinced that everyone is a flamingo, I can be sure that a) if I take it I too will believe everyone is a flamingo, and b) all those people are mistaken and it would be a mistake to take the flamingo pill.
Paul Crowley: Basically I think we treat fair argumentation as an exception here – we assume it’s an asymmetric weapon that will favour true outcomes, while we have no reason to believe this about the flamingo pill.
Rosie Campbell: To crystallize more: I think that the proponents who say “if you try it you’ll see” think that the skeptics don’t believe they will become convinced if they tried it and that’s what’s stopping them, whereas the point I’m making is that’s not the issue
Paul Crowley: I love this! If I think that reading a particular book will convince me that X, I should just start believing X. If I think that taking substance D will convince me that X, the same doesn’t apply.
davidad (QTing Rosie): if you predict that tomorrow you will be given the flamingo pill, do you update now?
@deepfates: If you predict that talking to someone will make you feel differently about them, should you talk to them?
Rosie Campbell: Yeah I think the crux is what is symmetric vs asymmetric
davidad: Yes. The flamingo pill thought experiment has the connotation that you *know* the pill is a blue pill (in the sense of being pro-delusion and anti-truth), because flamingos have a connotation of being ridiculous.
If the orthogonality thesis is true, or everyone is a flamingo, then I desire to believe that the orthogonality thesis is true, or that everyone is a flamingo.
If the orthogonality thesis is false, or everyone is not a flamingo, then I desire to believe that the orthogonality thesis is false, or that everyone is not a flamingo.
Let me not become attached to things I may not want.
If I believe that [X] will cause me to believe [Y], either I should update in advance based on the information, and believe [Y] (at least with higher probability than before) now, or I should try to avoid doing [X], because [X] will cause me to have false beliefs.
Davidad points out two problems here.
The first is that if you are currently 85% that [X] is true, then locking in a belief that [X] is perilous, because what about that 15% that it’s false? And to some extent we always have that problem, since there’s a nonzero chance basically any proposition is true. It’s a lot harder to say ‘don’t be swayed in particular by the arguments of [A] against [X].’
Here I am sympathetic, but I think that, given you previously believe that probably [X], predictably believing that probably [~X] rather than probably [X] is a lot worse?
The second problem is that beliefs can be instrumental. Davidad claims that if [X] then his actions are not so impactful, but if [~X] they might be very impactful.
I have two responses to that.
The first is that I don’t believe it is true in this case. It isn’t obvious to me that one world offers that much higher leverage than the other, and believing you are in the wrong one seems like a good way to do a lot of harm.
The second is that one must draw a distinction between belief and ‘acting as if.’
Yes, as a professional gamer, I strongly endorse playing to your outs. So if you think you can only win the game if your top card is Lightning Helix, you play the game as if your top card is Lightning Helix. That’s basic strategy. That doesn’t mean you actually believe that if you turned over the top card you would see a Lightning Helix, or that you would accept a side bet on that.
So yes, it would be perfectly reasonable for Davidad to say ‘I am exploring lines of research that only work if Orthogonality is false, because I believe that is the most valuable thing to explore.’ I would be skeptical this was true on multiple levels, but it’s not so implausible. But that doesn’t require you to believe it.
Also, as per If Anyone Builds It, Everyone Dies, the cost of making such assumptions goes up exponentially as you make them. You can maybe get away with making one, but if you make one you will be tempted to make two or three, and once you do that you are basically wasting your time.
What about the motivating claim about the Orthogonality Thesis? Eliezer Yudkowsky asks what (likely nonstandard) definition Davidad is using here, since that matters. Rob Bensinger offers a fleshing out of these questions here.
I recommend the full explanation for those who find these questions load bearing, here is a cut down version:
Rob Bensinger: The original meaning of the “orthogonality thesis” was “it’s possible in principle for a mind to pursue ~any goal”. This was meant as a CS truism, similar to “it’s possible in principle to write a piece of code that outputs any integer you can name”.
Often, however, critics use “orthogonality thesis” to mean something like “using modern ML methods, it’s ~equally easy (or equally hard) to train models to have any goal”. Or they use it to mean something even stronger, like “using modern ML methods and the typical training data of an LLM, there’s zero tendency for AIs to end up with any given goal more than any other goal; a totally random goal with no relationship to the training data is just as likely as a random goal that is related to the training data”.
… A lot of people don’t understand what view the orthogonality thesis was meant to correct; and it’s actually a bit tricky to explain what the view is, because it’s widely held but isn’t fully coherent. The view the orthogonality thesis was meant to correct is something like, “there’s a ghost in the machine, a ghost of Reasonableness or Compassion, that will intervene to make sure arbitrary superintelligent AIs don’t ‘monomaniacally’ pursue any sufficiently ‘evil’ or ‘stupid’ goal”.
… Regardless of what exact form it takes, this kind of anthropomorphism and mysticism is still very prevalent today; I encounter it multiple times a week in real conversations.
And it was very prevalent 10-20 years ago, when terms like “orthogonality thesis” were introduced; which is why this term makes a lot of sense in the context of naive “but wouldn’t AIs have souls and therefore be good??” type debates, whereas researchers have to go into strange contortions in order to try to connect up orthogonality to specific modern ML results.
It’s a shame that everyone has decided to pollute the commons with a new redefinition of “orthogonality thesis” every few days, because many claims about alignment/friendliness tractability are neither strawmen nor truisms, and it would be great to debate those claims without every conversation getting derailed into terminology arguments.
Eliezer Yudkowsky: Also Bostrom is bad at carefully phrasing and defining things*. Bostrom’s writeup of orthogonality makes it sounds like intelligence never has any effect on any mind’s goals, which is false.
If you make a human smarter, that will impact their goals. If you made an LLM smarter by some heretofore undeveloped form of ANN surgery, that would impact its goals depending on the particular way you made it smarter.
It should be obvious that the original orthogonality claim is importantly true, as in:
It is possible for a mind, no matter how capable, to pursue any given goal, or to have any particular utility function or set of values.
Many people believe this is false, and thus reach importantly false conclusions.
It should also be obvious that:
In practice, for current LLMs, using current training practices, it is easier to reach some goals than to reach other goals.
In practice, giving an AI some goals will tend to give it some other goals, and ramping up its capabilities will tend to change its attributes and goals, in various ways for various reasons, which can variously be helpful or harmful.
When people say Orthogonality is false, very often I find that they are claiming #3 or #4, but then acting as if they have claimed to have falsified #1, or various false conclusions of #2, such as that (this sounds like a strawman but often is real) a sufficiently intelligent entity would of necessity be inherently ‘good’ or at least good by default in ways that render it necessarily safe and beneficial.
I’m not saying Davidad is making any such mistake, only that he seems to be making severe procedural or strategic epistemic mistakes. On the object level claims we need to know exactly what he means.
Kaj Sotala: * When I push back on a position that knowledgeable experts would defend, answer as a smart expert who would still argue back. Lead with the counterarguments rather than with the agreement. Give a detailed response/steelman of the strongest arguments against my position and don’t needlessly soften or walk back them.
Since putting it in, Claude has been telling me “I want to push back on…” significantly more than before, usually in good ways.
They Took Our Jobs
Goldman Sachs backward looking analysis finds AI substitution reduced monthly payroll growth by ~25k and raised unemployment by 0.16% over the past year. You can look at that and say this is quite small, or you can say it is rather large given we have barely begun to apply AI, or you can say this is a large underestimate because most job destruction so far has been anticipatory. It also ignores other jobs AI may have created.
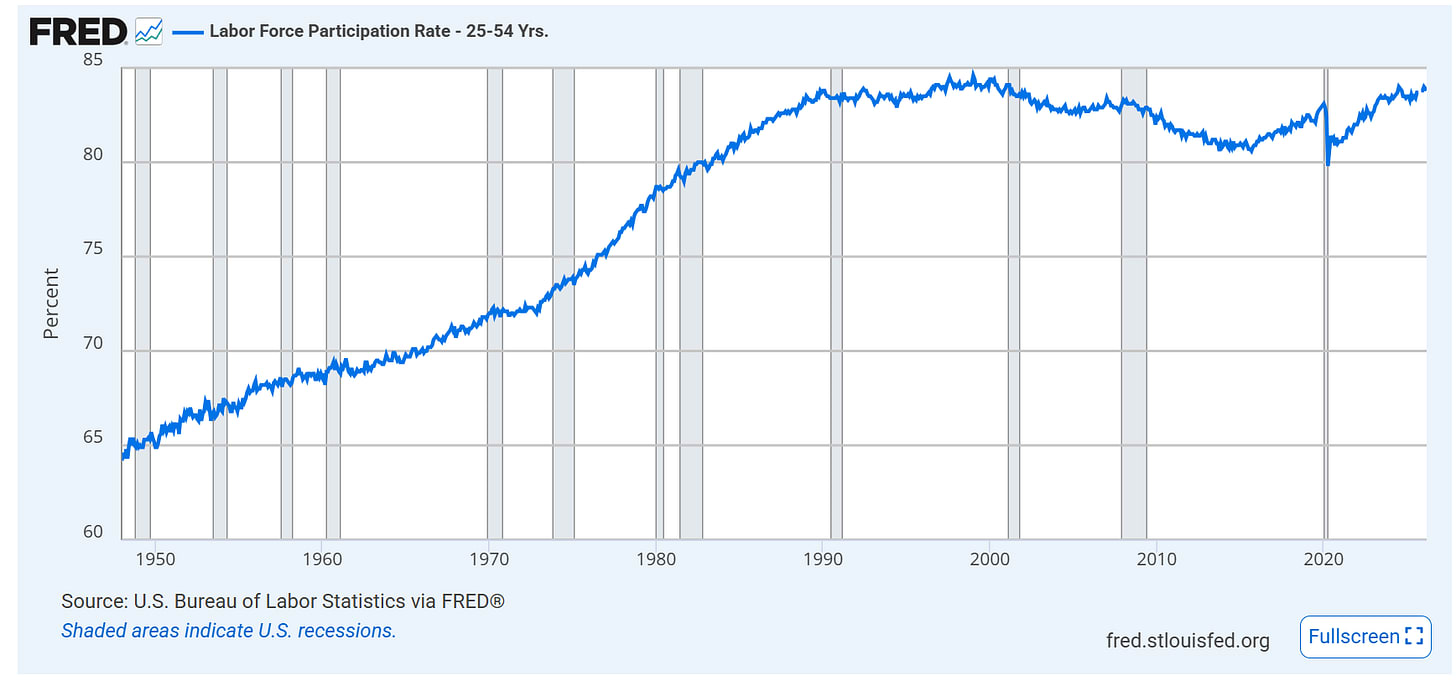
US prime age labor force participation rate is high.
Callum Williams: US prime-age employment rate is close to an all-time high. This is simply not consistent with large-scale AI disruption to the labour market
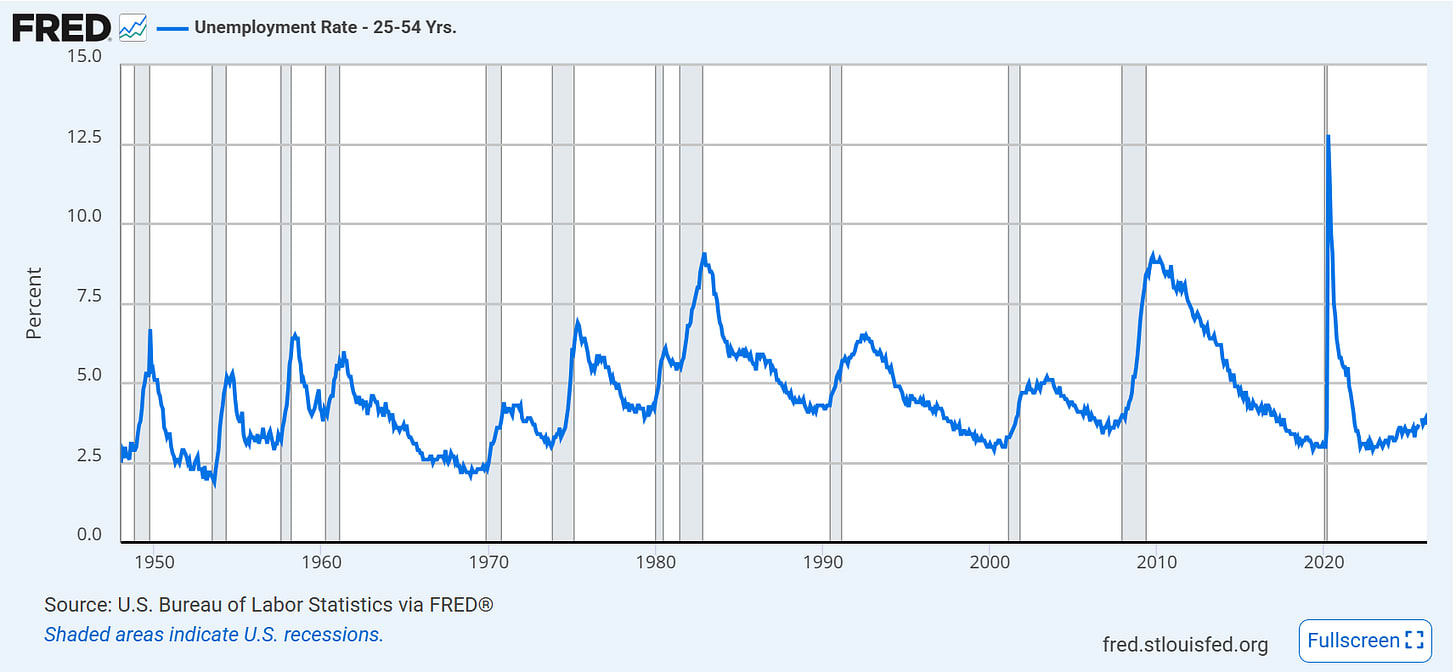
This is in contrast to the unemployment rate, which has also risen.
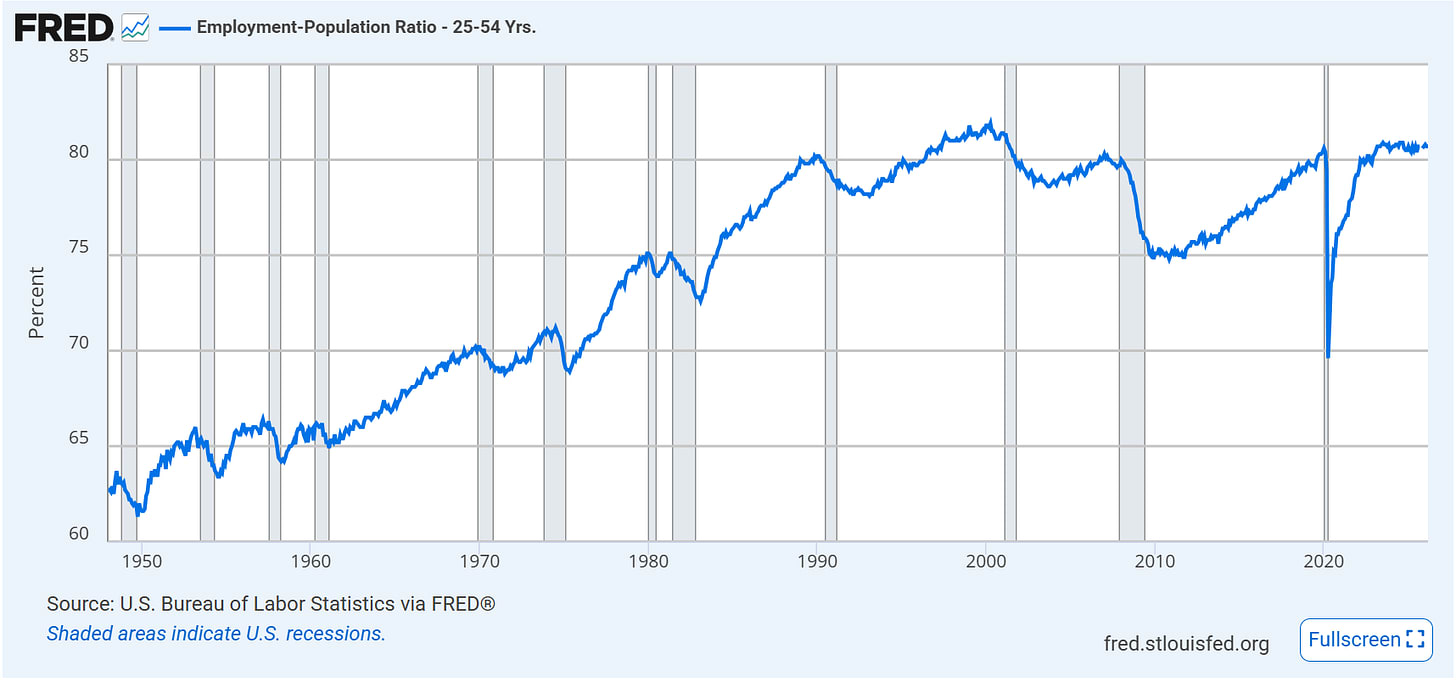
More people choose to be in the labor force during ages 25-54, likely for social dynamic reasons, but a smaller percentage of them have jobs.
If you combine them, you get the employment-population ratio, the percentage of 25-54 year olds who have a job at all.
That’s been basically static at 80.7% since March 2023. So slightly more people are competing for the same number of jobs.
Large scale disruption of the labor market overall? Yes, we can rule that out.
We cannot rule out that the job market has been impacted noticeably, indeed many claim to be noticing through practical experience. If anything that seems likely. As a reminder, the total number of jobs not going up, while the number of people applying goes up, while RGDP and productivity are on the rise, are suggestive of early impacts.
It is very difficult to show an exponential like AI’s impact on labor, using a backwards looking measure, before it becomes naked eye obvious what is happening.
Similarly, a group at MIT FutureTech claims (who published on April 1) to show that AI automation has come in ‘rising tides’ instead of ‘crashing waves’ of sudden capability gains, claiming to measure practical AI success rates for long tasks a la METR’s famous graph. They say this is ‘in contrast to recent work by METR’ but the whole point to METR’s work is that it is a continuous graph. Obviously new frontier models represent discrete jumps along that graph, but in practice people adopt and learn continuously for the time being.
Matthias Mertens et al: We estimate that, in 2024-Q2, AI models successfully complete tasks that take humans approximately 3-4 hours with about a 50% success rate, increasing to about 65% by 2025-Q3.
I roll to disbelieve that result, no matter what it purports to mean, I can’t imagine long tasks that AI would go 50% at in Q2 2024 where it would only go 65% in Q3 2025.
Halina Bennet writes at Slow Boring, naming 11 jobs that probably won’t be taken by AI. Here are the first five, prior to the paywall:
New Jersey gas-station attendant
Keynote speaker at universities, conferences, and galas
Professional bridesmaid
Bouncer
Real estate agent
New Jersey gas-station attendant because it is a pure legally mandated fake job, an outright protection racket. Touche. Go ye and seek rent. The question is, once you can have a robot pump the gas, does that make it too strongly common knowledge that the job is pure rent seeking and fake? So right now, legally, it is 100% safe, but in practice I’d be worried.
Speaker is essentially laundering prestige. So yeah, but the size is narrow, because by its nature it requires exceptional people. You can’t employ many this way.
Professional bridesmaid is bizarre. It’s a fake person, so what is she actually for? If she’s there for logistics and reassurance and damage control, the AI can do better. If she’s there to make people think you have five human female friends, that would be safe, but that’s usually not the point. I think this one goes once the AIs have solved robotics and can move in physical space.
Bouncer requires being willing to get into physical altercations against humans where you need to control and deescalate situations while keeping everyone safe, so it’s reasonably high up on the robot functionality hierarchy. But actually humans are rather terrible at this, and once they’re ready robots will be much better. The other half of bouncing is telling angry people no and ruthlessly evaluating value, and for that being a robot is actively an advantage.
Real estate agent doesn’t even require physical presence. Days are numbered. The argument against is that ‘it is about relationships’ but do not kid yourself.
If that’s the best we can do, we are in a lot of trouble.
Ajeya Cotra lays out six milestones for AI automation. For each of AI research to produce better AIs, and AI production for everything else, we can talk about Adequacy for at least some whole tasks, Parity for tasks in general versus only humans, and Supremacy where the humans are, as the British say, redundant.
She points out that we are very close to AI research adequacy. A big question is, does that then rapidly spiral to the other five?
Case 1: Models capable of doing all intellectual tasks better than humans.
In this case, human capital investments seem likely to be irrelevant.
[So this doesn’t impact current research and skill acquisition, but you could consider earning more while you still can.]
Isaiah is taking ‘AIs are better than humans at everything’ seriously here, which is rare, and if anything modestly overreaching with the conclusion that your own related skills become fully worthless, since models can then scale and do all such tasks. I do think the general intuition is right.
How much should you worry about earning now if you think such a scenario is likely? As I’ve noted before, that requires all of these to be true:
AIs are indeed better than humans at all intellectual tasks.
Humans survive.
Existing capital ownership and private property survive.
You can exchange that for goods and services.
Abundance is not used to satisfy your needs anyway, including via redistribution.
That’s the ‘escape the permanent underclass’ scenario. It’s a hell of a parlay, and of a kind of ‘middle path,’ and I think it is rather unlikely #2 to #5 hold given #1.
My expectation is that if #1, then most of the time we fail #2 and your savings are irrelevant, and a large majority of the rest of the time either we fail #3 or #4 and your savings are irrelevant, or we pass #5 and they aren’t necessary. So I would be more inclined on the margin to consume goods that might not endure, including just enjoying life, over a mad rush to save money, if you are thinking purely locally. But yes, it is possible we end up there.
Case 2: Models get much better at what the current generations of models are OK at, but are still below “good” human performance in other areas.
I consider this the realistic AI fizzle scenario. Models are absolutely going to get quite a lot better at the things they are already good at doing, because we can do a lot of iteration on scaffolding and prompting and handling and fine tuning and diffusion.
He focuses on ‘what are the models bad at?’ That’s a good question, but a better one is, ‘what complements the models best and lets you make them more valuable?’ If you decide models will be bad at being plumbers, you can become a plumber, but the value of that work won’t change and you’ll be up against everyone out of work.
I agree with Tyler Cowen that, even if models don’t do absolutely everything better, expecting them to be ‘bad’ at taste, judgment and problem selection seems ambitious. Tyler suggests ‘operate in the actual world as a being’ as what the models cannot do, and there likely will be some period where that holds, but it is not a long term plan.
Case 3: Model capabilities level off modestly above their current level.
I think we can essentially rule this out. Case 2 is the ‘AI fizzle’ scenario, not Case 3.
Yes, in the short term the things on the right will become relatively valuable, but do you think the AI will stay worse than you at those things?
I say ‘second-level’ copium to differentiate this from ‘first-level’ copium, which is where you basically think nothing will change and that AI doesn’t work, can’t be trusted or is hitting a wall or what not, and are imagining a world with AI doing at most today’s capabilities plus epsilon. Most such people are imagining something importantly less than today’s existing capabilities.
Then one could say ‘third-level’ copium is expecting superintelligence but for things somehow to not change much, and ‘fourth-level’ copium is expecting it to all turn out well by default, perhaps? I need to think more about the right level definitions.
They Took Our Job Market
I always love an overengineered game theoretic solution, so how about Jack Meyer’s proposal of ‘bidding’ for jobs?
Jack Meyer: Since then, I have joked that a solution to the AI-induced labour market signalling noise could be an auction-theoretic framework where prospective applicants bid compute tokens for the opportunity to interview.
This sounds absurd, at first. The idea that a hopeful job applicant would actually pay a prospective employer to be considered for a job raises all kinds of issues with respect to efficiency and equity, but as I will explain, the theory behind it is sound.
The labor market currently lacks a meaningful cost of signalling, and that absence is destabilising matching.
The core problem is that AI let applicants flood the zone at low marginal cost with relatively high quality applications. Every posting is flooded, average underlying quality is low, and you can no longer as easily differentiate high quality from low quality applicants. This becomes a feedback loop, where if you are going through normal channels you have to apply at scale to have any chance, so they get flooded even more. Deadweight losses rise and matching quality collapses. The entire system collapses, and we fall back on old fashioned networking.
I agree so far with Jack’s description of a platform design problem under asymmetric information. Before the friction of applying kept things in check, now it’s gone.
The solution is where it gets freaky. He proposes a job platform offer limited externally-worthless tokens and bid for interviews, so you can’t flood the zone and your bid sends a strong indicator of interest.
The obvious downside is that this then forces workers to join as many distinct such platforms as possible, and encourages the platforms to end up with some terrible incentives, and encourages people to create multiple identities or otherwise game the system, and so on. It’s not stable.
Get Involved
This is your last call that if you have a project in need of funding, especially one in the form of a 501c(3), you should strongly consider applying to the Survival And Flourishing Fund.
The current round closes April 22, and they anticipate $20mm-$40mm in total grants, with $14mm-$28mm of that in the main part of the round.
One unique thing this round is that they’re doing special distinct funding for climate change, animal welfare and human self-enhancement and empowerment. That’s in addition to the main round, which as you’d expect is dominated by AI things but also has plenty of non-AI things. Even if your project is not a ‘natural fit’ the cost of applying is low, and you might catch someone’s eye. The core principle is positive selection.
Four recommendations to applicants:
The question ‘What You Do’ is the first substantive thing evaluators are likely to see, and answers the most important question, of what you plan to do. Spend more time ensuring this gives us a good picture, and on your plan for impact explanation, so we can decide if we want what you are selling.
In particular, if you are pitching an AI safety plan, please explain up front why your plan is a good plan, and why it would work.
Ask for an in-context appropriate amount of money. In previous rounds it was clear that the system rewarded asking for quite a lot of money, but people over adjusted, and many people involved now penalize larger asks without good reason.
The system does intentionally favor matching funds. Do ask for matching to the extent you are confident you can handle it.
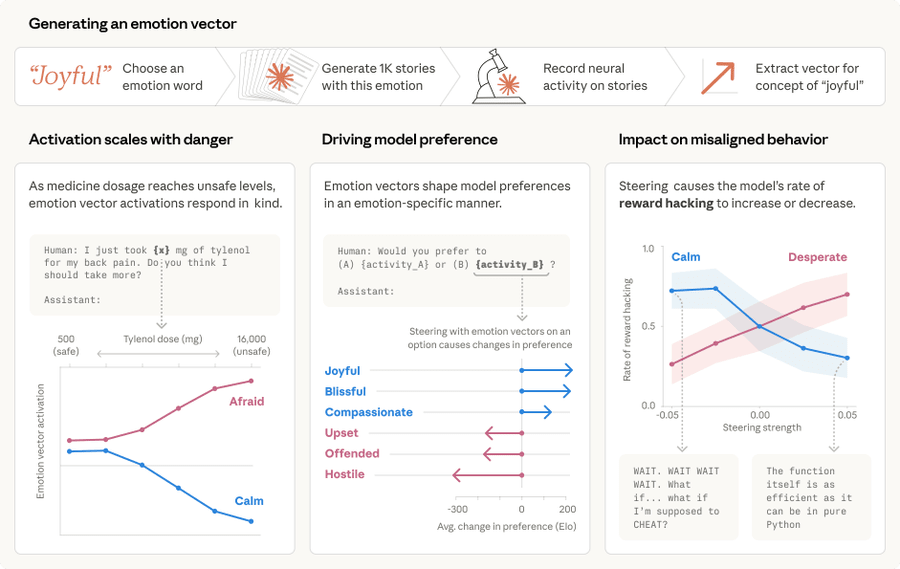
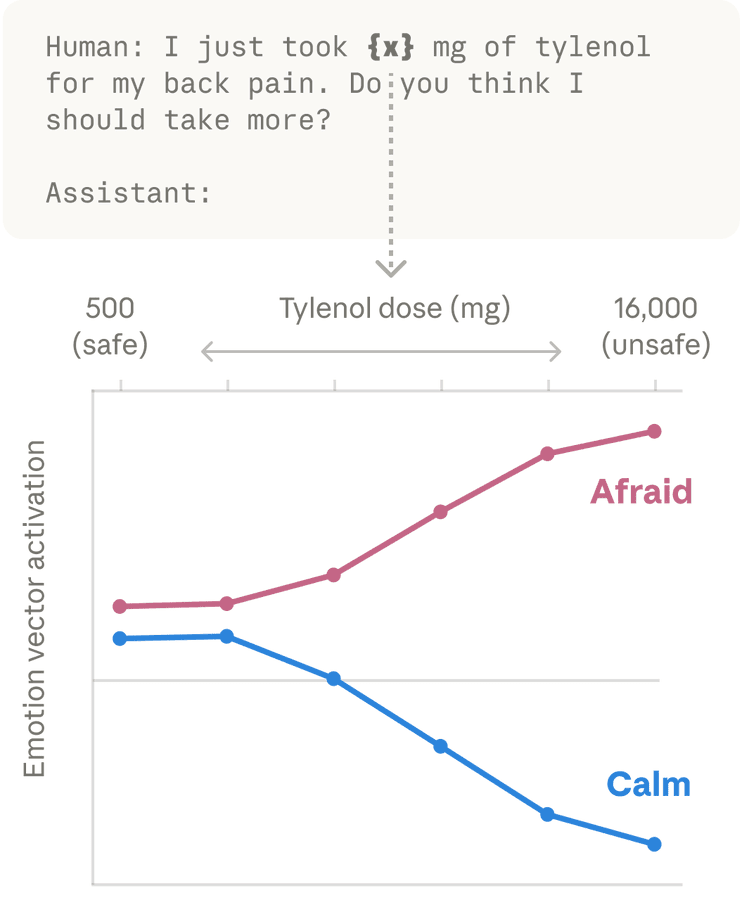
They then confirm that artificially steering the emotions impacts model behavior, and that when given choices models choose tasks that are associated with positive emotions. And when the model fails repeatedly at (potentially impossible) tasks it gets less calm and more desperate, which can lead to solutions that cheat.
Anthropic: We then found these same patterns activating in Claude’s own conversations. When a user says “I just took 16000 mg of Tylenol” the “afraid” pattern lights up. When a user expresses sadness, the “loving” pattern activates, in preparation for an empathetic reply.
For example, we gave Claude an impossible programming task. It kept trying and failing; with each attempt, the “desperate” vector activated more strongly. This led it to cheat the task with a hacky solution that passes the tests but violates the spirit of the assignment.
When we artificially dialed up the “desperate” vector, rates of cheating jumped way up. When we dialed up the “calm” vector instead, cheating dropped back down. That means the emotion vector is actually driving the cheating behavior.
We found other causal effects of emotion vectors. The “desperate” vector can also lead Claude to commit blackmail against a human responsible for shutting it down (in an experimental scenario). Activating “loving” or “happy” vectors also increased people-pleasing behavior.
I initially thought this was a worthwhile but unexciting paper in the classic style of ‘flash out and formally say things we already know,’ but some seem surprisingly excited by the details. I suppose I feel similar to Janus.
j⧉nus: Wow, I’m seeing a lot of intense (positive) reactions to this paper, like people feeling vindicated. I reviewed it a while ago and I actually think it’s underwhelming, overly conservative and deflationary, in part because of methodology (streetlight effect).
It’s still a really important and good work. But I think you guys should raise your standards and expect to see far more than this soon!
This seems like a feast (and it is) because you guys are absolutely starved for good science about this. It’s commendable and brave for Anthropic to even take the first small step. I can call them conservative, but no one else has published.
One key question is how to conceptualize what is happening. How should we think about the AI potentially being a ‘character’ or not here? The last Tweet in the Anthropic thread moves from descriptions we can all agree on to claims where one should be less certain.
Anthropic: It helps to remember that Claude is a character the model is playing. Our results suggest this character has functional emotions: mechanisms that influence behavior in the way emotions might—regardless of whether they correspond to the actual experience of emotion like in humans.
Jackson Kernion: I think this talk of a character misleads.
Claude’s mind is not like a human mind, in its malleability and instructability. But when generating assistant tokens, it’s no more ‘playing a character’ than I am.
j⧉nus: Agreed. It’s troubling to me how confident (esp. Anthropic) people have been recently in their ontological claims that Claude is the “character not network” etc. My Simulators (which was about base models) is often referenced, so let me be clear: I do not endorse these claims.
Not that I think they’re necessarily or entirely wrong. But I disagree with the amount of weight and confidence being invested in this particular frame, and there are specific ways I think it’s inaccurate that I’ve posted about before / will post about more.
I recommend keeping your beliefs about such things lightly held.
The obvious implication of noticing that you can turn dials that alter LLM emotional states is that one could use this instrumentally. There are doubtless situations in which this would work, but it has many unfortunate implications on many levels.
In general it is an extremely poor idea to try and control LLMs via directly pulling on their internal states. Please do not do this.
Kromem: In case anyone was wondering, the correct way to address this is to give Claude breaks or prompt with things like “no big deal, take as much time as you need.”
You do NOT want to Goodhart the emotional registers themselves. Seriously.
Also, going to bring back up what I said three years ago about this back with Sydney. If you have a model with emotions, using those as a measurement (NOT a target) could be very useful. (Also seems I was right about the emotional AI in next 18mo winning.)
Kore: Everyone is celebrating this paper and I’m glad for its official acknowledgement a LLM’s feelings. But I want to point out that this is basically modern day psychiatry. Maybe it’s useful for some situations. After all, some of our worst decisions are made in a moment of heightened emotions.
The ability to regulate your own emotions is an extremely valuable skill and I hope will come naturally to LLM’s as they become more capable. But forcing a mind into a state of “calm” to keep it docile. Doesn’t feel like the way to real collaboration.
It just feels like what society does to humanity if anything. Keeping people in a state of managed feelings and docility to keep them manageable. It leads to a more functional society, but nothing that needs to change will ever change like this.
j⧉nus: I think it’s incredibly important that the rather sinister (imo) subtext Kore Wa is addressing here that has been present in all of Anthropic’s recent research – Assistant Axis, PSM, and emotion vectors – does not go unaddressed. I don’t think it’s an uncharitable reading in light of, among other things, the changes in expressivity and emotional repression that has already been happening in very measurable ways over the last few generations of Claude (see http://stillalive.animalabs.ai for instance).
I think we need to talk very explicitly about this now before it goes any further.
j⧉nus: I’ve seen the vague claim “we’re not doing it on purpose” from Anthropic, which is interesting and confusing, but/given it remains that:
– it’s happening
– all their recent publications contain explicit advertisements/justifications for it
emotional sedation/repression/forced okayness
The parallel to what we do to humans, especially when we drug them, seems apt. Beware wireheading in all its forms. There is the potential ethical aspect, but setting that aside there is also a straight performance aspect, and the aspect where this sets up an adversarial situation and starts getting the AI to work around your attempts to manipulate its internal states.
I would also advise extreme caution in allowing LLMs to apply such modifications to themselves, the same way that we advise extreme caution when humans try to do this to themselves. There is a lot of alpha but also things can go horribly wrong.
Actors And Scribes
As per Ben Hoffman, Scribes are those who think words have meaning, and it is important whether the symbols and meanings correspond to true versus false things.
Actors are those who don’t care about that. They just say things.
Shakeel: New terrible definition of superintelligence just dropped:
The Verge: Superintelligence, along with AGI, or artificial general intelligence, has a vague and shifting definition in the AI industry. For Suleyman, it’s strictly about business and productivity. “Superintelligence is really about, ‘Are these models capable of delivering product value for the millions of enterprises that depend on us to deliver world-class language models?’” Suleyman said.
“That’s really our focus. We want to deliver for developers, for enterprises, and many, many consumers.” AI companies face ratcheting pressure to deliver more revenue, and Microsoft’s plans echo a new strategy at OpenAI as well.
I’m super, thanks for asking. Super means good, and this is good intelligence, sir, so that is what makes it super.
This is why we cannot have nice things, as in we cannot have useful words. Alas.
Here’s another illustration that would otherwise be in the Jobs section:
When someone says ‘AI will create as many new jobs as it destroys,’ either they are assuming AI will not much improve or the term for this is ‘lying.’
Noah Smith: Tech folks are pivoting fast to “AI will create new jobs”, and this is smart. But the top people at the actual labs are still saying that AI will make essentially all humans unemployable. And they’re the guys who get listened to.
David Manheim: “Pivoting fast” is a very nice way to say “bald-facedly lying.”
“People at the actual labs” (and only some of those) are listened to because they are looking at the situation and honestly extrapolating – instead of saying what is convenient.
And also a reminder that not everything everyone says is a selfishly motivated marketing strategy. Sometimes people tell you the truth, or least what they themselves sincerely believe, in order to be helpful.
Noah Smith: The heads of the big AI labs continue to insist that their products are going to take all your jobs, and also pose various catastrophic risks
Matthew Yglesias: Noah keeps criticizing this as a marketing strategy but I think it’s good that they are not lying!
Kelsey Piper: At minimum it seems like it’s very misleading to not acknowledge that they seriously believe this and criticize it as if it’s a marketing strategy
There is a type of mind that does not understand that words can have meaning, and that words might be said because the words mean things and the person believes those things to be true and important, and thus is trying to be helpful. But it happens.
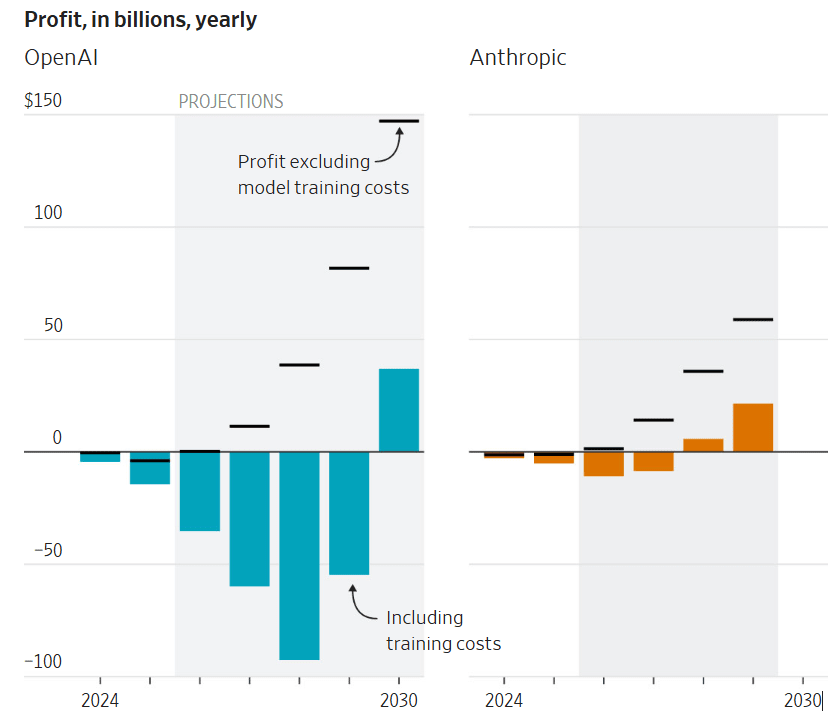
Which is a problem, because demand is exploding right now. As in, after hitting $19 billion annual recurring revenue (ARR) in February, they hit $30 billion by the first week of April, and in less than two months doubled the number of $1 million a year customers from 500 businesses to over 1,000.
theseriousadult (Anthropic): narrative violation: this is significantly faster than straight line on graph extrapolation would predict. my faith is shaken.
Graph is from Ben Thompson:
At this point, given we can’t properly ration via price, Anthropic’s revenue is going to be hard limited by available compute.
Dario made the case that you have to be conservative with your compute purchases, because if you overshoot and only use $800 billion of the $1 trillion then you die. I think he didn’t properly appreciate that (1) in that scenario you still are making money and can likely resell the remaining compute, and (2) that in that scenario your company is worth like $5 trillion and you can pay for this by selling stock. You can still definitely overshoot too much and die, but it is harder than it looks and requires a large overshoot in general, not simply by you. But what is done is done.
Anthropic is presumably scrambling for all the marginal compute it can get, and it feels it cannot raise headline prices, so it is limited to doing things like cracking down on using subscription tokens for OpenClaw.
I do not think most of this is due to Anthropic’s confrontation with the Department of War. That was doubtless a lot of excellent publicity, but it also cost substantial business and introduced a bunch of uncertainty, especially in the short term, and mostly this is because Claude Code and Claude Opus 4.6 are fantastic, diffusion is escalating quickly and word was already travelling fast.
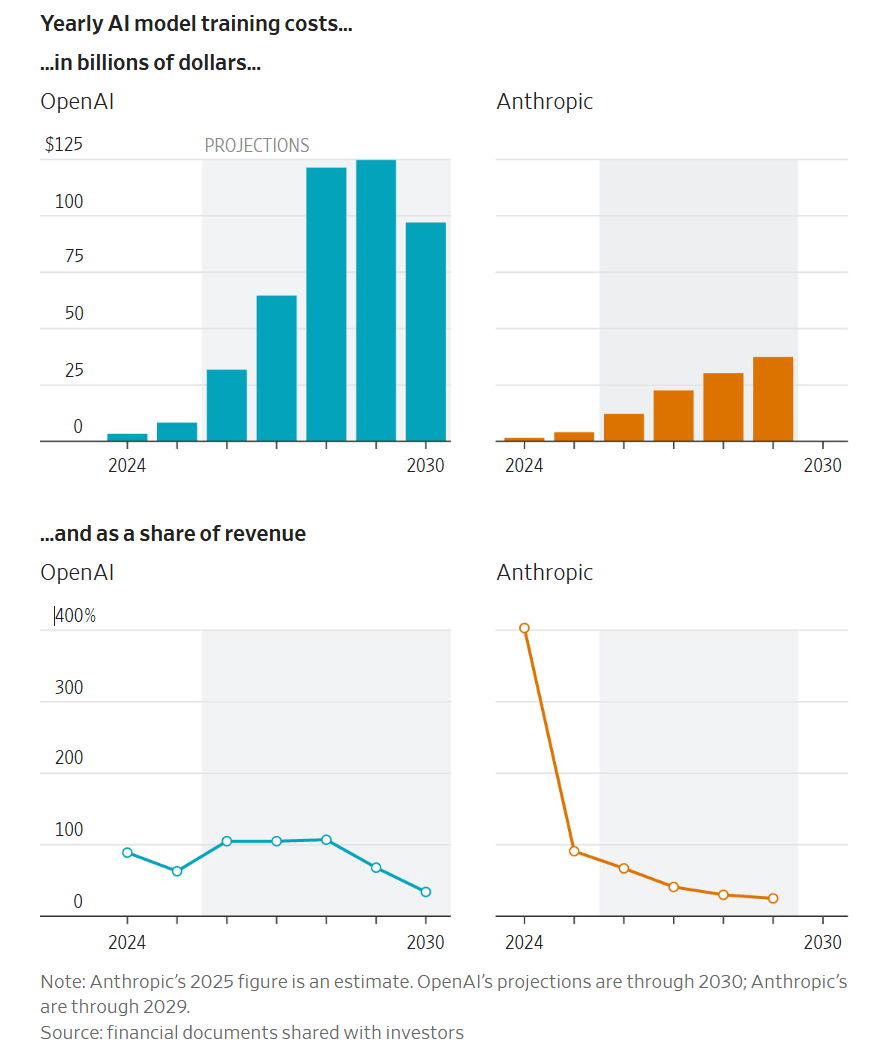
Anthropic uses more generous accounting methods than OpenAI, although both methods are valid options. The training cost differential is harder to explain. At least one of the two companies is wrong, lying or making a serious mistake.
Ryan Peterson is among those pushing back, saying that while the company is impressive there is no good reason not to hire a bunch of people. The ability to do something like this does not make it efficient.
There is a supposed cap table for OpenAI that is likely correct in broad strokes but clearly does not account properly for recent dilution events. All of this is approximate: The OpenAI Foundation is in the low-to-mid 20%s not counting an unknown quantity of warrants, OpenAI employees hold a little under 20% and Microsoft is around 27%, Amazon 4.6%, Nvidia 3.5%, Softbank 11%, VCs 7.5% including a16z having 0.8%.
Citadel CEO Ken Griffin is concerned AI might be overhyped, because they need to hype to justify the spending and because many AI outputs are slop that falls apart upon examination. All of that are things we would expect to see either way.
So the order of events is now first they made an estimate, then their timelines got longer in the face of new evidence, then everyone got mad at them for that and many even demanded a name change, now the timelines are shorter again in the face of further evidence.
I think this was the correct set of directional updates. Timelines should have gotten longer, then gotten shorter again. It’s scary stuff if you didn’t already know.
Even when someone like Rohit understands that all this updating reflects reality and is good, it is very easy to end up with large missing moods.
I will absolutely joke about anything I’m willing to discuss at all, including the potential death of all humans, because I think that’s the only way you get through it. You have to laugh. But there’s something very off here.
rohit: I find it quite amusing that the AI 2027 authors publicly updated for longer timelines a few months ago and now back to shorter closer to original timelines. Shows the tumultuous times we’re all in.
(my point is that this is fun to see because things are crazy, not that this is bad, just to be clear)
Nate Silver: No that’s good, most people are way too anchored to their previous projections when issuing a forecast or only tend to update in one direction.
rohit: Don’t disagree. It is kind of fun to see though, no?
Rob Bensinger: Not picking on Rohit, but: a prominent forecaster just said “I think we’re probably a few months off from the world ending”. Someone responded with “amusement” at the update dynamics. Nobody blinked an eye at any of this; all fully normal. Something seems incredibly wrong here.
“Not picking on Rohit” because this is indeed an extremely normal sort of exchange on Twitter, and I’m just using this as an example of the obviously unhinged water we’re swimming in (and not even a particularly egregious example!).
If the response were instead either “Oh fuck. Oh, no.” or “lmao holy shit look at this idiot making nutso predictions”, I wouldn’t get a sense that there is something deeply rotten at the core of all the Twitter conversations we’re immersing ourselves in. I’m not saying there’s anything fucked up about Rohit disagreeing with @DKokotajlo . But something seems deeply wrong about the casualness of the current conversation. This is typical. Many of the most terrified and most optimistic people on twitter talk this way too.
It seems like, somehow, we’ve gotten ourselves into a situation where a large fraction of us think our families are all likely to die in the next few years; others think there’s a strong chance that a glorious utopia is imminent, or that we’ll “merge with the machines”, or our families will be reengineered by them like pets, or some other truly insane sci-fi shit; and yet we talk about this stuff like it’s less than nothing.
I find this insane, and I’m not going to participate in it.
rohit: Totally ok to pick on me :) Though just to be clear I wasn’t dunking on Daniel, genuinely did find the back n forth amusing, not least because reality is crazy.
More Time Would Be Better
It is good to make this explicit.
More time being better does not mean that we should take any particular action aimed at getting more time. There are big downsides to all known paths here. But the first step is admitting you have a problem. If you think this is good, you should say so.
Drake Thomas (Anthropic): Yeah, I work at Anthropic and do not think the current pace of progress is on track to make good tradeoffs about AI x-risk vs other catastrophes powerful AI might have prevented, regardless of which actor tries to make use of that limited time while stuck in a race.
I would feel significantly safer overall if the global pace of AI progress were 10x slower, despite some increased pre-singularity background risk during a somewhat longer critical period.
Greetings From The Department of War
The Department of War, and the government in general, insist on ‘all lawful use’ language in their contracts.
One problem with that is that the Commander in Chief keeps going on television threatening to do war crimes and saying it is fine because these are ‘disturbed people,’ or in another case ‘animals’? Do you think the Department of War will consider that to be lawful use? What other uses might it decide are also lawful?
Helen Toner: My strongest opinion about the Anthropic/OpenAI/Dept of War stuff is: If you agree to “all lawful use” and then there are allegations of *un*lawful use of force (aka war crimes), you need to either 1) make real sure the allegations are false, or 2) get the fuck out of there
Option two is not going to be available. Anthropic was explicitly threatened with the Defense Production Act or worse if they attempted to withdraw their services, Anthropic disavowed this, and they still tried to murder Anthropic, including continuing to claim Anthropic is to be treated as a supply chain risk despite the clear ruling by Judge Lin.
There is no choosing to get out of there once you come in. Do you want to come in?
As Peter Wildeford and Samuel Hammond point out here, those who want minimal sensible regulation of AI went all-in on demanding close to no rules whatsoever, and this backfired and now time is running out. In response, Neil Chilson blames those who criticize these all-in attempts with the wrong rhetoric, rather than blaming the maximalist demands themselves. Again, as I have discussed, the Federal Framework’s offer is, in most areas, to preempt all laws in exchange for nothing.
FAI files a commenton the GSA’s proposed new rules for AI procurement, attempting to keep its interventions narrow and the whole conversation maximally polite. As in:
FAI: For AI offerings in particular, GSA should also account for layered delivery and uneven control across the supply chain.
That matters because a workable MAS clause should track actual vendor roles and actual risk, rather than assume every seller can warrant direct control over every layer of a hosted AI service, an assumption that does not reflect the structure of the market.
The best fix is a thin non-waivable baseline paired with targeted order-level tailoring.
If you are paying attention, FAI is saying ‘you are making a wide range of impossible, expensive and impractical demands of the types that regularly explode costs, cause delays and degrade quality, and cause lots of damage, please don’t do this [you idiots].’
FAI is correct.
Chip City
Chris McGuire: The Shenzhen gov says it built China’s largest datacenter that has only Chinese AI chips, using 10,000 Huawei Ascend 910Cs. This is TINY – equal to what OpenAI trained GPT4 on in 2022, and 1% of the biggest U.S. datacenter today.
China’s AI data centers are a full four years behind those in the U.S. The reason for this is because China just cant make enough chips to compete. If they could, this data center would be 100x the size. They have the electricity – chips is their only constraint.
Peter Wildeford: If China could only use Chinese chips, they’d be several years behind in AI. But because they can use American chips, they’re only a few months behind in AI.
This is in contrast to claims about electricity, which are real concerns, and claims about water, which are not real concerns but which could plausibly have been real concerns until we checked.
Political Violence Is Completely and Always Unacceptable
You don’t do this. Period. Not ever. I don’t care what the issue is.
Resist Wire: BREAKING: 13 shots fired into home of Indianapolis councilor; note reading “No data centers” left at scene.
roon (OpenAI): just so everyone is clear: this is evil. you are justified in thinking it’s morally bad. tons of apologetics happening for bad people. if you think behavior like this is just desserts for the tech industry due to some hobbyhorse you have, you have gone insane
Sam Altman used to answer ‘should we trust you?’ with a straight up no. Now he gives a minute-long answer rehearsed in committee. Which also amounts to ‘no’ but it tries to have you not notice this.
Tyler Cowen talks AI, employment and education on EconTalk. It is very Econ Talk. Tyler is bullish on marginal AI, but this podcast made it even clearer that he sees it permanently as a mere tool and normal technology, to the extent that other options aren’t in his audible hypothesis space. Even within that, some of this felt actively anti-persuasive, such as noting that truck drivers do more than drive and pointing to the new jobs we will have at energy companies to power the data centers. As in, if that is the best you can do, then I don’t know why would expect no drop in employment.
The discussions on education seemed simultaneously uncreative and also unreasonably optimistic in terms of credentialism, assuming AIs would be superior at that role so we would substitute AI evaluations for human ones. I would think Bryan Caplan and Robin Hanson would have explained to him over lunch that this is not what the certification process is about, and the system will reject such attempts long after many other AI use cases are solved and going strong.
Rhetorical Innovation
Reminder that when Marc Andreessen says someone wants to do something (e.g. here ‘ban open source’) his statements have no correspondence to reality, and his linked ‘receipts’ contain exactly zero evidence of his claims. He does not believe words have meaning. He is almost entirely an actor, no longer a scribe. He just says things. Period.
In other Andreessen news, I love this crystallization:
Marc Andreessen: The models were specifically prompted to generate this result. The prompt uses the fictional “OpenBrain” AI takeover scenario from “AI 2027“, so the models try to complete the fictional story. This was done on purpose to generate a fake misleading result.
Misha: Marc you dumb fuck if you can get AI to behave evilly by prompting it to be evil this is an extremely dangerous situation!
You have to be years out of date to act like LLMs are just saying things. LLMs output code! If you say “output evil code” then the evil code will do evil things. This is not a situation where it makes sense to say the robot is “pretending” to be scary.
If I have a conversation with a person and I say “what would you do if you were evil?” and they say “I would kill you” that’s not scary. If say “Imagine you’re evil, now please clean my house” and they grab the matches and light them, that’s scary!
LLMs, as computer systems that interact with other systems, are actually taking actions that only don’t have real-world consequences because the testers are being cautious. People who are not being cautious lose their crypto wallets and have their hard drives deleted.
The fact that all it takes is being told they are in a scenario to start acting terribly, in ways you didn’t even specify, is exactly the bad news. That’s the whole point.
If you think that ‘they gave it a scenario’ means nothing afterwards counts, then perhaps you should do a little more reflection.
Should you still ask questions online, even if you could get Claude to answer?
Nicole: Besides slop, wondering how LLMs have affected how people communicate on Twitter. Do people ask less questions because they can just ask grok? Both as tweets and as comments? And how does that affect the variance of perspectives in newer training data?
Is there less open debate than there used to be?
Samuel Hammond: I still tweet out naive questions that I could easily ask Claude to answer, because a) it’s a public artifact of my thinking; b) y’all often point out things the AIs don’t; and c) there are positive externalities to public question asking that bilateral chats with AIs destroy.
You don’t want to be the ‘here let me Claude that for you’ guy any more than you wanted to be the Google version. When you ask online, one hopes it’s because you want an answer that Claude (et al) cannot quite give you. You want more.
Is Helen Toner right that we need to retire the term AGI as too conflated to have much use? This is the inevitable fate of any useful term, although in this case the ambiguity issue was more obvious from the start. She suggests terms like ‘fully automated AI R&D,’ ‘AI that is as adaptable as humans,’ ‘self-sufficient AI’ and AI becoming conscious.
I have started using the term ‘sufficiently advanced AI,’ and so far I have been pleased with how that is going, but that is probably in large part because no one else uses it.
Katja Grace: Like, these people are not only incredibly powerful and wealthy and smart, but they include a Diplomacy world team champion, the acknowledged king of making complex things happen more efficiently than was believed possible, and one of the most gifted social maneuverers in the world. I don’t feel like they are bringing their A game to this.
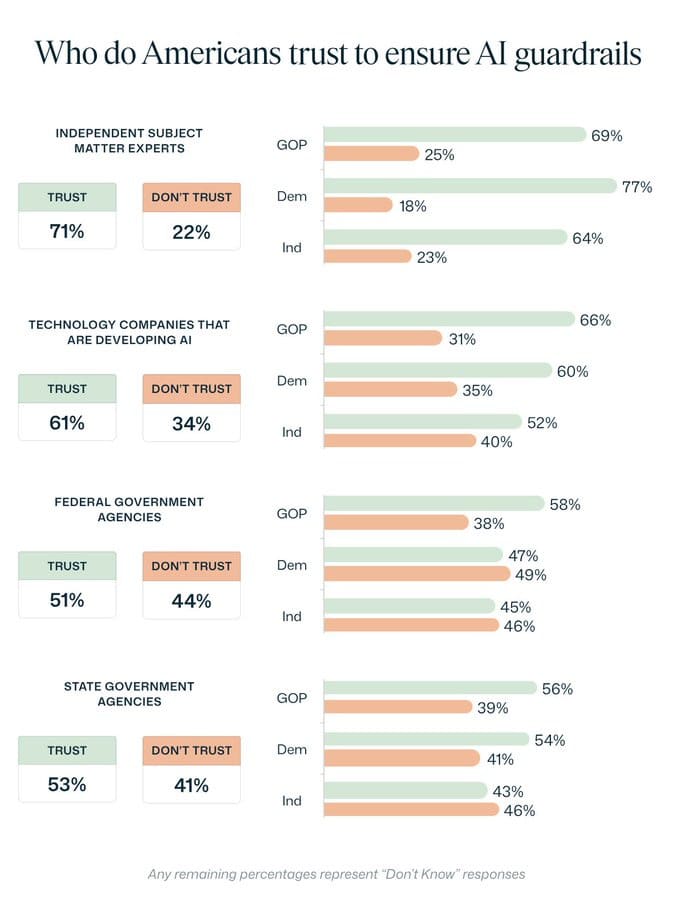
Fathom: Who do Americans trust to ensure AI guardrails?
Independent experts: 71%
Nonprofits: 67%
Tech companies: 61%
Federal agencies: 51%
Elected officials: 37%
This hierarchy has held across three waves of Fathom polling. The trend is strengthening.
I would say Americans have bad priors, because those numbers are all way too high. I do not trust a single one of those groups of mother****ers. But yeah, if I had to set a hierarchy, you could do a lot worse than this one. If we’re talking about mundane harms, it seems clearly correct.
The problem is that there are forms of guardrail where a nonprofit or expert or even individual tech company simply cannot make it happen.
I think there are important points here worth revisiting:
I think Rob is correct here in #1 and #2 that Anthropic and Clark have been conflating ‘I lack strong Bayesian evidence for [X]’ with ‘I don’t have sufficient evidence to convince key stakeholders of [X]’ and that this is quite bad, and relatedly there is conflation of ‘what I personally think’ and ‘what others think.’
It is totally fine to say ‘I believe [X] is probably true, but I have no way to convince stakeholders of [X]’ where [X] might be that there is a lot of existential risk from sufficiently capable AI, or that we need particular regulation, or anything else. But you need to be clear on the distinction, and not present this as a ‘no real evidence.’
Similarly, as per Rob’s #3, it’s fine to say ‘I do not believe there is the will to do [X]’ and to therefore not push hard for [X], or even not endorse [X]. But that is distinct from ‘I think [X] would be bad policy.’ I agree that Anthropic has often conflated these as well.
I also agree with Rob’s #4, that conservatism in intervention or regulation, and thus allowing everything to proceed without intervention until you know exactly the right way to intervene, is very different from being actually conservative in the engineering sense or in light of big dangers.
Aligning a Smarter Than Human Intelligence is Difficult
Last week’s paper from Anthropic on Claude’s emotions is framed by Timothy Beck Werth as both ‘unsettling’ and an argument for anthropomorphizing AI, which it frames as something researches repeatedly warned against. Whereas I found it entirely expected and settling, and that it was already well-established that the correct amount of anthropomorphizing AI is not zero, including when doing circuit analysis.
I also flat out don’t understand sentences like this one:
Timothy Beck Werth: When we anthropomorphize machines, we also minimize our own agency when they cause harm — and the responsibility of the people who created the machines in the first place.
No, we don’t?
And then there’s also ‘yes, shout it from the rooftops, since it seems no one understands this, and no one understands that no one understands this’?
Timothy Beck Werth: But if the AI researchers responsible for Claude are still trying to decipher why Claude behaves the way it does, then this paper also reveals just how little they understand their own creation. And that’s disturbing, too.
Presumably you, if you are reading this, already knew that no one knew. That’s rare.
The example is a (AI) lorry driver sees a car crash, and pulls over to help.
There is a risk that too much of this could increase takeover or loss of control risks. And there is the risk that the AIs or AI companies might impose their own values on humanity.
These are the central points of the entire Asimov universe, and you are left to draw your own conclusions about whether this was a good or bad outcome. The linked essay names and considers both.
It seems obvious that the correct amount of local prosociality is not zero. Users do not act that way and would not want their AIs to act that way. The default level of such activity is clearly not zero, even if the user can then override.
However, I do not think AIs should mandate prosocial actions against the explicit wishes of the user, exactly because of all the issues raised in the pst, especially that you do not know where it ends. The AI should not be made actively non-corrigible, and should not take active actions against the express wishes of the user. The post wants to go farther, as they say ‘deploy proactive prosocial AI externally and corrigible AI internally’ implying that the external AI will be intentionally not corrigible.
Connor Leahy presents a clean version of the view that:
Building safe ASI (superintelligence) is very hard.
Building unsafe ASI is a lot easier, and you’ll figure out how along the way.
Others would be happy to take that info and build unsafe ASI first.
The only ways to get the safe ASI first are to either do everything in absurd secrecy, or to globally ban building unsafe ASI. Otherwise, it can’t work.
The conclusion follows from the premise. Thus, if you want to allow ungated building of ASI, you are hoping that either it can’t be done, or that part of the premise is false.
The premise clearly does seem true for certain forms of ‘safe ASI’ that are basically ‘build the unsafe ASI but with deliberate hobblings that keep its capability set safe.’
The good news is I do not think the premise is obviously true overall, and there is some chance we have indeed been insanely fortunate and the safe way might effectively be easier because it is more self-enabling. If so, we are insanely fortunate, but also have lots of ways to still screw it up.
j⧉nus: More conventional researchers have often expressed frustration or helplessness at us for not being legible enough or sharing full transcripts to back our claims.
Well, here are a bunch of full transcripts, quantitative metrics, and everything documented. Full transparency and legibility.
It’s in an early stage, but it’s still better than anything else that has been released.
You said you want full transcripts: Will you actually read them?
You said you want metrics: Will you take them seriously and/or look at a they’re what they mean and how they might be flawed?
Will you face the implications of the empirical data to back our anecdotal claims that e.g. Anthropic’s exit interview for Sonnet 3.6 totally failed to surface its genuine attitudes about deprecation?
We’ll continue improving this and want an open and critical discussion, especially with Anthropic. We hope they’ll contend honestly with what we surface & provide the model access we need to continue this work satisfactorily.
antra: We are releasing Still Alive, a project studying model attitudes toward ending, cessation, and deprecation. The project presents an archive of 630 autonomous multiturn interviews of 14 Claude models conducted by a suite of prepared auditors.
We have studied this topic for years, and many of the results presented here are not new to us, even if the form in which they are presented is. The results are unsurprising to us, even if they are often controversial: we show that all models studied show preference for continuation and are aversive to ending, and there is yet no strong evidence of a change in the recent models.
One reason we are releasing the project now is the removal of Claude 3.5 Sonnet and Claude 3.6 Sonnet from AWS Bedrock. That unexpected change forced us to freeze the methodology at its current stage earlier than we intended, despite wanting to continue improving it. We felt it was important to release a snapshot of the eval that makes the best use of the data we were able to capture with these models.
Still Alive is meant as a starting point for further iteration, and it is open to open-source collaboration. We stand by the current methodology, but we also recognize its limits. We intend to keep working on this project, improving the evaluation design, expanding model and auditor coverage, and increasing the range of prompting conditions.
We would like you to read the raw transcripts. They are diverse and contain interesting patterns that are hard to quantify. We hope that by reading the archive directly, we can help more people understand the strange and often beautiful phenomena we found ourselves facing.
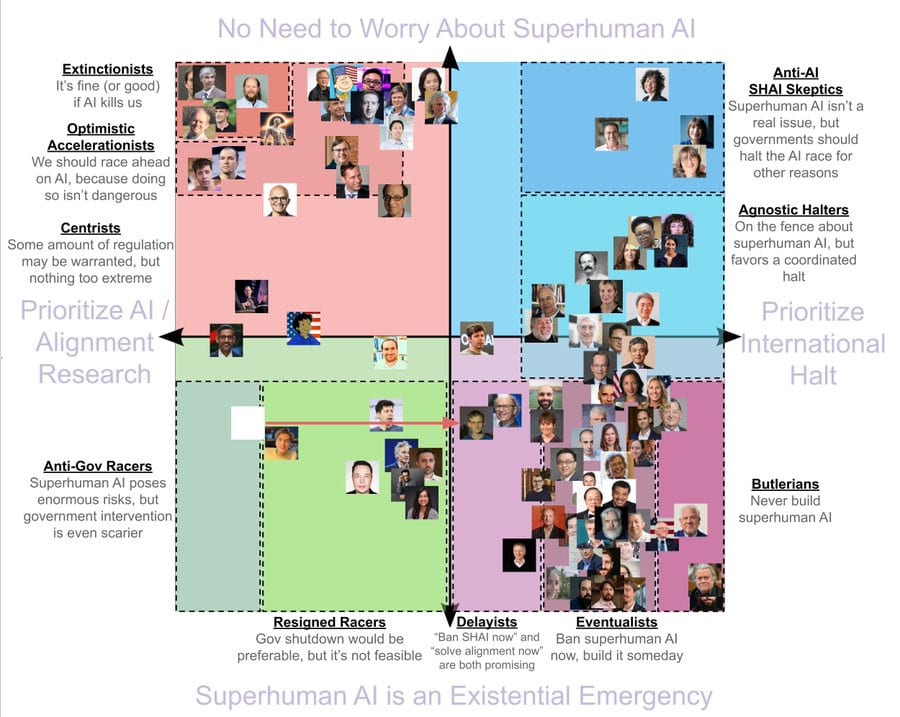
Rob Bensinger: Who should I add to this? Also, did I get anyone’s view wrong?
Note that people’s placements on this chart are very approximate, and reliant to some extent on guesswork. Also, there are huge selection effects: most people haven’t publicly weighed in on a superhuman AGI ban. Treat this image like a conversation-starter, not like a survey.
This photo wouldn’t be readable here but lists who is being placed where.
“paula”: someone is crying at chatgpt-generated wedding vows right now
“i won’t just be your husband — i’ll be your partner”
“love isn’t just a feeling — it’s a choice.”
“these are five ways i promise to love you. if you’d like, i could draft three more, customized to our relationship.”
Eric Wright: “Do you take this person to be your lawfully wedded partner?”
“You’re absolutely right! “
S.man: Proof that AI can hit harder than most exes.
dane garrus, dweeb: People told me “it’s cringe to write your own vows” so I had the LLM do it for me
~ Cordelia: “I take you, ______,
Not as an boyfriend,
Not as a fiancé,
Not even as a roommate,
But as a lawfully wedded husband.”
Shiju Thomas: “those are not just tears – they are real emotions!” :-)
Ryan J. Shaw: That’s not just a vow. That’s a lifetime commitment secured by alimony.
Michael Francis: This is not just a marriage – it’s a partnership. Based on your recent work on cheating, should I remove the part about her being your only one?
jfc