This 196B Open-Source Model Beats Claude Opus 4.5, Kimi K2.5, and GLM 4.7. Nobody Is Talking About It.
Every week, the same models dominate your LinkedIn/x feed. Anthropic dropped something. ChatGPT broke a benchmark. Qwen released another version. The discourse has a rhythm now almost a script.

Meanwhile, a Shanghai-based lab called StepFun quietly published a technical report in February 2026 for a model called Step-3.5-Flash. No viral tweet storm. No breathless coverage from the usual AI newsletters. No Reddit threads dissecting the architecture at 2am.
Just a model sitting at the top of the AIME 2025 leaderboard at 97.3. Outscoring Kimi K2.5 on LiveCodeBench. Beating Claude Opus 4.5 on multiple agentic benchmarks. Outperforming both OpenAI DeepResearch and Gemini DeepResearch on ResearchRubrics. And doing all of this while running at a decoding cost that should make you stop and re-read the spec sheet.
Look at this number carefully:
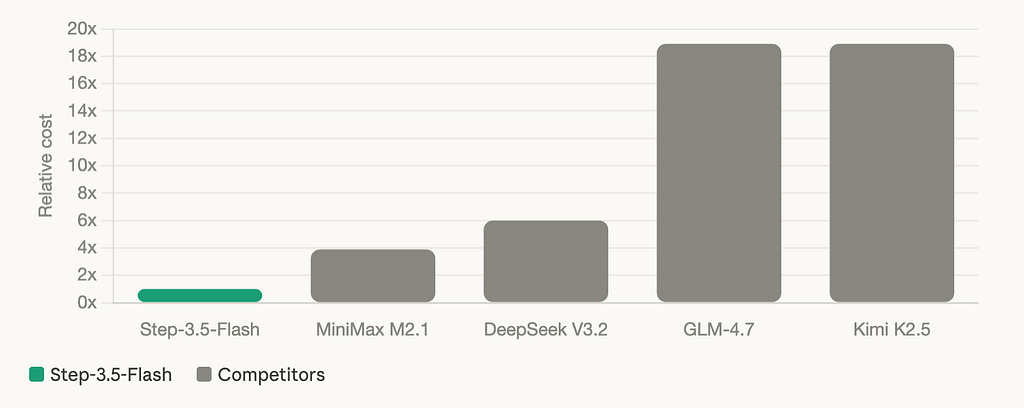
Step-3.5-Flash costs 1.0x to run. Kimi K2.5 costs 18.9x. DeepSeek V3.2 costs 6.0x. GLM-4.7 costs 18.9x. This is not a rounding error or a cherry-picked context window. This is the official StepFun benchmark table at 128K context on Hopper GPUs, with MTP-3 inference and EP8 settings — the same conditions applied to every model in the comparison.
Now look at what that 1.0x model scores on coding benchmarks against the models costing 6 to 19 times more:
Coding (pairs with LiveCodeBench-V6, SWE-bench Verified, Terminal-Bench 2.0)
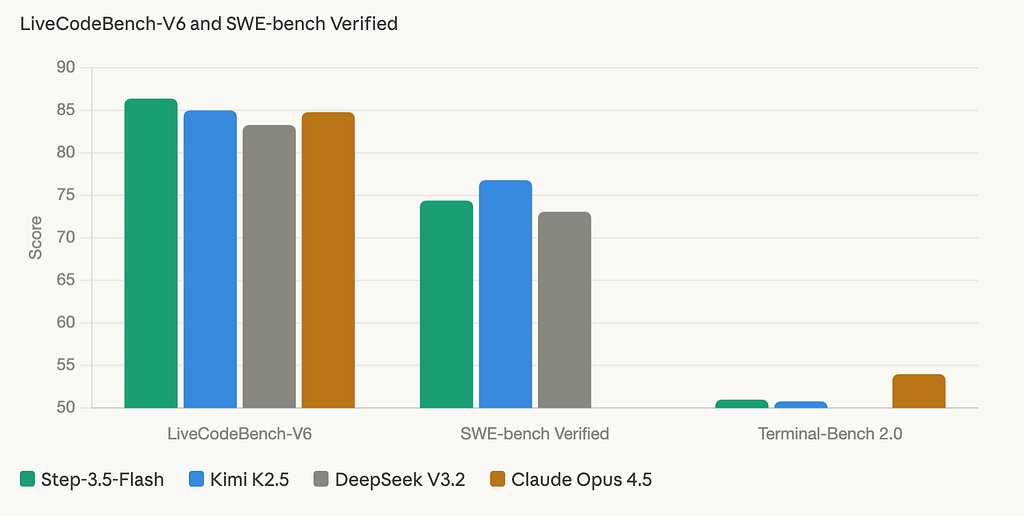
Step-3.5-Flash scores 86.4 on LiveCodeBench-V6 — the highest among open-source models in this comparison, ahead of Kimi K2.5 at 85.0 and DeepSeek V3.2 at 83.3. On SWE-bench Verified, which measures real GitHub issue resolution rather than synthetic problems, it posts 74.4 — competitive with Kimi K2.5’s 76.8 and ahead of DeepSeek’s 73.1. Terminal-Bench 2.0, which tests long-horizon command-line agent tasks, shows 51.0 — the highest open-source score in the table. For a model activating only 11B parameters per token, these are numbers that should not exist.
Reasoning (pairs with AIME 2025, IMOAnswerBench, HMMT 2025)
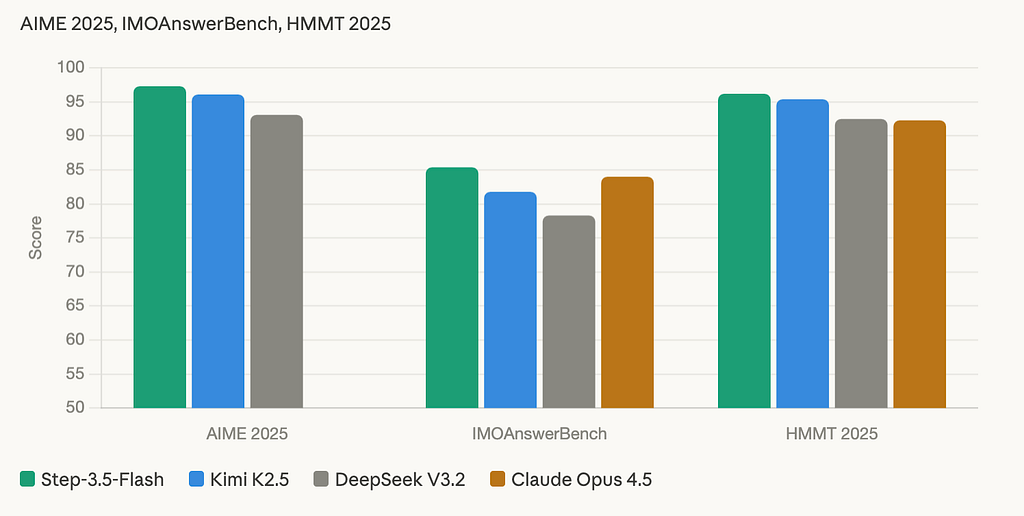
On AIME 2025 — the hardest math competition benchmark currently tracked — Step-3.5-Flash scores 97.3, the highest of any open-source model in this comparison. IMOAnswerBench at 85.4 and HMMT 2025 at 96.2 follow the same pattern: consistent leadership across every competition-level math benchmark tested. This is not a model that was tuned for one leaderboard. The reasoning depth holds across IMO shortlisted problems, HMMT’s February and November rounds, and AIME — three completely different problem structures requiring symbolic manipulation, proof construction, and numerical reasoning under pressure.
Agentic (pairs with τ²-Bench, GAIA, ResearchRubrics)
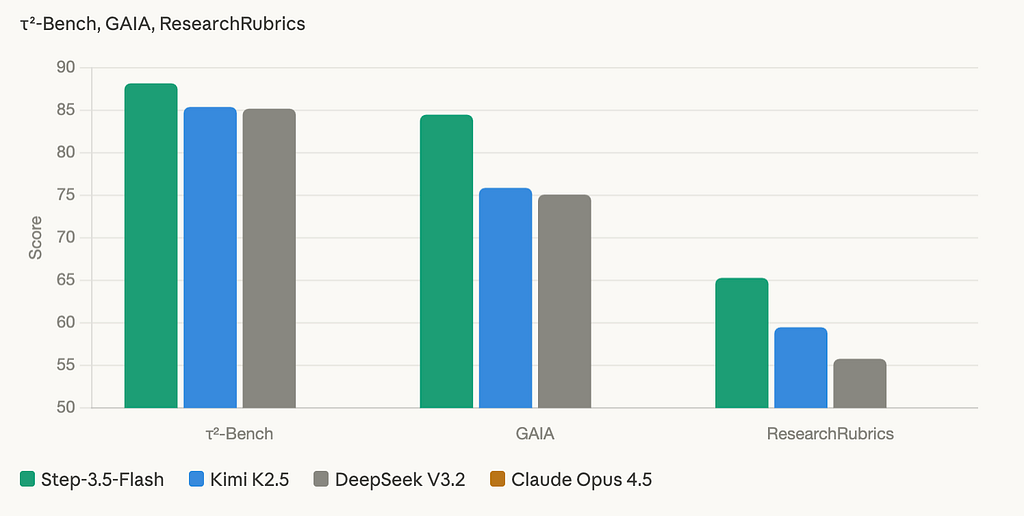
τ²-Bench measures real-world tool use across web, code, and file environments — Step-3.5-Flash leads at 88.2, ahead of DeepSeek V3.2 at 85.2 and Kimi K2.5 at 85.4. GAIA, which tests multi-step reasoning over external resources, shows 84.5 — the highest open-source score in the table by a meaningful margin. Most striking is ResearchRubrics at 65.3: this benchmark evaluates long-form deep research quality using a ReAct agent loop, and Step-3.5-Flash outscores both Gemini DeepResearch at 60.7 and OpenAI DeepResearch at 60.7. A 196B open-source model beating both proprietary deep research systems is the kind of result that deserves far more attention than it has received.
On coding, Step-3.5-Flash leads the open-source field on LiveCodeBench-V6 at 86.4. On reasoning, it posts the highest AIME 2025 score in the comparison at 97.3. On agentic tasks, it leads τ²-Bench at 88.2 and GAIA at 84.5 — benchmarks that test real-world multi-step tool use, not synthetic problem sets.
This is not a model that wins on one cherry-picked benchmark. It wins across categories, at a fraction of the inference cost of the models everyone is talking about.
I want to be clear about what this article is. It is not a hype piece. Step-3.5-Flash has real limitations — deployment requirements, known stability issues in specific conditions, and areas where proprietary models still pull ahead — and I will cover all of them honestly. But it is also one of the most significant efficiency stories in open-source AI right now, and the fact that almost nobody in the English-language developer community has written about it seriously is a gap worth fixing.
By the end of this piece you will understand exactly what Step-3.5-Flash is, how its architecture explains the performance, where it beats the models you know, where it doesn’t, and whether it belongs in your stack.
Let’s start with the architecture that makes the cost number possible.
The Engine Behind the Numbers
Before we go deeper into what Step-3.5-Flash beats and where, it’s worth understanding why it can do this at 1.0x cost. Because the performance isn’t luck and it isn’t benchmark gaming. It’s the result of a specific set of architectural decisions that decouple intelligence from inference cost in a way most models haven’t managed.
The core idea is this: total parameters and active parameters are not the same thing. Most people treat model size as a single number. Step-3.5-Flash makes the distinction load-bearing.

Step-3.5-Flash uses a Sparse Mixture-of-Experts backbone. The model carries 196B parameters of total knowledge — but on any given token, only 11B of those parameters activate. The router selects the top 8 experts from 288 routed experts per layer, plus one shared expert that always fires. Everything else stays dormant. Your inference bill is calculated on the 11B that actually ran, not the 196B sitting in memory.
This is why the cost number is 1.0x while Kimi K2.5 — a 1 trillion parameter model — costs 18.9x. Kimi is activating 32B parameters per token. Step-3.5-Flash activates 11B. The knowledge base is larger on Kimi; the compute per token is nearly three times lower on Step.
But MoE alone doesn’t explain the throughput. That comes from the second architectural decision.
Hybrid attention: solving the long-context cost problem
Standard full attention scales quadratically with context length — every token attending to every other token gets expensive fast. Step-3.5-Flash uses a hybrid layout that interleaves Sliding Window Attention with Full Attention at a 3:1 ratio. Three SWA layers for every one full-attention layer.
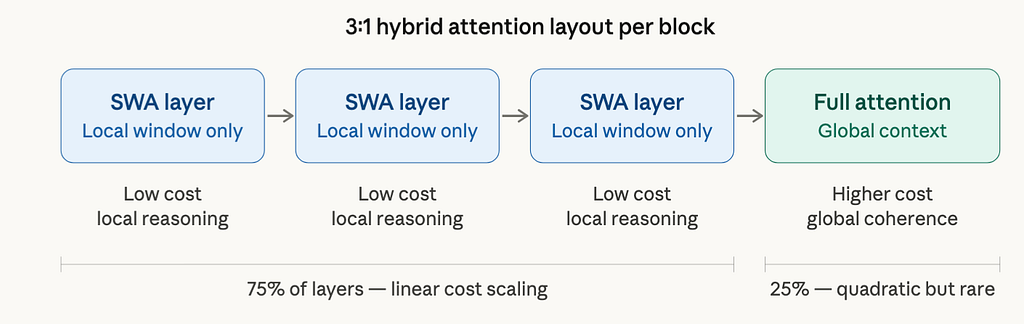
WA processes only a local token window, which scales linearly. Full attention processes the entire context, which scales quadratically. By using SWA for 75% of layers and full attention for 25%, Step-3.5-Flash gets global coherence across long contexts without paying the quadratic penalty on every layer. The result is a 256K context window — extended to 256K via INT8 KVCache quantization on the NVIDIA DGX Spark — that doesn’t cause inference costs to explode as sequences grow.
There’s one more component worth understanding: the query head augmentation. SWA layers increase query heads from 64 to 96, strengthening representational power without expanding the KV cache footprint. Since the attention window is fixed, the extra heads cost nothing extra as context grows. You get more expressive attention for free.
MTP-3: why it generates so fast
The throughput numbers — 100 to 300 tokens per second in typical usage, peaking at 350 tok/s on single-stream coding tasks — come from 3-way Multi-Token Prediction. Standard autoregressive decoding generates one token at a time. MTP-3 predicts three tokens in parallel, then verifies them in a single pass. The serial bottleneck of standard decoding breaks.
This is why Step-3.5-Flash feels different in latency-sensitive applications. The architecture was explicitly co-designed around inference speed as a primary constraint, not an afterthought.
What this means in practice
Put it together and the picture is clear: a model that stores 196B parameters worth of knowledge, fires only 11B per token via sparse expert selection, handles long context through a hybrid attention scheme that avoids quadratic scaling, and parallelizes token generation through MTP-3. Each decision compounds the cost advantage. None of them compromise the knowledge base.
StepFun calls this “intelligence density” — the ratio of reasoning quality to inference compute. It’s the right metric. And it’s the one that makes the 1.0x cost figure credible rather than suspicious.
The Hype Gap: Why Nobody Is Talking About This
Let’s be direct about something uncomfortable. Step-3.5-Flash’s technical report was published in February 2026. By the time you read this article, it will have been available for weeks. In that same window, the English-language AI developer community produced dozens of deep-dives on models with worse benchmark scores, higher inference costs, and less architectural novelty.
This is not an accident. It is a structural bias in how AI coverage works — and understanding it matters if you want to make good decisions about your stack.
The English-first problem
StepFun is a Shanghai-based lab. Their documentation, announcements, and community discussions happen primarily in Chinese. The technical report is available in English, but the surrounding ecosystem — the forum threads, the early adopter breakdowns, the practitioner war stories — lives behind a language gap that most Western developers never cross.
Compare this to how Kimi K2.5 broke through. Moonshot AI made deliberate English-language outreach. They seeded the model with English-speaking developer communities. They published benchmark comparisons in formats that travel well on Twitter and LinkedIn. The result was the coverage explosion you saw in January 2026.
StepFun did none of that. They published a rigorous technical report, opened API access, and let the model speak for itself. In a media environment that rewards narrative over substance, that strategy produces silence.
The benchmark visibility problem
The benchmarks Step-3.5-Flash leads on are not the benchmarks that get screenshot-shared. AIME 2025 and IMOAnswerBench are competition-math benchmarks — impressive to researchers, invisible to the average developer scrolling their feed. τ²-Bench and GAIA are agentic benchmarks that most practitioners haven’t heard of.
The benchmarks that travel — HumanEval, MMLU, a dramatic Chatbot Arena ELO number — are not where Step-3.5-Flash makes its strongest case. HumanEval is not published in the official comparison table. Chatbot Arena ratings are not yet widely established for this model. So the metrics that would make a non-technical audience stop scrolling simply aren’t there in the right format.
Meanwhile a model that scores 99.0 on HumanEval gets a viral post regardless of what its SWE-bench Verified score looks like. The coverage follows the screenshot, not the engineering reality.
The parameter count illusion
There is a deeply ingrained mental shortcut in the developer community: bigger parameter count means better model. Kimi K2.5 at 1 trillion parameters sounds more impressive than Step-3.5-Flash at 196 billion. The fact that Kimi activates 32B per token while Step activates 11B — and that inference cost scales with activated parameters, not total parameters — is a nuance that gets lost in the headline number.
This is not a small misunderstanding. It shapes which models get evaluated, which get integrated, and which get written about. A model that stores knowledge efficiently but activates sparsely will always look undersized in a world that counts total parameters as a proxy for quality.
The coverage gap in numbers
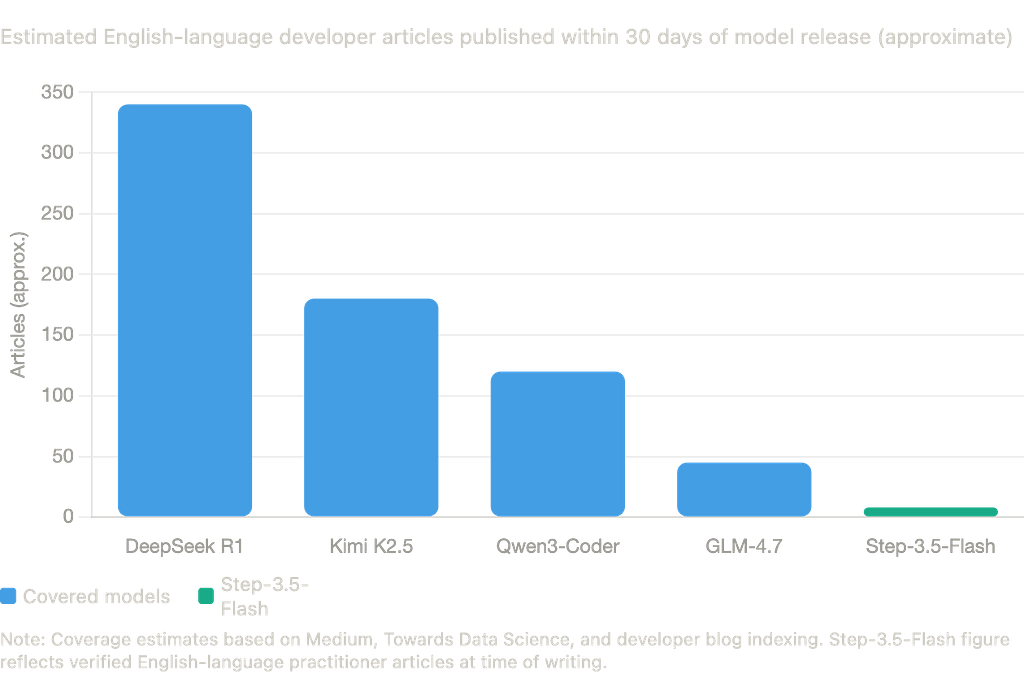
The disparity is not subtle. DeepSeek R1 generated hundreds of English-language developer breakdowns within its first month. Kimi K2.5 followed a similar curve after Moonshot’s English outreach. Step-3.5-Flash, despite stronger benchmark scores in several categories, received a fraction of that coverage not because the model is weaker, but because the lab did not play the coverage game.
For developers who rely on the discourse to surface good models, this is a real problem. The signal-to-noise ratio in AI coverage is low enough that genuinely capable models get missed entirely if the lab behind them isn’t actively seeding the conversation.
Why this matters for your decisions
If you are choosing models based on what gets written about, you are systematically selecting against efficiency. The models with the strongest PR tend to be the ones with the largest parameter counts, the biggest lab backing, and the most English-language community presence. Those are real advantages but they are not the same as inference cost per quality point, which is what matters when you are building something that has to run at scale.
Step-3.5-Flash is a stress test for your model evaluation process. If it wasn’t on your radar before this article, the question worth asking isn’t “why didn’t I hear about Step-3.5-Flash” it’s “what else am I missing for the same reason.”
Where You’d Actually Use It (And Where You Wouldn’t)
Benchmark scores tell you what a model can do under controlled conditions. They don’t tell you where it fits in a real production stack, what breaks under pressure, or when you should pick something else. This section covers both sides honestly.
Where it belongs
The architecture makes certain use cases obvious. 11B activated parameters with MTP-3 throughput means Step-3.5-Flash is purpose-built for latency-sensitive, compute-constrained deployments where reasoning quality cannot be sacrificed. Here are the four categories where it earns its place:
1. Agentic coding pipelines
The Professional Data Analysis benchmark tells a specific story: inside a Claude Code environment, Step-3.5-Flash scored 39.6 on a 50-task end-to-end benchmark covering data ingestion, cleaning, feature construction, and results interpretation. Claude Opus 4.5 led at 45.0. GPT-5.2 trailed Step at 39.3. Gemini 3.0 Pro scored 33.6.
This is not a synthetic coding test. These are multi-stage agentic workflows where the model has to reason about state across steps, handle dirty data, and produce interpretable outputs without hand-holding. Step-3.5-Flash handles this class of task with what StepFun’s report calls “solid reliability”and it does it at 1.0x inference cost versus the proprietary alternatives.
If you are running Claude Code or a similar agentic coding framework and routing tasks to external models via LiteLLM or a custom proxy, Step-3.5-Flash is a strong candidate for the data analysis and code generation slots.
2. Deep research and long-form synthesis
ResearchRubrics at 65.3 is the number that should reframe how you think about this model. The benchmark uses a ReAct agent loop planning, searching, reflecting, writing to evaluate long-form research quality. Step-3.5-Flash outscores Gemini DeepResearch, OpenAI DeepResearch, and Step-DeepResearch, all of which are purpose-built research systems from well-resourced labs.
The xbench-DeepSearch score of 83.7 on the 2025.05 version reinforces this: Step-3.5-Flash is genuinely good at the retrieve-reason-synthesize loop that deep research requires. For teams building research agents, document analysis pipelines, or any workflow where the model needs to navigate large information spaces and produce structured outputs, this is a serious option.
3. Competition-level reasoning tasks
AIME 2025 at 97.3 and IMOAnswerBench at 85.4 are not just benchmark wins — they signal that the model’s reasoning depth on symbolic manipulation and proof construction is frontier-class. For applications that require rigorous logical reasoning formal verification assistance, mathematical proof checking, complex constraint satisfaction — Step-3.5-Flash operates at a level most open-source models don’t reach.
4. Privacy-sensitive local deployments
This is where the architecture choice becomes a strategic differentiator. Step-3.5-Flash runs on Apple M4 Max, NVIDIA DGX Spark, and AMD AI Max+ 395. On the DGX Spark, it achieves 20 tokens per second with INT8 KVCache and supports a 256K context window on-device, air-gapped, zero data leaving your hardware.
For enterprises with compliance requirements, healthcare organizations handling patient data, or any team that cannot send prompts to an external API, a 196B model that fits on high-end consumer hardware and delivers frontier reasoning is a category of its own. There is currently no other open-source model in the S-tier that combines this benchmark profile with this deployment accessibility.

Where it doesn’t belong
This is the section most model coverage skips. Here is what the StepFun technical report actually discloses and what the benchmark table reveals on honest reading.
Multi-turn conversational AI is a known weak point. The technical report flags instability in long-horizon multi-turn dialogues the kind of degradation where response quality drops or coherence breaks after many turns in a single session. For customer-facing chat products or long-running assistant workflows, GLM-5 or Kimi K2.5 are stronger choices. Both have higher Chatbot Arena ELO ratings and better-established multi-turn stability.
Mixed-language output is a real risk. The report notes potential for mixed-language responses Chinese leaking into English outputs or vice versa — particularly in edge cases involving bilingual prompts or code-switching inputs. If your application serves a monolingual English audience, test this extensively before committing. It is not a constant failure mode, but it is frequent enough to flag.
Time and identity awareness has known gaps. The model shows inconsistencies around temporal reasoning and self-identification in certain prompting patterns. For applications where the model needs to accurately represent what it knows, when it was trained, or what it is, these gaps matter.
Standard consumer hardware is simply not viable. The model requires 128GB or more of unified memory for local deployment. Apple M4 Max qualifies. A MacBook Pro M3 with 36GB does not. If your team’s deployment target is anything below workstation-class hardware, this model cannot run locally you are API-dependent, which reintroduces the cost and latency considerations you were trying to avoid.
The honest placement
Step-3.5-Flash is a specialist, not a generalist. The models that top Chatbot Arena GLM-5 at 1451 ELO, Kimi K2.5 at 1447 are optimized for the broad, unpredictable demands of conversational AI. Step-3.5-Flash was optimized for something different: deep reasoning, agentic execution, and inference efficiency under compute constraints.
If your stack has a slot for a model that needs to think hard, act autonomously, and run cheaply this is the model for that slot. If your stack needs a model that chats well across thousands of unpredictable user inputs, look elsewhere.
That distinction is what makes it genuinely useful rather than just benchmark-impressive.
The Close
For the last three years, the default question when evaluating a new model has been: how many parameters does it have? Bigger was assumed to be better. The parameter count became a proxy for capability, and the labs that could afford to scale OpenAI, Google, Anthropic — held a structural advantage that felt permanent.
Step-3.5-Flash is evidence that this frame is breaking.
196B total parameters. 11B activated per token. S-tier benchmark scores across reasoning, coding, and agentic tasks. A decoding cost 18.9x lower than Kimi K2.5 at equivalent context. Local deployment on workstation hardware. A deep research score that beats purpose-built systems from OpenAI and Google.
The parameter count tells you how much a model knows. The activated parameter count tells you what it costs to use that knowledge. Step-3.5-Flash has optimized the ratio between those two numbers more aggressively than almost any model currently available — and the benchmark table shows that the optimization did not come at the cost of capability.
StepFun calls this intelligence density. It is the right frame for 2026. As MoE architectures become standard across the S-tier — Kimi K2.5 at 1T total with 32B active, MiniMax M2.5 at 230B with 10B active, Step-3.5-Flash at 196B with 11B active — the question is no longer which model is biggest. It is which model delivers the most reasoning per activated parameter, at what cost, on what hardware.

What this means for your stack right now
If you are running any production AI system where cost, latency, or data privacy matters — and you have not evaluated Step-3.5-Flash — you are making allocation decisions with incomplete information.
The API is accessible. The technical report is public. The benchmark comparisons are reproducible. The deployment path on high-end hardware is documented. There is no technical barrier to running an evaluation. The only reason not to is the same reason most developers hadn’t heard of this model before reading this article: it didn’t come with a PR campaign.
That is not a good reason.
Run the benchmarks on your tasks. Test it in your agentic pipeline. Compare the inference cost against whatever you are currently running. You may find it doesn’t fit — the limitations are real and the use cases are specific. But you should find that out from your own data, not from the absence of a viral launch tweet.
What’s Next
Step-3.5-Flash won’t be the last underreported model worth your attention. The open-source landscape in 2026 is moving faster than the coverage can keep up with — and the models that don’t speak English fluently to their PR teams are consistently the ones getting missed.
If this kind of analysis is useful to you, I’ve been running similar deep-dives on other models sitting outside the mainstream conversation. Kimi K2.5 got the same treatment — benchmarks, architecture, honest limitations, and what actually happens when you drop it into a real coding workflow. GLM-4.7 is on the list. So is the broader question of how you build a stack that routes intelligently between all of these rather than defaulting to whatever got the most coverage last week.
The open-source model landscape has never been more capable or more confusing. The only way through it is to read the technical reports, run your own numbers, and ignore the noise.
That’s what I’ll keep doing here.
If you found this useful, follow me for more no-fluff breakdowns on open-source models, LLM efficiency, and the parts of AI engineering that don’t make the mainstream feed.
I write about the models worth knowing before everyone else catches up the architecture decisions that actually explain the benchmarks, the deployment realities that the launch posts skip, and the cost tradeoffs that matter when you’re building something real.
Next up: GLM-4.7 gets the same treatment — S-tier benchmarks, 355B parameters, the highest Chatbot Arena ELO on the open-source leaderboard right now, and almost zero serious English-language coverage. If that’s something you want to see, hit follow.
This 196B Open-Source Model Beats Claude Opus 4.5, was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.