Language can be studied from more than one direction.
One direction asks how words can be represented so that a machine can work with them at all. Another asks what happens when language unfolds through time, word by word, and a model has to stay oriented inside that flow. Those two threads developed alongside each other.
Because words do not arrive all at once.
Meaning is not delivered in a single block. A sentence reveals itself gradually. Each new word narrows some possibilities, opens others, and sometimes forces us to reinterpret what we thought we understood a moment ago.
So the challenge is not only representation.
It is prediction.
It is memory.
It is sequence.
And at the center of that shift lies one deceptively simple idea:
Given the words so far, predict the next word.
That is the basic language-modeling task.
It sounds almost too small to deserve the history that followed. But it turned out to be one of the most fertile ideas in modern AI, because hidden inside it is a profound change in perspective:
language stopped being only something to encode, and became something to continue.
A language model is a machine for anticipation
At its core, a language model tries to answer a question like this: If I have already seen part of a sentence, what word is likely to come next? If the model sees:
The sky is
it should think words like blue, clear, or dark are more plausible than bicycle, receipt, or volcano.
If it sees:
She poured tea into the
it should lean toward cup, mug, or glass, not ladder or engine. That does not sound dramatic at first. It sounds like autocomplete.
But autocomplete is only the visible surface. Underneath it lies something deeper. To predict well, a model must become sensitive to structure, pattern, plausibility, and context. It must learn that language is not a bag of words but an unfolding field of constraints.
A language model is therefore not merely a storage system for vocabulary. It is not simply labeling language. It is trying to remain poised at the edge of a partial sentence and estimate what kind of future fits this past.
That is a very different relationship to language.
The key mathematical idea: conditional probability
To understand why next-word prediction mattered so much, we need one central concept from probability. Not a whole textbook. Just one idea.
Unconditional probability
If I write:

I mean the probability of rain. This is a probability considered by itself, without any extra information.
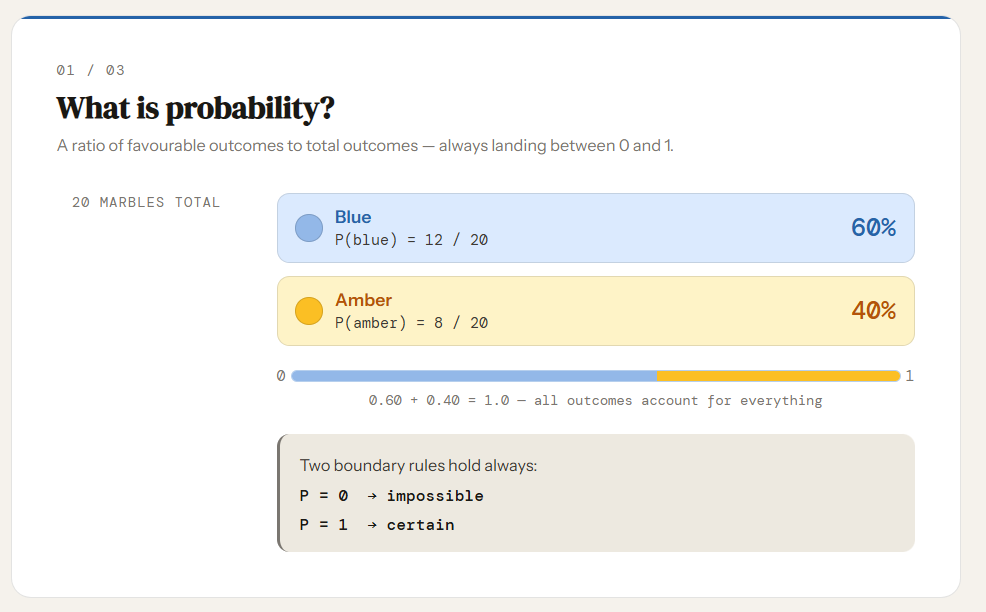
For example:
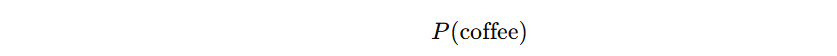
means: how likely is the word “coffee” in general, across all situations?
That is useful sometimes, but language rarely works that way. Words do not usually appear in isolation. They appear after other words.
Conditional probability
Now suppose I write:
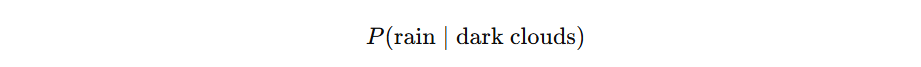
This means: the probability of rain, given dark clouds.
For example:
means: how likely is “umbrella” if I already know that it is raining?

That vertical bar means given. And this is the exact mathematical shape of language modeling. Because a language model does not mainly ask:
That may sound ordinary, but it is the exact mathematical shape of language modeling. Because the probability of a word is never really just “the probability of the word.” It is the probability of that word in context.
The word bank does not have one fixed likelihood everywhere.
After:
He deposited cash at the
the next word bank becomes plausible in the financial sense.
We could write that as:

which means:
given the words “He deposited cash at the,” how likely is the next word “bank”?
Now change the context:
The fisherman pulled the boat toward the
Here, bank becomes plausible in a very different sense — the edge of a river.
We could write:
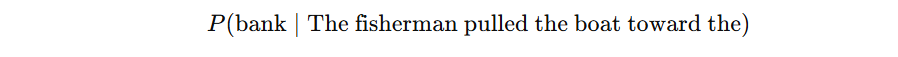
which means:
given the words “The fisherman pulled the boat toward the,” how likely is the next word “bank”?
Same word. Different context. Different probability landscape.
That is why a language model does not mainly ask:
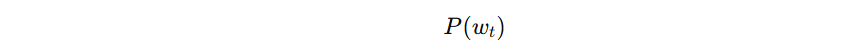
which means:
what is the probability of the next word in general, with no context?
Instead, it asks:
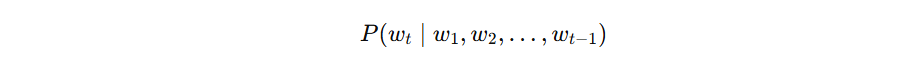
which means:
what is the probability of the next word, given all the previous words?
For example:
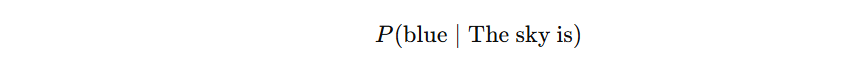
asks:
given “The sky is,” how likely is the next word “blue”?
And:

asks:
given “She poured tea into the,” how likely is the next word “cup”?
That is the core expression of next-word prediction.
It is hard to overstate how important this shift is. The model is no longer working with words in isolation. It is working with words under conditions. It is learning that every new word changes the probability landscape of what can reasonably follow.
Language modeling is, in this sense, the art of estimating conditional probability over an unfolding sequence.
A sentence is a narrowing field of possibilities
One beautiful way to feel this idea is to stop thinking of a sentence as a finished object and start thinking of it as a narrowing stream of possibilities.
At the beginning of a sentence, many futures are open.
The…
could become almost anything.
Then we get:
The child…
Already the field narrows.
Then:
The child opened…
Narrower still.
Then:
The child opened the gift…
Now certain continuations begin to feel far more plausible than others.
Then:
The child opened the gift and smiled because…
At this point, the sentence is already bending toward explanation. It wants a reason, a cause, a continuation that belongs to the emotional logic now being established. Every new word does not merely add one more item to a list. It reshapes expectation.
That is why conditional probability is so natural here. Language really does unfold as a succession of changing conditions. What is likely next depends on what has already happened. A language model lives inside that shifting horizon.
Why this “simple” task is not simple at all
If next-word prediction were only about memorizing common phrases, it would be useful, but limited. The real surprise is that to do this task well, a model must learn much more than just frequent word pairings.
Take this fragment:
The dogs in the garden
A plausible continuation is:
are barking
not:
is barking
Why? Because the model must somehow remain sensitive to the plural subject dogs, even though garden is the nearest noun near the end of the phrase.
Or take:
He opened the window because the room was too
Now words like hot, warm, or stuffy become likely.
That is not only grammar. That is also situational expectation. The model is being pulled toward ordinary patterns of human language and life.
Or take:
She spread the bread with
Likely next words include butter, jam, or honey. Far less likely are cement, thunder, or piano. So even though the formal task says only:
predict one word
what it truly requires is sensitivity to:
- syntax
- agreement
- word order
- semantic fit
- common structures
- contextual expectation
- short-range and sometimes longer-range dependencies
A very small question starts exerting a very large pressure. And that pressure is what made the task so powerful.
Why next-word prediction quietly teaches syntax
People sometimes imagine syntax as something that must be explicitly handed to the model first, like a grammar book placed on a desk before learning begins.
But next-word prediction creates another route. If the model repeatedly performs poorly on contrasts like:
The boy runs
The boys run
then the training process pressures it toward patterns that respect number agreement.
If it repeatedly sees that:
If she had known…
tends to continue differently from:
She knows…
then it is pushed toward sensitivity to tense and grammatical structure.
Nobody has to begin by manually encoding every rule. The objective itself creates the pressure. This is one of the most elegant ideas in modern machine learning:
instead of directly programming every piece of linguistic knowledge, we define a task whose success requires becoming responsive to that knowledge.
The model is not taught grammar in the way a schoolchild is taught grammar. It is shaped by a prediction problem that makes grammar-sensitive behavior useful. That is subtler, and in some ways more radical.
Why it teaches patterns of meaning too
Syntax is not enough. A sentence can be grammatically acceptable and still feel absurd. Consider:
She spread the bread with
Likely continuations:
- butter
- jam
- honey
Very unlikely continuations:
- gravel
- electricity
- moonlight
To predict well, the model must learn more than legal structure. It must also learn which kinds of words tend to belong together in real human usage.
Doctors treat patients.
Rain falls.
Tea goes into cups.
Birds fly.
People miss trains.
Apologies follow mistakes.
This does not mean the model understands the world exactly as a human being does. It has no childhood, no hunger, no body, no embarrassment, no wet shoes after rain.
But language carries the statistical shadow of human life. And a model trained to predict continuations is forced to absorb many of those regularities, because otherwise its predictions remain clumsy and implausible.
So next-word prediction becomes a pressure not only toward syntax, but toward structured patterns of meaning. Not full lived meaning. But something important: the regularities that meaning leaves behind in language.
The model predicts a distribution, not a prophecy
A language model does not usually produce one next word with mystical certainty. It produces a distribution over possible next words.
For a context like:
The capital of France is
the model might assign a very high probability to Paris, a lower one to Lyon, and tiny probabilities to words that do not fit at all.
We could write something like:

which means:
given “The capital of France is,” “Paris” should be much more likely than “Lyon.”
Another example:
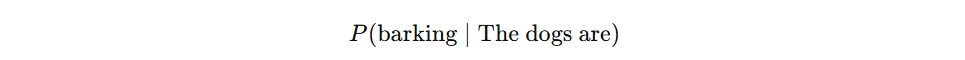
might be higher than
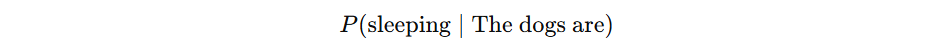
in one context, but the reverse might happen in another dataset or sentence pattern. The important point is not the exact winner. The important point is that the model ranks possibilities under context. So the model is not choosing from nowhere. It is estimating a structured field of uncertainty.
This matters because intelligence in language is rarely about certainty alone. It is about ranking possibilities well under conditions. And that is exactly what conditional probability gives us: a formal way to say not only what is possible, but what is more plausible than what.
Why this objective changed the field
There is another reason next-word prediction was so transformative.
A sentence contains its own training signal.
If you take a sequence of words, the next word is already there in the data. You do not need a human annotator to separately label what should happen next. The text itself provides the target.
Suppose the training text says:
The moon shines at night
Then the model can learn from the fact that after:
The moon shines at
the next word was night. We could write:

which means:
given “The moon shines at,” how likely is “night”?
The answer is learned from real text itself.
That means language can, in a very important sense, be learned from language. This was a quiet revolution. Instead of requiring expensive hand-labeled data for every separate linguistic phenomenon, the field now had an objective that could turn raw text into supervision.
That made scale possible. And once scale became possible, the consequences were enormous.
But a hard question appears immediately
As soon as we write the language-modeling objective in its ideal form,
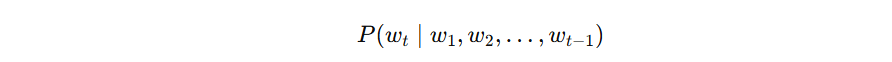
we run into another problem.
That expression means:
to predict the next word, use the full sentence so far.
For example:

means:
given everything in the sentence so far, how likely is the next word “inside”?
In theory, the next word depends on the entire previous history.
In practice, how much of that history can a model actually use?
A simpler model may look only one word back:

given the phrase “cup of,” how likely is the next word “tea”?


The more context a model uses, the more informed its prediction can become. But the harder the modeling problem becomes too.
How much of the past matters?
How far back should the model look?
How does it store what matters without drowning in what does not?
The moment language becomes prediction, it also becomes a problem of memory. That is where the next chapter begins.
Next-Word Prediction: How Conditional Probability Turned Language into a Learning Task was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.