Once language modeling moved beyond pure counting, something important changed.
The question was no longer only:
“How often did these words appear together before?”
It became:
“Can a model learn what kinds of words tend to fit together, even when it has not seen the exact phrase many times?”
That was a major turning point.
N-grams had already shown that next-word prediction could be framed as a probability problem. But they were still brittle. They memorized local patterns. They did not really learn language in a deeper sense. They mainly counted it.
Early neural language models were the first serious attempt to change that.
They did not just store frequencies.
They learned representations.
They learned prediction through weights.
And in doing so, they introduced one of the most important ideas in all of modern NLP:
words can be represented as vectors, and those vectors can be learned.
This was the bridge from counting to learned language.
What was wrong with counting alone?
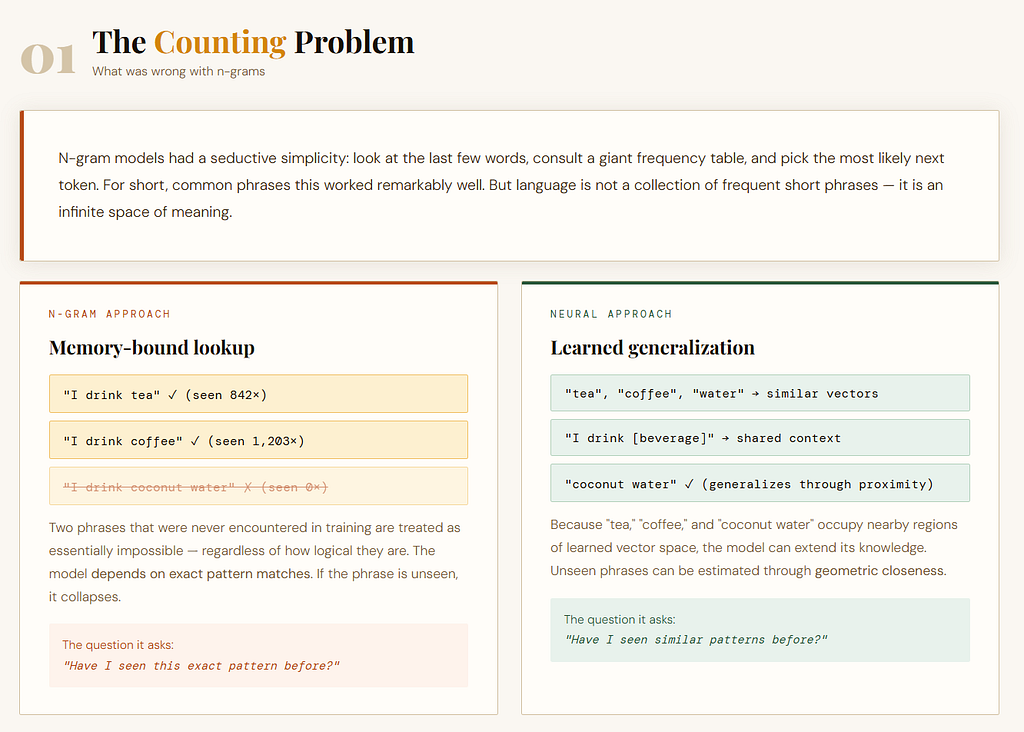
In an n-gram model, the logic is simple:
- look at the last few words
- count how often the next word followed them in the training data
- convert those counts into probabilities
So if the model has often seen:
- “I drink tea”
- “I drink coffee”
then after “I drink,” it may predict “tea” or “coffee.”
That works surprisingly well for short patterns.
But suppose the model sees:
- “I drink espresso every morning”
and it never saw that exact phrase before.
A count-based model struggles because it depends heavily on exact matches or near-exact local patterns. It does not naturally understand that “tea,” “coffee,” and “water” are all related kinds of things.
To it, words are mostly separate symbols. That was the deep limitation.
The big shift: words stopped being IDs and became vectors
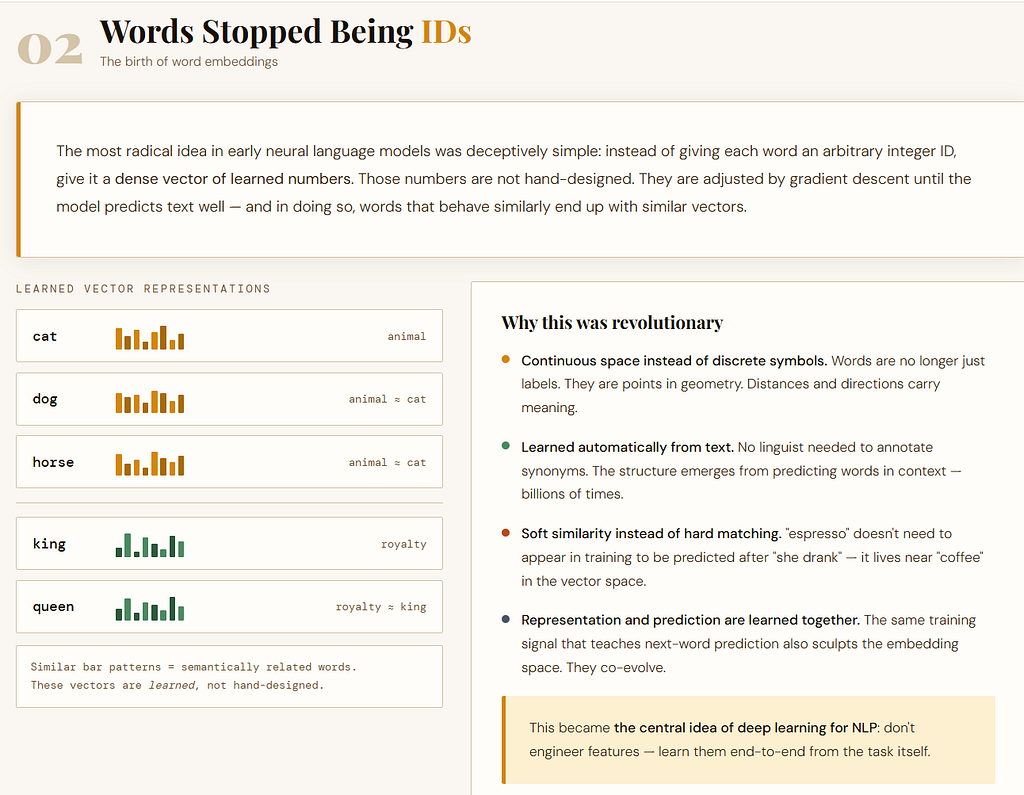
Early neural language models introduced a radically different idea.
Instead of treating each word as just a discrete token or dictionary entry, they mapped each word to a dense vector.
So “cat,” “dog,” and “horse” would no longer be merely three unrelated labels.
Each would be assigned a learned numerical representation, like:
- cat → a vector
- dog → a vector
- horse → a vector
These vectors were not manually designed. They were learned during training.
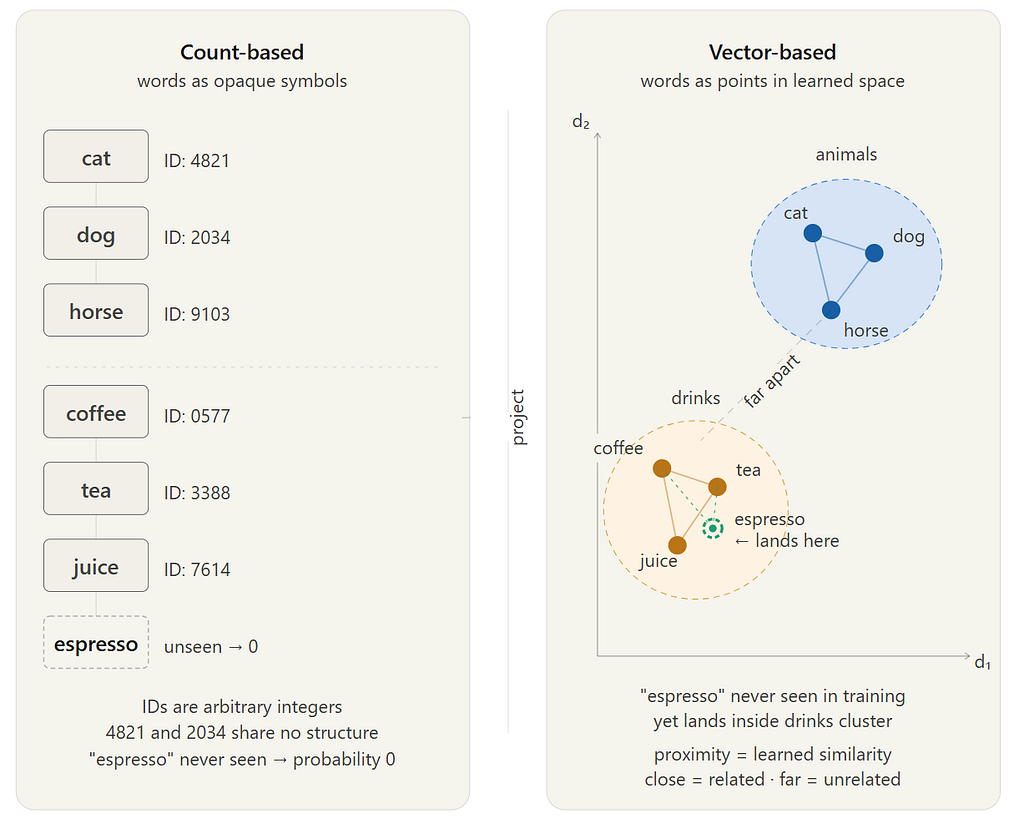
That matters because once words live in a vector space, the model can begin to capture a soft notion of similarity. Even if it has not seen one exact phrase many times, it may still generalize because similar words get similar internal representations. That was the breakthrough.
Counting asks:
“Have I seen this exact pattern before?”
A neural model begins asking:
“Have I seen similar kinds of patterns before?”
That is a much more powerful idea.
How early neural language models actually worked
Before Recurrent Neural Networks (RNNs), many neural language models still used a fixed context window.
Step 1: Choose a Fixed context window
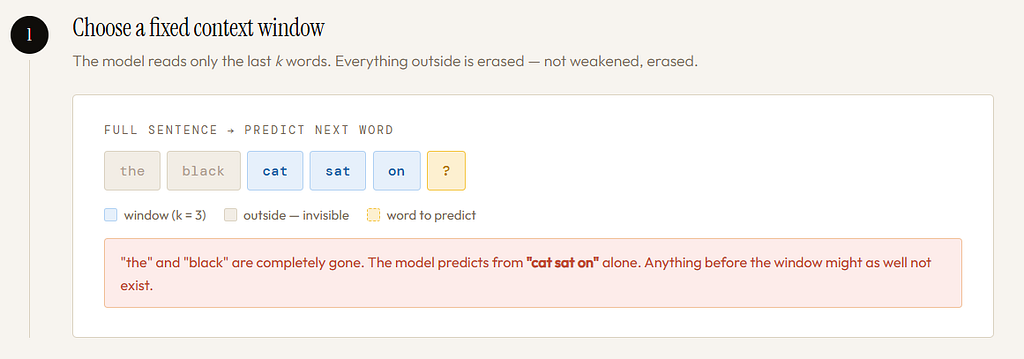
That means the model only looked at a fixed number of previous words. For example, suppose we want to predict the next word after:
“the black cat sat on the”
A fixed-window model might look only at the last 3 words:
“sat on the”
or the last 4 words:
“cat sat on the”
Not the entire sentence. Only a chosen window.
Step 2: convert words into vectors
Each word in the window is mapped to an embedding vector.
So if the context is:
“cat sat on”
then the model retrieves:
- vector(cat)
- vector(sat)
- vector(on)

Step 3: concatenate those vectors
Instead of averaging them, the model often concatenated them. That means it laid them side by side into one longer input vector. If each word vector had dimension 5, and the context window contained 3 words, the combined input would have dimension:
3 × 5 = 15
So the model preserves which word was in which position.
This is important.
“dog bites man” and “man bites dog” should not look the same.
Concatenation helps preserve order.

Step 4: feed that into a neural network
That long concatenated vector is then passed into a feedforward neural network.

The network applies learned weights and nonlinear transformations, and finally outputs a probability distribution over the vocabulary:
- P(next word = mat)
- P(next word = floor)
- P(next word = sofa)
- …
The model is trained so that the correct next word gets higher probability. Over time, both the word embeddings and the network weights are adjusted. So prediction is no longer a matter of raw counts.
It becomes a matter of learned parameters.

Why this was such a breakthrough
This was much more than a minor improvement over n-grams. It changed the whole philosophy of language modeling.
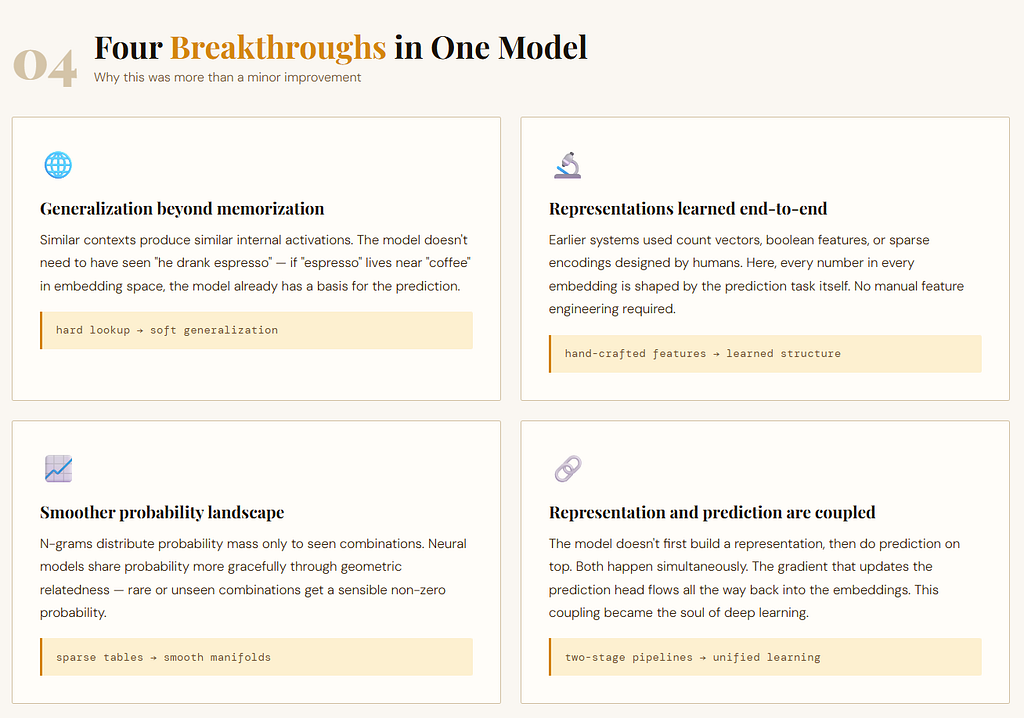
1. It allowed generalization beyond exact memorization
In count-based systems, two phrases are either seen or unseen.
In neural systems, similar contexts can produce similar internal states. So even if the model has rarely seen:
“he drank espresso”
it may still do better because “espresso” lives near other drink-related words in embedding space. This was one of the first ways language models began to move from hard lookup to soft generalization.
2. It learned the word representations automatically
Earlier systems often relied on hand-designed features, counts, or sparse encodings.
Here, the model learned embeddings as part of the prediction task itself. That idea would later become foundational.
Word embeddings were not just a side trick.
They became the beginning of learned meaning in neural NLP.
3. It made language smoother
In count-based models, unseen combinations collapse badly. In neural models, probability mass can be shared more gracefully across related words and contexts. That made prediction less brittle.
4. It introduced the idea that representation and prediction should be learned together
This is subtle but huge.
The model was not only learning what comes next.
It was also learning how words should be internally represented so that prediction becomes easier.
That coupling of representation-learning and task-learning became one of the central themes of deep learning.
A simple intuition
Think of n-grams as a clerk with a giant notebook.
You ask:
“After the phrase ‘in the morning’, what usually comes next?”
The clerk flips pages and says:
“I have seen ‘sun’, ‘light’, ‘air’, ‘newspaper’…”
Useful, but memory-bound.
Now think of an early neural language model as someone who has stopped depending only on exact stored phrases and has begun to form an internal geometry of language.
It starts sensing:
- some words are similar
- some contexts are related
- some continuations make sense even when the exact sentence is rare
That is a profound step forward. But it still had a major weakness.
The fixed window problem
Even though these models learned, they still looked only at a fixed number of previous words.
That means they could not truly follow a sequence through time.
They could only inspect a local slice. This was the central limitation.
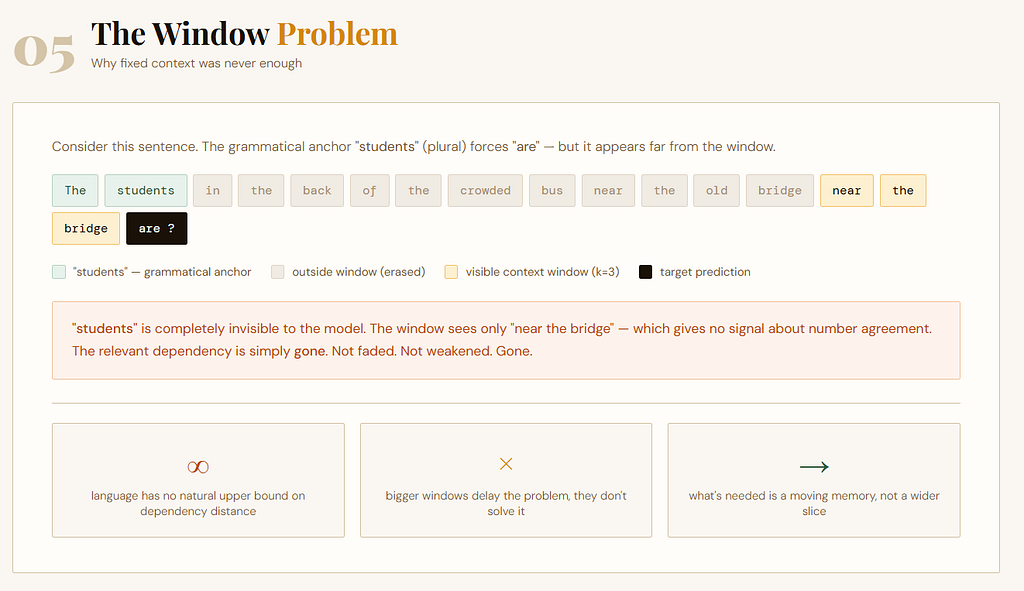
Suppose the model uses a 4-word window.
Then in a sentence like:
“The students in the back of the crowded bus near the old bridge are laughing”
the model may only see the last few words before predicting “laughing” or some later word. But the important grammatical anchor may lie much earlier:
“students” → “are”
The dependency may stretch across many tokens. A fixed-window model cannot truly carry that long-range signal forward. Anything outside the window is simply gone.
Not weakened.
Not faded.
Gone.
That is the key limitation.
Why fixed windows were not enough
1. Language is not bounded by a small local frame
Some relationships are nearby:
- “red apple”
- “very fast”
- “ate dinner”
But many are not.
Agreement, reference, topic flow, and meaning can depend on words far earlier in the sentence.
Human language unfolds over time.
A fixed window cuts that flow into small fragments.
2. Increasing the window does not really solve the problem
One might say: “Fine, then just use a bigger window.”
But that only delays the problem.
A window of 5 becomes 10.
10 becomes 20.
20 becomes 50.
Still, language has no natural fixed upper bound like that.
And bigger windows create their own issues:
- larger input size
- more parameters
- more computation
- harder learning
- still no true mechanism for remembering arbitrary past information
So enlarging the window is like making a short rope slightly longer.
It does not turn the rope into a real memory system.
3. The model still treated context as a static block
This is important.
A feedforward neural LM with concatenated context vectors does not process language as a living sequence.
It processes the last few words as a single input block.
That means it does not have a running state that evolves word by word across the whole sentence.
It sees chunks, not flow. And language is flow.
What changed when prediction became learned instead of counted?
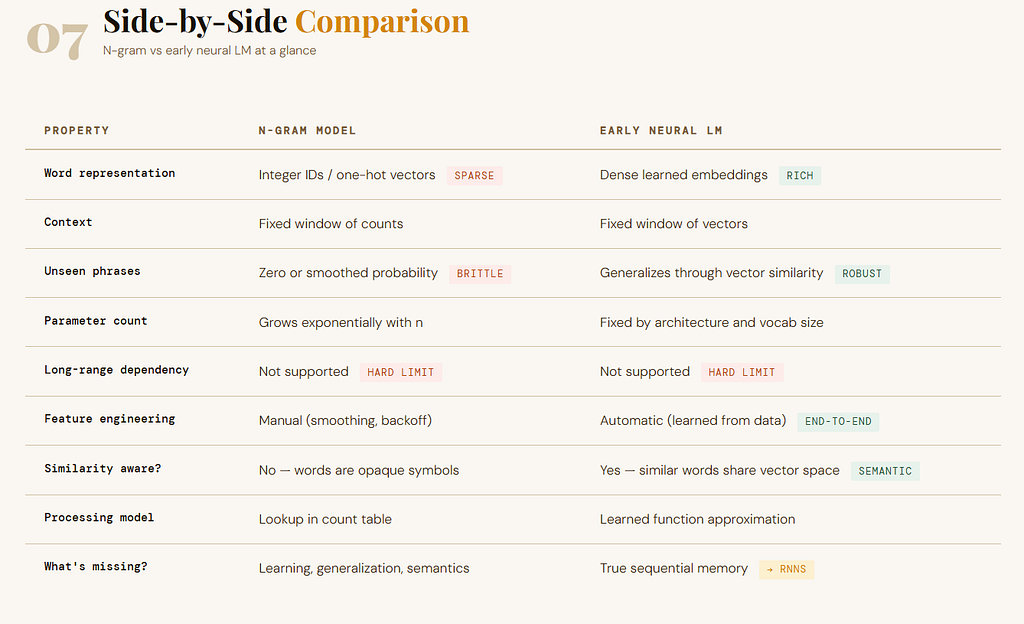
This is the heart of the article. When prediction was counted, the model relied on frequency tables. When prediction became learned, the model relied on parameters and representations.
That changed several things at once:
- words became vectors instead of mere labels
- similarity could be learned instead of manually imposed
- unseen phrases could sometimes be handled through generalization
- the model stopped being only a lookup table and became a trainable function
That was the breakthrough. But it was still not enough to fully model sequence. Why?
Because the model was learning within a fixed window, not learning how to carry evolving memory through time.
So learned prediction was more flexible than counted prediction, but still not truly sequential in the deeper sense. That is exactly the tension that leads to RNNs.

The question that had now appeared
Once researchers saw the power of learned word vectors and neural prediction, a new question became unavoidable.
Why must context be chopped into a fixed block at all?
Why not let the model read one word at a time?
Why not let each new word update some internal state?
Why not let the past remain present in a compressed form?
Why not let sequence be processed as sequence?
This is the conceptual doorway to recurrence.
Because once language is understood as something that unfolds, a feedforward fixed-window model starts to look strangely artificial. It is as if language were being repeatedly cut into little snapshots, even though it is really a moving stream.
The field had learned how to soften words into vectors.
Now it needed to learn how to let meaning move.
Closing thought
Early neural language models were a historic turning point because they taught NLP something revolutionary:
meaning does not have to be hand-counted; it can be learned through representation.
That changed everything. But they also revealed a second truth: learning local context is not the same as remembering a sequence.
That second truth is what made RNNs necessary. So this phase of history matters for two reasons:
- it showed that words could live in a learned vector space
- it showed that fixed windows, however clever, were still too small for the true flow of language
That is why these models are so important. They were not the final answer.
They were the first serious sign that language modeling had to become both: a representation problem and a memory problem
One-line memory hook
N-grams counted nearby words; early neural language models learned nearby meaning — but they still could not truly remember faraway context.
Neural Networks for Language: How Context Became a Learned Transformation was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.