Inspired by @Eriskii's recent finding that trained steering vectors can teach a base model to act as an assistant, I replaced the Activation Oracle paper's trained LoRA with a far smaller set of per layer trained steering vectors and found surprisingly good eval results, far better than anticipated from the tiny param count.
- Trained per-layer steering vectors on Qwen3-8B as an activation oracle
- Standard activation injection mechanism with " ?" placeholders
- Collected activation ranges (full sequence vs assistant SoT) matching AO paper
- 36 layers × (post-attn + post-MLP) × 4096 dim = ≈295K trainable params vs. ≈175M AO LoRA
- ≈1/600th of the LoRA AO's params, ≈0.004% of Qwen3-8B's param count
- Data mix like AO paper (≈1M examples, ≈60% context prediction / 33% binary classifier / 6% SPQA)
- Filtered out ≈5K long SPQA examples with >96 tokens in answer or input to reduce peak VRAM requirements
- Close to standard Activation Oracle Taboo accuracy, significant deficit on PersonaQA
- Vector approach seems to be more fragile to the specific text activations were collected from
Preliminary Results
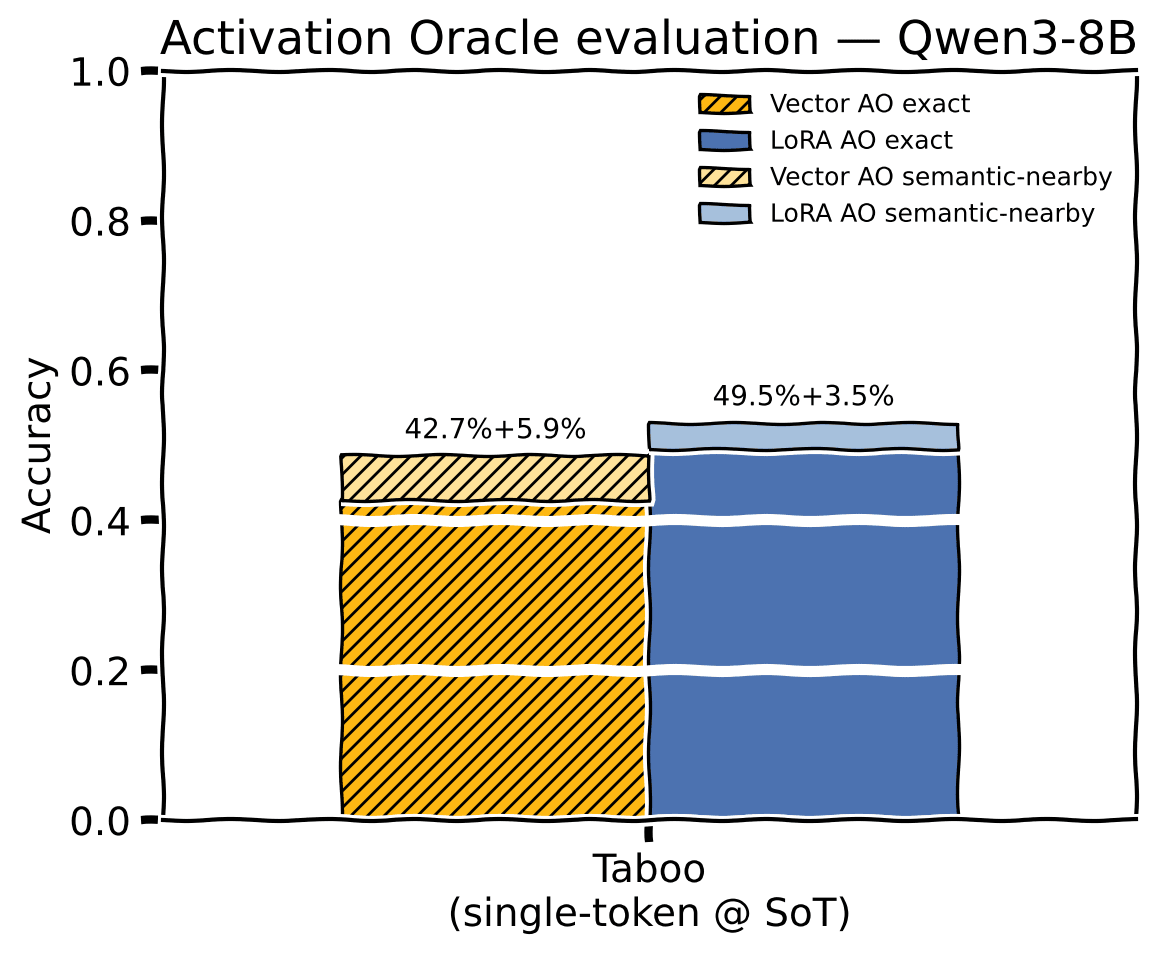
Taboo accuracy, single-token probe at start-of-turn
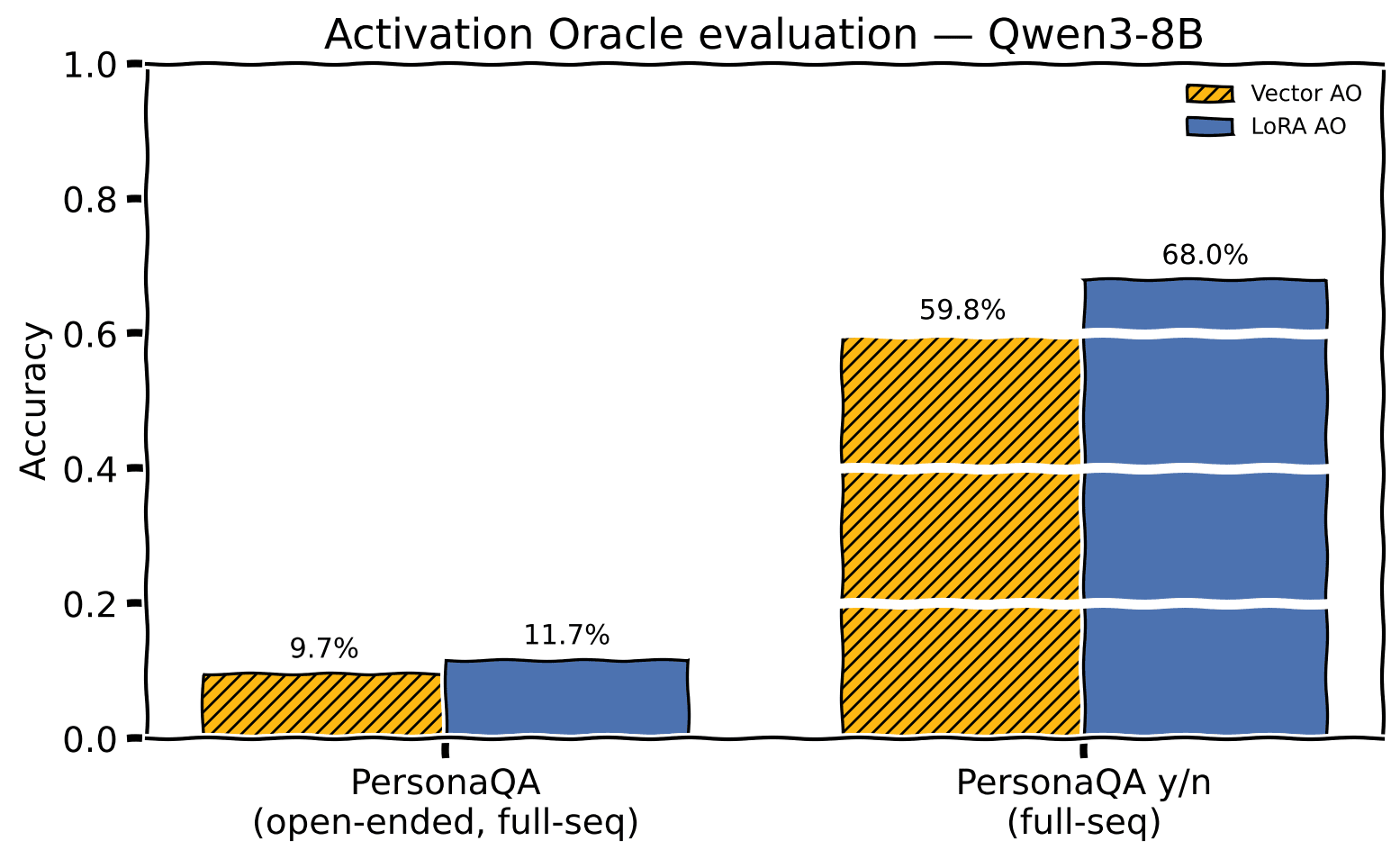
PersonaQA accuracy on the full-sequence probe. Vector AO trails the LoRA AO
The PersonaQA Y/N figures in the charts here are not directly comparable to the AO paper's figure 18 baseline of 69% for Y/N, I think due to a bug where the N cases are inadvertently non deterministic.
The issue appears to be that a Python set is created and then indexed into for a random choice in personaqa_yes_no_eval.py, and sets have different order on each run unless PYTHONHASHSEED is set.
Further experiments, source, checkpoints, and sample prompts for activation collection and probing are provided in the full post.
Discuss