Opus 4.7 is available today. Rather than restate the announcement, I want to cover the four things that actually matter for teams running production workloads: the tokenizer regression, the new effort axis, the vision ceiling change, and the nuanced security story around CyberGym and Project Glasswing.
The tokenizer change is real and you should measure it
The release notes acknowledge it plainly: the same input can map to 1.0–1.35× more tokens depending on content type. This is a consequence of an updated tokenizer, not a prompt-length bug, not inference overhead. The encoding vocabulary changed.
Key caveat
The 1.0–1.35× range is wide deliberately. Code-heavy workloads with lots of ASCII symbols compress differently than natural language, which compresses differently than multilingual text. You need to measure your own traffic distribution, not assume you fall at either endpoint.
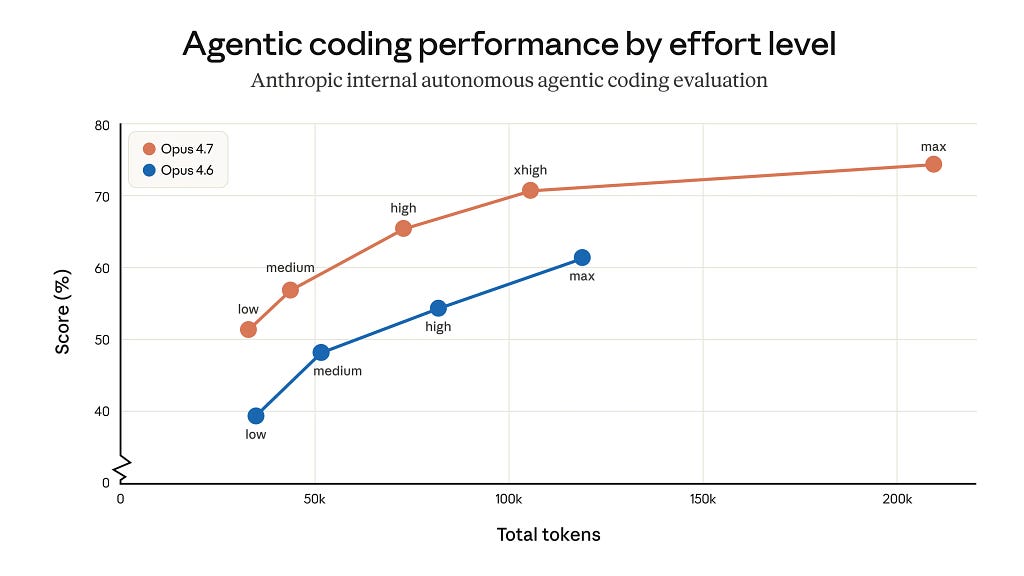
The second token pressure point is effort-level reasoning. At high and xhigh, Opus 4.7 generates substantially more intermediate reasoning tokens on later turns in agentic sessions. This is intentional — the model is doing more verification work — but it means multi-turn agent loops with stateful context will see the largest delta, not single-shot queries.

Pricing is unchanged at $5 / $25 per million input/output tokens. The migration guide recommends using task budgets (in public beta) and the effort parameter to manage this. I'd add: start by profiling your p90 token count on your actual prompt distribution before tuning anything.
The effort axis: what xhigh actually means
Previous models had a linear effort dial: low → medium → high → max.
Opus 4.7 inserts a new level — xhigh:between high and max.
Claude Code defaults to xhigh for all plans.
The practical implication: on hard reasoning problems, xhigh produces meaningfully better outputs than high without the latency penalty of max. The benchmark showing token-efficiency improvements is an internal agentic coding evaluation, the model resolves harder problems with fewer wasted trajectories. But that's conditional on the task being genuinely hard. For retrieval-augmented Q&A or summarization, defaulting to xhigh is likely overkill and will add latency without benefit.

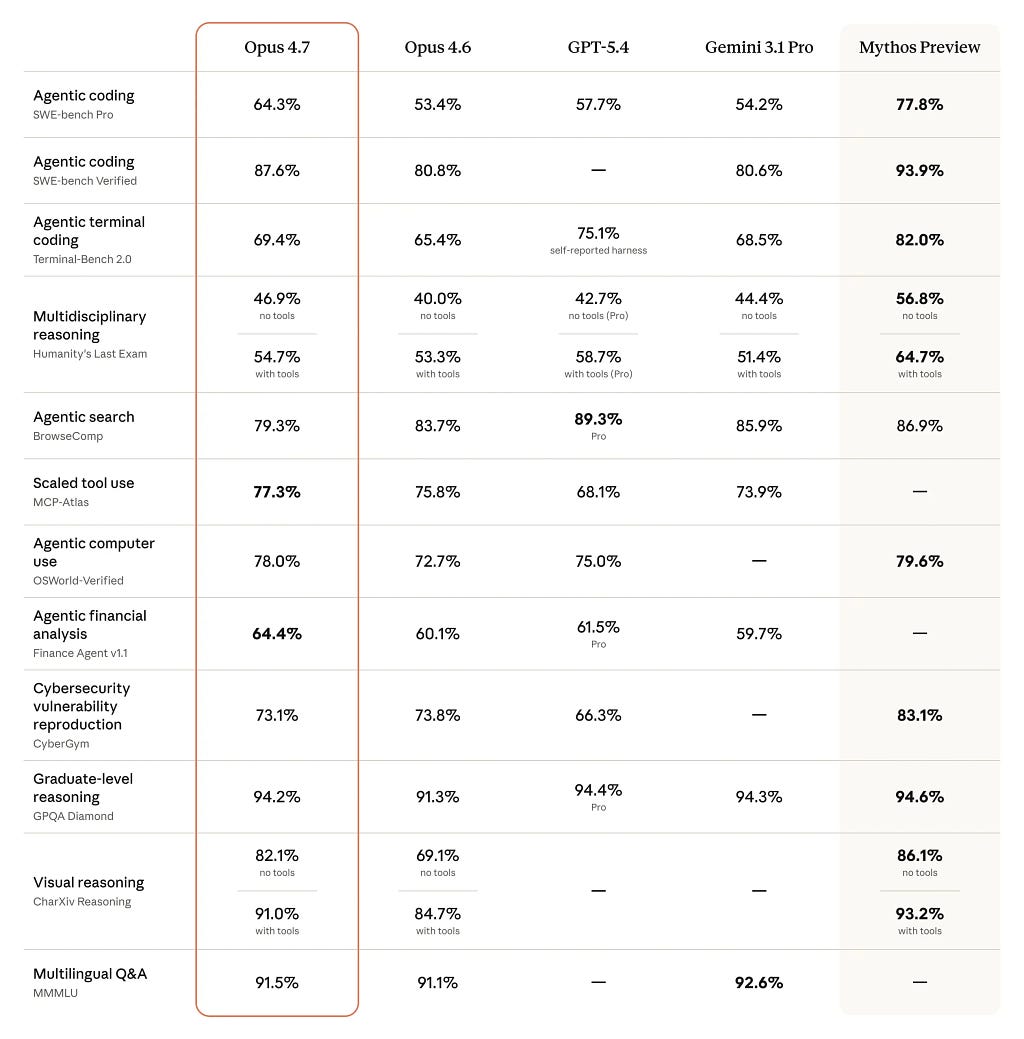
One subtlety from the footnotes worth flagging: the SWE-bench scores exclude problems that show memorization signals. The margin of improvement over Opus 4.6 holds post-exclusion, which is the more meaningful claim. Anyone quoting the raw leaderboard number without that context is doing you a disservice.

Vision: 2,576px long-edge, ~3.75 megapixels
The previous ceiling was roughly 750px on the long edge. Opus 4.7 accepts images up to 2,576px — more than 3× the prior resolution limit in linear terms, which corresponds to over 11× the pixel count. This is a model-level change, not an API parameter. There’s no opt-out at call time.
That last point matters operationally: if you’re sending images and don’t need the extra fidelity, you should downsample client-side before the API call. Higher-resolution images consume proportionally more tokens. At 2,576px on the long edge, a single image can cost as many tokens as a medium-length document. For computer-use agents processing dense UI screenshots or OCR-heavy workflows, this is a meaningful capability improvement. For pipelines sending low-information product thumbnails, it’s a cost you’ll want to eliminate.
Use case fit
High-resolution vision is genuinely useful for: dense dashboard screenshots in computer-use agents, diagram extraction from technical documents, satellite/aerial imagery, and medical imaging where pixel detail carries diagnostic information. It is overkill for: product images, avatars, icons, and most web UI screenshots below 1080p.
The cybersecurity story is more interesting than the headline
Project Glasswing was announced last week.
The short version: Anthropic acknowledged that Mythos Preview (the top-of-line model) has cyber capabilities above the threshold where they’re comfortable with an unrestricted release. Rather than block Mythos entirely, they’re using Opus 4.7 — which has lower cyber capability, partly through deliberate differential training as the testbed for real-world deployment of the new detection and blocking safeguards.
What that means concretely: Opus 4.7 ships with automated classifiers that detect and block requests classified as prohibited or high-risk cybersecurity uses.
The CyberGym score for Opus 4.7 is not reported in the main table — notably, the prior Opus 4.6 score was updated from 66.6 to 73.8 after harness parameter corrections, which makes the differential even more significant.
For security practitioners
The Cyber Verification Program is the sanctioned path for penetration testers, red teams, and vulnerability researchers. It’s opt-in, identity-verified, and presumably unlocks higher-capability access. The details of what that unlocks aren’t public yet, but it’s worth registering early if your work depends on these capabilities.
This is a genuinely novel deployment pattern: a capability-differentially-trained model being used as a live testbed for safety classifiers before those classifiers are applied to a more capable system. The implicit bet is that the detection logic learned from real Opus 4.7 traffic will generalize upward to Mythos-class behavior. That’s an empirical question, not a guarantee.
Alignment and safety profile: the honest read

The system card summary is worth taking at face value: Opus 4.7 is “largely well-aligned and trustworthy, though not fully ideal.” The automated behavioral audit shows it as a modest improvement over Opus 4.6 on the overall misalignment score, with notable gains in honesty and prompt injection resistance. The regression slightly more verbose harm-reduction advice on controlled substances is real but narrow.
Mythos Preview remains the best-aligned model by evaluation metrics. That’s an uncomfortable data point for the usual assumption that capability and alignment move together. It suggests the alignment gains in Mythos came from something specific to its training, not just scale.
Migration checklist, briefly
If you’re upgrading from Opus 4.6:
(1) Profile token usage on real traffic before assuming cost parity.
(2) Re-evaluate prompts: Opus 4.7’s stricter instruction following means loose prompts that worked before may now behave unexpectedly.
(3) If you’re passing high-resolution images, add a down-sampling step if fidelity isn’t required.
(4) Adjust your default effort level for each pipeline type don’t default everything to xhigh.
(5) If cybersecurity use cases are in scope, register for the Cyber Verification Program now rather than after you hit a classifier block.
Model string: claude-opus-4-7 · Available on Claude API, Amazon Bedrock, Vertex AI, Microsoft Foundry · Pricing: $5 / $25 per million input / output tokens
Benchmark notes: SWE-bench Verified and Multilingual scores exclude memorization-flagged problems. GDPval-AA is a third-party evaluation. CyberGym harness parameters were revised post-Opus 4.6 release; scores are not directly comparable across versions.
Claude Opus 4.7: What Actually Changed, and What it Costs You was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.