A CPO’s Battle Scars: Hard-Learned Lessons from Building Enterprise AI
Over the past three years, the evolution of AI in the data analysis space has been dizzying. From generalized Large Language Models (LLMs) to the explosion of chat-with-your-data-tools, every technical iteration has sounded like a quantum leap.
We watched breathtaking demos in the lab. Executives nodded approvingly during POC meetings. Everything looked flawless, until we actually threw these systems into enterprise production environments.
After deploying over 30 real-world enterprise projects and filling countless craters left by AI hallucinations, my team and I arrived at a painfully clear realization: Most AI data projects don’t die from a lack of technical capability; they die from a lack of trust.
In this life-or-death battle over tech stacks, we’ve stepped on every landmine across Text-to-SQL (2SQL), Text-to-Code (2Code), and the so-called “pure semantic layers.” Today, I want to cut through the conceptual hype, talk about the brick walls we hit in production, and explain why we ultimately committed to what looks like the clunkiest, most “boring” architecture out there.
The POC Trap and Production Reality: The Dead Ends of 2SQL and 2Code
In the feverish rush to replace analysts with AI, two seemingly paths emerged first:
2SQL: The Illusion of Flexibility (Natural Language→SQL→Database Execution)
This path is flawless during POC demos, granting AI maximum freedom to write complex queries. But in production, it is a catastrophe. Real-world business fields are riddled with ambiguity — faced with sales_amount versus sales_amt, the AI often just guesses. Complex table Joins trigger severe hallucinations, causing the model to fabricate relationships out of thin air. The fatal flaw? It’s a black box. When the AI calculates, “East Region gross profit last quarter was $5M,” business users can’t read the underlying SQL to know if that $5M includes refunds.
If they can’t verify it, they won’t trust it. I’ve witnessed a 2SQL system pull absurdly wrong numbers during a board of directors presentation. It was a bloodbath.
2Code: The Paradox of Power (Natural Language→Python Sandbox)
If SQL is too restrictive, why not let Python run in a sandbox? It’s Turing complete; the possibilities are endless. But the real-world slap in the face comes from “flow-state disruption.”
Real analysis is iterative: “Show me the Q2 trend” → Wait 15 seconds for the chart → “How about broken down by region?” → Wait 15 seconds → “Year-over-year comparison?” → Wait another 15 seconds. These constant delays shatter the analyst’s flow state, compounding frustration. Not to mention, when sandbox resources spiral out of control, a single infinite loop can melt down your servers. 2Code is powerful for building complex data pipelines, but it’s far too clunky for interactive business exploration.
The Middle Path: Text-to-DSL (2DSL)
After seeing clearly the hallucination chaos of 2SQL and the UX friction of 2Code, our team spent six months regrouping and retreated to a middle path: Natural Language (NL)→Domain-Specific Language (DSL)→Executable Query.
We admit, it is not fancy in a demo. It requires building controlled vocabularies and pre-defining logic. Yet, it is the only solution that actually survived with our real-world clients, successfully handling 95% of their actual business requests.
Why 2DSL?
You can think of a DSL as an immutable contract between the LLM and the human. The system doesn’t just spit out a black-box number. Instead, it translates its understanding into business language first:
- Metric: Sales (Tax inclusive, excluding refunds)
- Timeframe: Q1 2026
- Aggregation: Year-over-Year, by Region
The strategic value of this step is accountability. Business users might not read code, but they absolutely read business logic. We handed the gavel for “judging if the data is right” back to humans.
In creative writing, we encourage AI to hallucinate and diverge. But on the battlefield of enterprise data, certainty will always trump creativity. 2DSL isn’t a compromise born of technological inferiority; it is a traceable, explainable, and reproducible firewall built on top of an unpredictable LLM.
Self-Imposed Prisons: Shrinking the Product Boundary
Truthfully, in the early days of establishing the 2DSL route, we fell into another trap: We let our technical boundaries dictate our product boundaries.
Three years ago, terrified by AI hallucinations, lack of control, and high API costs, we used 2DSL to build a cage for the AI. We confined the product to single-turn, precise interactions: ask it perfectly, get an answer; ask it wrong, hit a dead end (”Parsing failed, please try again”).
We called it pragmatism. But when products like Manus (championing sandbox as infinity) and various AI Agents taking over computer interfaces (control as boundlessness) emerged, it stung us deeply.
Users never wanted dry data retrieval. When they say, “Help me figure out why East Region sales dropped,” they want analysis. When they say, “Draft a report for my boss,” they want delivery.
We had used 2DSL to protect ourselves, but in doing so, we forced our users to learn our narrow, rigid query paradigm.

Cognitive Paradigm Shift: Not Just a Tool, But the Protagonist
This sparked the most painful internal debate our team has had recently: Is the LLM a tool, or is it the protagonist?
If you treat the LLM as a tool (e.g., a simple SQL translator), you are doomed to endless anxiety. It can only operate within your narrow rules, and every time the base model updates, you terrified it will break your existing logic.
But what if we flip the perspective?
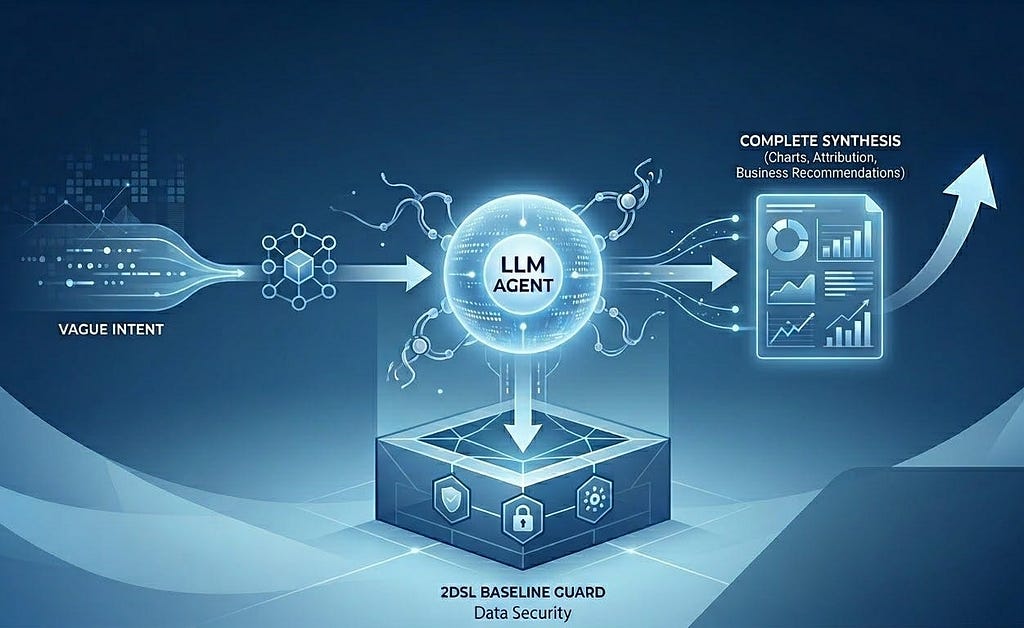
Once we used 2DSL to ruthlessly lock down data accuracy, permissioning, and performance, we had essentially built the ultimate, safest weapon for the LLM. At that point, we could completely let go and allow the LLM to become the protagonist of the system: a Data Agent.
It becomes the user’s primary entry point. It takes the user’s vague intent (”Why did sales drop?”), autonomously breaks down an analytical framework, orchestrates the stable, precise 2DSL components beneath the surface, and synthesizes a complete report filled with charts, attribution analysis, and business recommendations.
Without 2DSL as a safety net, an Agent’s expansion is a disastrous feast of hallucinations. But with 2DSL guarding the baseline, the evolution of LLMs directly drives exponential leaps in product value. The stronger the base model gets, the happier we are.
Final Thoughts
From 2SQL to 2DSL, and now to Agent orchestration, we’ve crawled through this minefield for three years.
The best technology is never the most flexible one, nor is it the one that looks smartest in a demo. The best technology is the system architecture that gracefully handles an enterprise’s imperfect current data reality while natively embracing the infinite future evolution of LLMs.
I highly recommend that we stop believing the fairy tale that “one line of natural language will replace all dashboards.” In the swamp of enterprise AI, there is only one rule for survival: Defend the baseline with the most boring tech, and welcome the endgame with the most open architecture.
A weekly article acting as a bridge between AI and real-world enterprise operations, with deep dives into decision intelligence.
By Saber CHEN, CPO @ FanRuan Software.
The AI Data Illusion: Why “Boring” Tech is the Only Real Enterprise Solution was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.