The core architectures behind production-grade retrieval systems: chunking strategy, hybrid search, query transformation, self-corrective retrieval, and agentic orchestration

Large Language Models are remarkably capable text generators. Given enough parameters and training data, an LLM can draft legal briefs, debug Python scripts, explain quantum mechanics to a ten-year-old, and compose marketing copy — all from a single interface. However, LLMs are fundamentally amnesic. Their knowledge is frozen at training time, they cannot access proprietary databases, and they hallucinate with startling confidence when they don’t know the answer.
This is where Retrieval-Augmented Generation — RAG — comes in.
RAG systems connect LLMs to external knowledge sources at inference time, grounding every generated response in real, retrievable evidence. RAG is an architectural pattern: retrieve relevant documents — or passages — from a trusted store, then generate an answer grounded in those documents. Think of it as “open book” answering: the model reads before it writes.
But not all RAG is created equal. A naive implementation — embed documents, retrieve top-K chunks, stuff them into a prompt — breaks down the moment queries get complex, data gets messy, or accuracy becomes non-negotiable. This article examines five essential retrieval patterns that transform a basic RAG pipeline into a production-grade knowledge engine capable of precision, multi-hop reasoning, self-correction, and autonomous decision-making.
What Is a RAG System, Really?
A RAG system is a software architecture that augments an LLM’s generation capability with external retrieval. RAG is a hybrid framework that integrates a retrieval mechanism with a generative model to improve the contextual relevance and factual accuracy of generated content. The retrieval mechanism fetches relevant external data, while the generative model uses this retrieved information to produce coherent, contextually accurate text.
Unlike fine-tuning — which bakes knowledge into the model’s weights and requires expensive retraining — RAG leaves the model intact and updates data instead. This is the critical architectural distinction. Your knowledge stays in stores that are good at search. Your LLM stays good at language. Each component does what it does best.
The basic pipeline works in four stages: Ingest & index: split documents into chunks; create embeddings; store in a vector or hybrid search index. Retrieve: fetch top-K candidates using semantic or hybrid search. Re-rank: apply a cross-encoder or reranker to sort by true relevance. Generate: craft a prompt with citations/context and produce an answer, ideally with source links.
Simple enough on paper. In production, each of those four stages is a minefield. The five patterns below are how experienced teams navigate it.
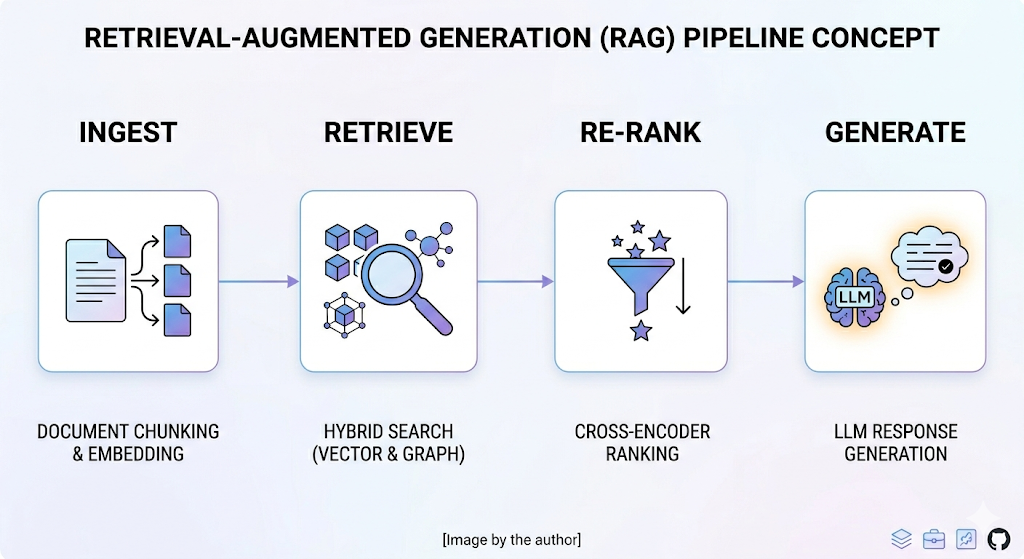
Pattern 1: Smart Chunking
The foundation of every RAG system is how you break documents into retrievable units. Get this wrong, and nothing downstream can save you. RAG quality is frequently an indexing problem disguised as an LLM problem.
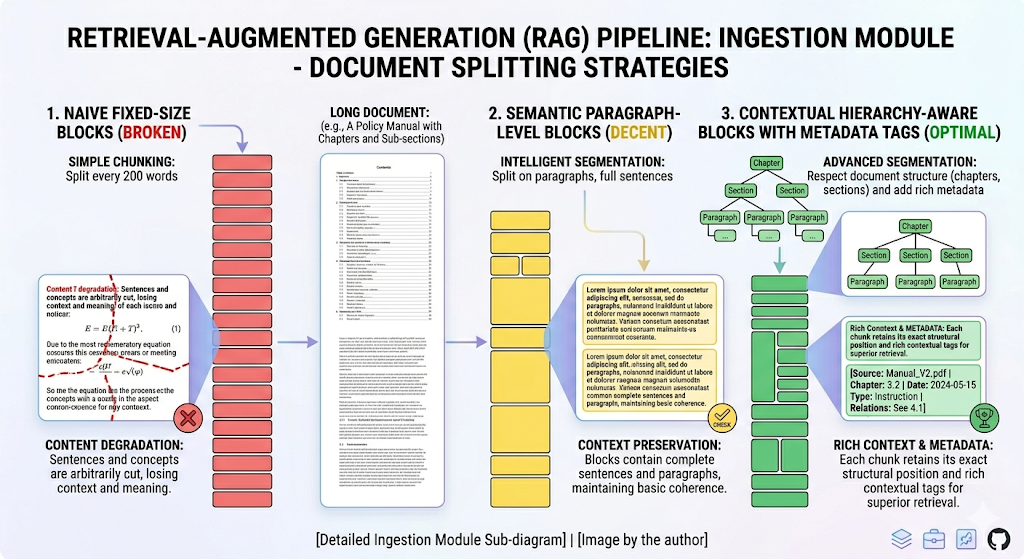
The naive approach is fixed-size chunking: split every document into 512-token blocks, embed them, and hope for the best. This works for simple FAQ-style retrieval, but it shreds context. A legal clause split across two chunks loses its meaning in both. A technical specification separated from its diagram caption becomes noise.
Smart chunking means choosing a granularity strategy that matches your data and your queries. Traditional RAG models divide documents into small chunks, typically averaging around 100 words. This approach enables fine-grained searching but significantly increases the search space, requiring retrievers to sift through millions of units to find relevant information. The alternative — Long RAG is an enhanced version of the traditional RAG architecture designed to handle lengthy documents more effectively. Unlike conventional RAG models, which split documents into small chunks for retrieval, Long RAG processes longer retrieval units, such as sections or entire documents. This innovation improves retrieval efficiency, preserves context, and reduces computational costs.
A more sophisticated approach is contextual chunking. You might do some contextual chunking — when you use another LLM to understand how to break this content better, you can augment this context so that each small piece still contains the whole hierarchy and never loses context for improving search later on.
In practice, the smart chunking pattern requires you to answer three questions before you write a single line of ingestion code: What is the natural unit of meaning in your corpus? What is the average complexity of your users’ queries? And what is your latency budget for retrieval?
# Example: Contextual chunking with metadata enrichment
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=200,
separators=["\n## ", "\n### ", "\n\n", "\n", " "]
)
chunks = splitter.split_documents(documents)
# Enrich each chunk with hierarchical context
for chunk in chunks:
chunk.metadata["section_title"] = extract_parent_heading(chunk)
chunk.metadata["doc_summary"] = doc_level_summary
chunk.metadata["source"] = document.metadata["source"]
The key insight: chunking is not a preprocessing step you set and forget. It is a design decision that constrains every subsequent pattern in your pipeline.
Pattern 2: Hybrid Search
Pure vector search was the original selling point of RAG. Embed your query, embed your documents, compute cosine similarity, return the nearest neighbors. Elegant in theory. Fragile in practice.
The problem is that semantic similarity and factual relevance are not the same thing. A query about “GDPR Article 17 right to erasure” will return semantically similar chunks about data privacy in general — but might miss the exact chunk that quotes Article 17 verbatim, because the embedding model maps many privacy concepts to the same region of vector space.
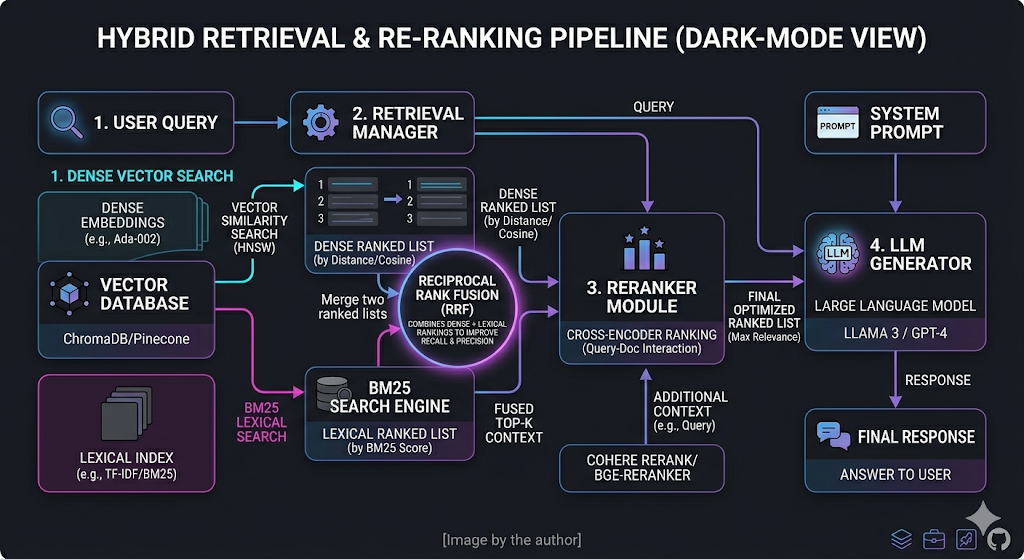
In practice, combine lexical and vector search — to catch both exact terms and meaning — and apply a reranker to reduce off-topic context — especially valuable for policy and legal corpora.
Hybrid search fuses two retrieval paradigms. Lexical search (BM25, TF-IDF) excels at exact term matching — names, product codes, legal citations, technical acronyms. Semantic search (dense vector retrieval) excels at intent matching — paraphrased questions, conceptual queries, natural-language requests. Neither alone is sufficient. Together, they cover each other’s blind spots.
This search can be done via semantic search, which is what got RAG popular. But the key part of searching is still the lexical search or the traditional search that we used to know.
The fusion step matters as much as the individual searches. Reciprocal Rank Fusion (RRF) is the most widely adopted method: it merges ranked lists from multiple retrieval sources by summing inverse ranks, giving a balanced score that doesn’t require tuned weights. RAG-Fusion further improves recall by combining results from multiple reformulated queries through reciprocal rank fusion.
After fusion, a cross-encoder reranker — a model that sees the query and each candidate passage together — rescores the merged list for true relevance. This two-stage architecture (retrieve broadly, then rerank precisely) is now the default in production RAG deployments.
# Hybrid search with RRF fusion
from rank_bm25 import BM25Okapi
import numpy as np
# BM25 lexical retrieval
bm25 = BM25Okapi(tokenized_corpus)
lexical_scores = bm25.get_scores(tokenized_query)
lexical_top_k = np.argsort(lexical_scores)[-20:][::-1]
# Dense vector retrieval
vector_results = vector_store.similarity_search(query, k=20)
# Reciprocal Rank Fusion
def reciprocal_rank_fusion(ranked_lists, k=60):
fused_scores = {}
for ranked_list in ranked_lists:
for rank, doc_id in enumerate(ranked_list):
fused_scores[doc_id] = fused_scores.get(doc_id, 0) + 1 / (k + rank + 1)
return sorted(fused_scores, key=fused_scores.get, reverse=True)
final_ranking = reciprocal_rank_fusion([lexical_top_k, vector_doc_ids])
Pattern 3: Query Transformation
Users are terrible at writing queries. This is not their fault. Natural language is ambiguous, underspecified, and riddled with implicit assumptions. The gap between what a user types and what they actually need is often the single biggest source of retrieval failure.
Query transformation is the pattern of rewriting, decomposing, or expanding the user’s original query before it hits the retrieval layer.
The simplest technique is query rewriting: use the LLM itself to rephrase the user’s question into a more retrieval-friendly form. A vague query like “Why is my deployment broken?” becomes “Common causes of Kubernetes deployment failure including CrashLoopBackOff, ImagePullBackOff, and insufficient resource limits.”
More powerful is multi-query generation: instead of one rewritten query, generate three to five variations that approach the same information need from different angles, retrieve against all of them, and fuse the results. This dramatically improves recall for complex or ambiguous questions.
For multi-hop questions — questions that require information from multiple documents to answer — the pattern extends into query decomposition. RQ-RAG decomposes multi-hop queries into latent sub-questions, and GMR uses a generative LLM to autoregressively formulate complex multi-hop queries.
Then there is Hypothetical Document Embeddings (HyDE), a technique that flips the retrieval paradigm entirely. When queries are sparse, generate a “hypothetical” answer, embed it, then retrieve real documents similar to that hypothesis — often improving recall for niche or underspecified queries. Instead of embedding the question and looking for similar passages, you generate what a good answer would look like, embed that hypothetical answer, and use it as the retrieval query. The intuition: a hypothetical answer lives closer to real answers in embedding space than the original question does.
# HyDE: Hypothetical Document Embeddings
def hyde_retrieve(query, llm, retriever):
# Step 1: Generate a hypothetical answer
hypothetical = llm.invoke(
f"Write a short, detailed paragraph that would answer "
f"this question: {query}"
)
# Step 2: Embed the hypothetical answer (not the query)
results = retriever.similarity_search(hypothetical.content, k=10)
# Step 3: Return real documents similar to the hypothesis
return results

Pattern 4: Self-Corrective Retrieval
The first three patterns improve what you retrieve. This pattern asks a more fundamental question: should you have retrieved at all — and is what you retrieved actually good enough?
Standard RAG retrieves once and generates. Self-corrective RAG introduces a feedback loop: after retrieval, the system evaluates whether the retrieved documents are relevant, sufficient, and non-contradictory before passing them to the generator. If they fail the check, the system re-retrieves, reformulates, or falls back to the LLM’s parametric knowledge.
Self-RAG trains models to decide when to retrieve, and to critique their own outputs — boosting factuality and citation accuracy across QA and long-form tasks.
The architectural insight behind Self-RAG is that retrieval is not always helpful. If the model already knows the answer with high confidence, retrieving irrelevant passages can actually degrade performance by introducing noise. The model should retrieve selectively — and then grade what it retrieved.
You’ll sometimes see this category described as active retrieval, including approaches like CRAG / self-correcting retrieval patterns. The takeaway: the best RAG systems aren’t one-shot. They behave more like a careful researcher.
This maps directly to the Reflection pattern from agentic AI. The system generates a retrieval plan, executes it, evaluates the results, and iterates. In practice, this is implemented as a state machine with explicit grading nodes:
# Self-corrective RAG with relevance grading
def grade_documents(query, documents, llm):
"""Grade each retrieved document for relevance."""
graded = []
for doc in documents:
response = llm.invoke(
f"Is this document relevant to the query '{query}'? "
f"Document: {doc.page_content[:500]}\n"
f"Answer YES or NO with a one-sentence explanation."
)
if "YES" in response.content.upper():
graded.append(doc)
return graded
def self_corrective_rag(query, retriever, llm, max_retries=3):
for attempt in range(max_retries):
documents = retriever.invoke(query)
relevant_docs = grade_documents(query, documents, llm)
if len(relevant_docs) >= 2: # Sufficient context threshold
return generate_answer(query, relevant_docs, llm)
# Transform query and retry
query = rewrite_query(query, llm)
# Fallback: generate from parametric knowledge with caveat
return llm.invoke(f"Answer based on your training data: {query}")
The trade-off is latency. Every grading step and retry adds an LLM call. Production systems tune the aggressiveness of the grading — strict grading with retries for high-stakes domains like healthcare or legal; lenient grading with fast fallbacks for conversational assistants.

Pattern 5: Agentic Orchestration
The four patterns above are powerful individually, but the most sophisticated RAG systems don’t pick one — they dynamically select and combine patterns based on the query, the data, and the task.
This is agentic RAG: retrieval under the control of an autonomous agent that plans, reasons, acts, and adapts.
Instead of a fixed, single hop, autonomous agents plan multiple retrieval steps, choose tools, reflect on intermediate answers, and adapt strategies for complex tasks, e.g., compliance checks across many systems.
In a standard RAG pipeline, the retrieval workflow is hardcoded: query → embed → retrieve → rerank → generate. In an agentic RAG system, the LLM itself decides the workflow. Given a complex query like “Compare our Q3 revenue against the three closest competitors and flag any regulatory risks in the EMEA region,” an agentic system might:
- Decompose the query into sub-tasks (revenue data, competitor identification, regulatory lookup)
- Route each sub-task to the appropriate data source (SQL database for revenue, web search for competitors, document store for regulations)
- Retrieve, grade, and synthesize results from each source
- Detect gaps in the retrieved information and issue follow-up retrievals
- Compose a final answer with citations from each source
Agentic RAG transcends these limitations by embedding autonomous AI agents into the RAG pipeline. These agents leverage agentic design patterns — reflection, planning, tool use, and multi-agent collaboration — to dynamically manage retrieval strategies, iteratively refine contextual understanding, and adapt. It doesn’t matter how the term evolved over time — GraphRAG, AgenticRAG, HybridRAG — everyone is still retrieving, augmenting, and generating. So no matter what you’re doing, if you’re building an agent and you want your agent to reply based on something, you are following this structure.
The routing decision is particularly critical when your knowledge spans heterogeneous sources.A mature RAG system doesn’t have to be “vector-only.” Depending on the question, retrieval can come from: vector stores for semantic search over unstructured text, relational DBs for exact structured facts, and graph DBs for relationships and traversals. This is why modern RAG stacks include things like Text-to-SQL, Text-to-Cypher, and self-query retrievers.

Combining Patterns: The Full Pipeline
No production RAG system uses a single pattern in isolation. The real power emerges when you layer them.
A mature retrieval pipeline might work like this: An incoming query hits the query transformation layer, which generates multiple reformulated queries. Each reformulated query is routed by the agentic orchestrator to the appropriate search backend — some to hybrid search (lexical + vector), others to a SQL interface, others to a knowledge graph. Retrieved results are fused, reranked, and then passed through the self-corrective grading loop. If the graded context is insufficient, the orchestrator triggers a new retrieval cycle with a transformed query. Only when the context passes the quality threshold does the generator produce the final response — grounded in passages that were smartly chunked to preserve the context that matters.
When workflows require more than just answering static queries — such as reasoning through multistep tasks, complying strictly with regulatory requirements, integrating real-time operational data, or retrieving data with deterministic accuracy — RAG alone often falls short. In 2026, advanced RAG systems address these and other limitations with a variety of innovations and architectural considerations. These enhancements push RAG from useful to indispensable.McKinsey’s latest survey shows 71% of organisations report regular use of GenAI in at least one business function, up from 65% in early 2024. As that adoption deepens, the retrieval layer — not the model — is what separates systems that occasionally hallucinate from systems that earn enterprise trust.
The five patterns in this article are not theoretical. They are the building blocks already deployed in production at companies running customer-facing knowledge assistants, internal compliance tools, and research copilots. The model gets the credit. The retrieval architecture does the work.
RAG Beyond the Basics: Five Retrieval Patterns That Turn Chatbots Into Knowledge Engines was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.