How NLP kept running into the limits of language — until words stopped being labels and became relations

In the first post, we saw how language models turn text into tokens and tokens into numbers.
In the second post, we stayed with a deeper question:
Once words become numbers, how does meaning not disappear?
And in the third post, we entered Word2Vec itself — the moment words stopped being treated merely as labels and began to be treated as positions in a learned relational space. But that naturally raises another question:
How did the field arrive at Word2Vec at all?
Did it begin with TF-IDF? With n-grams? With statistics? With neural networks? The honest answer is: all of them, but not in the same way. What makes the journey interesting is that NLP did not simply become smarter in a straight line. It kept running into the same deeper problem:
language is richer than the representation we are currently using
And each time the field hit that wall, it had to revise its imagination of what a word even is. That is the real story.
At first, a word was treated like a name. Then it became a count. Then a weighted signal. Then part of a local sequence. Then a contextual footprint. And finally, with Word2Vec, a word became a position in a learned field of relations.
That is the road we are tracing.
Along the way, NLP was also learning a related but different lesson: language is not only made of words, but of sequences. So this journey has two intertwined threads — how words are represented, and how word order is modeled.

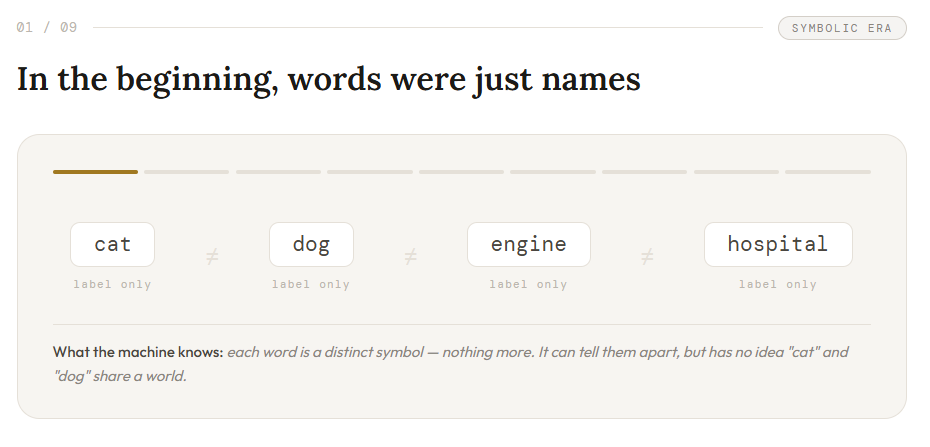
In the beginning, words were just names
The earliest computational treatment of language was almost unavoidable.
Before a machine can “understand” language, it must at least distinguish one word from another. So the first move was simple: treat words as symbols. A system could know that it saw:
- cat
- dog
- engine
- hospital
That already mattered. It gave the machine identity. But identity is not relation. A symbol tells the machine:
this token is different from that token
It does not tell the machine:
this token is similar to that one
this token belongs in the same semantic region as that one
this token often lives in worlds like those other tokens
In that first worldview, words were almost like labeled boxes on shelves. Useful to sort. Not yet useful to relate. That was the first wall. The machine could distinguish words, but it could not yet feel the space between them.
So the field did the practical thing: it started counting
Once words could be separated into symbols, the next obvious move was:
Fine. If we cannot represent meaning deeply yet, can we at least represent occurrence?
That led to bag-of-words. Now text could be turned into a vector of counts:
- how many times does “battery” appear?
- does this review contain “refund”?
- how often do we see “error”?
This was a huge step. For the first time, text could be processed numerically at scale. Search systems, classifiers, and document analysis became much more feasible.
But the cost of that simplification soon became obvious. To count efficiently, the field largely stopped caring about order. So these two sentences looked suspiciously similar:
- dog bites man
- man bites dog

Same words. Similar counts. Very different meaning. That was the next lesson:
turning language into numbers is not the same as preserving its structure
Bag-of-words was powerful. But it flattened language. Words had become measurable, but not yet alive in relation.
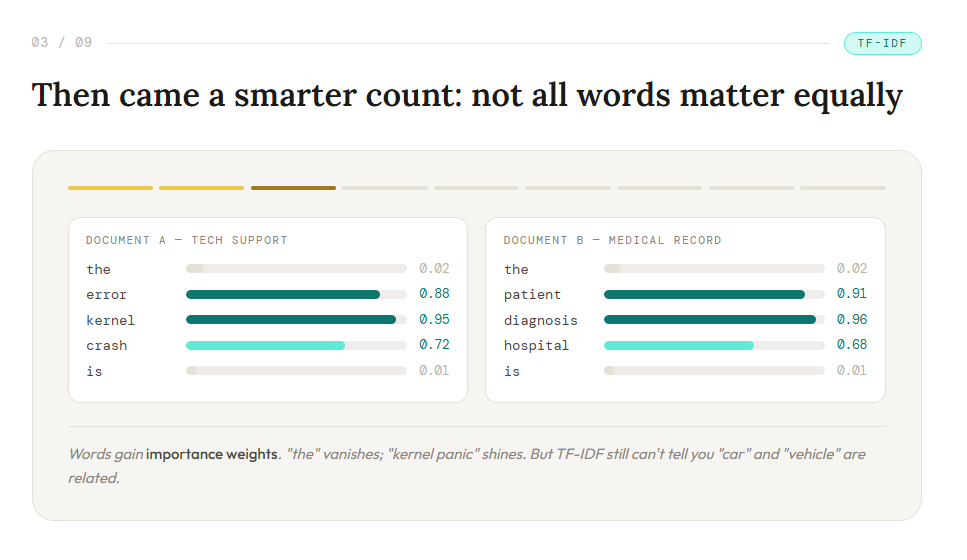
Then came a smarter count: not all words matter equally
Once counting worked, the next dissatisfaction appeared quickly.
A word like the may appear everywhere. A phrase like kernel panic may appear rarely, but when it does, it tells you much more. So the field refined counting into weighting.
That gave us TF-IDF. Its idea was elegant:
- a word matters if it is frequent in this document
- but not so common across all documents that it becomes generic noise
This was a major improvement.
Now the system was not just counting words. It was learning to ask which words are actually informative. That changed retrieval dramatically. But another limit appeared.
TF-IDF could tell you that a word is important in a document. It could not tell you that two different words are related in meaning.
It could not naturally tell you:
- car is close to vehicle
- doctor belongs near hospital
- cat and dog often inhabit similar semantic worlds
So the field learned another hard lesson:
importance is not the same as meaning
TF-IDF made document vectors smarter, but it did not yet make words relational. A word was still mostly a weighted feature, not a living participant in a semantic neighborhood.
Then NLP remembered something language itself never forgot: local order matters
By now, the field had learned to identify words and count them intelligently.
But something still felt wrong. Language does not merely contain words. Language unfolds.
“The cat drinks” carries a different expectation from “drinks the cat.”
“Man bites dog” and “dog bites man” do not live in the same world.
So the field moved toward n-gram language models. This was a real conceptual shift. n-gram models were not word representations in the modern embedding sense, but they were a crucial conceptual bridge because they reintroduced local order into NLP. Instead of focusing only on what words appear, the system began asking:
given the last few words, what word is likely to come next?
Now language was being treated not as an unordered bag, but as a local sequence. This was a major advance. The model could now learn short-range expectations like:
- “the cat drinks” → likely “milk”
- “the dog chases” → maybe “ball”
This brought order and momentum into NLP. But once again, the field hit another wall.

n-grams were good at remembering what had been seen. They were not good at generalizing beyond what had been seen.
If the system had often seen:
- the cat drinks milk
but had not seen:
- the dog drinks milk
it might still struggle.
Why?
Because cat and dog were still separate entries in a statistical table. The system knew sequence fragments, but it did not yet know that some words play similar roles in similar contexts.
So the next lesson arrived:
sequence is necessary, but exact sequence memory is too brittle
In other words, n-grams could model short-range sequence patterns, but they still did not give words reusable semantic identities that could generalize across contexts.
Language needed something more than local order. It needed a way for similarity itself to become part of representation.
So even after NLP had learned to count words and model short local order, it still lacked something deeper: a way to represent similarity itself. The field could often tell what had appeared and what tended to follow, but not yet what kinds of words belonged in similar semantic neighborhoods.
Then came the deeper question: what if meaning lives in company?
This is where the story starts becoming truly interesting. After symbols, counts, weights, and local sequences, the field began taking seriously an older linguistic intuition:
You shall know a word by the company it keeps.
That sentence changes everything. Because now the question is no longer only:
- What words are in this document?
- Which of them matter most?
- What word comes next?
Now the question becomes:
What kinds of other words tend to appear around this word?
That was a much deeper move. A word was no longer treated as a self-contained unit waiting for a definition. It was treated as something that leaves behind a contextual signature. This is the heart of distributional semantics.

Meaning was no longer being imagined as a fixed essence inside a word. It was now being imagined as a pattern of relations. A word was becoming less like a sealed object and more like a node in a web. That is one of the deepest shifts in the whole history of NLP.
So the field built local worlds around words
Once that intuition took hold, researchers began constructing word-context co-occurrence matrices. This was no longer just about documents and counts. It was about neighborhoods. For a word like cat, the system might observe nearby terms like:
- milk
- mouse
- fur
- pet
- sleep
For a word like engine, it might observe:
- fuel
- oil
- car
- machine
- power
Now similarity started becoming something more meaningful.

Two words could be considered related not because humans had explicitly linked them, and not because they appeared in the same document, but because they inhabited similar contextual environments.
That was a huge step. Because here the field was essentially admitting something radical:
maybe the meaning of a word is not inside the word at all
maybe meaning is distributed across the worlds that word tends to inhabit
That is a profound change in imagination. A word is no longer a container. It becomes a pattern of participation.
But raw context counts were too heavy and too literal
There was still a problem.
These co-occurrence matrices were large, sparse, and awkward. They held useful information, but in a surface-level form that was clumsy to use.
So the next move was compression.
Methods like Latent Semantic Analysis (LSA) and Latent Semantic Indexing (LSI) pushed NLP toward compressing large sparse count structures into smaller latent spaces. This mattered for a deeper reason than computational efficiency.

It meant the field was beginning to say:
maybe the visible surface of language is not where meaning fully lives
maybe meaning lives in lower-dimensional hidden structure underneath
That is a beautiful step.
The raw counts were the surface. The latent space was an attempt to uncover the shape beneath the surface. In hindsight, this is one of the clearest stepping stones toward embeddings. The field had not yet reached Word2Vec. But it was already learning to suspect that the chaos of language might hide a deeper geometry.
Then neural language models changed the role of vectors themselves
Up to this point, vectors were often things we built from counts or decompositions. But neural language models introduced a more radical idea:
maybe vectors should not just summarize words after the fact
maybe they should be learned inside a predictive system
In that sense, neural language models inherited the predictive spirit of n-grams — but instead of relying only on exact count tables over short contexts, they began learning internal representations that could generalize.
Low-dimensional representations were not entirely new — latent semantic methods had already pointed in that direction — but neural models made those representations trainable inside the objective itself.

This was enormous. Now vectors were no longer only handcrafted statistics or compressed tables. They became learned internal representations. This changed the nature of the story.
Meaning was no longer just something extracted from data. It was something that could emerge through training.
A model could begin with random numbers and, through repeated exposure and correction, slowly organize those numbers into something useful. That is much closer to how we now think about embeddings. And it set the stage for the next great simplification.
Then Word2Vec arrived — and made the whole journey suddenly feel clear
Word2Vec did not appear from nowhere. What made it powerful was that it gathered many older intuitions into one clean idea:
learn a word vector by making nearby words predictive of one another
That was the breakthrough.
Not because context was a brand new idea.
Not because vectors were new.
Not because prediction was new.
But because Word2Vec made the field feel, perhaps for the first time, like it had found the right center of gravity.
Now words were not just:
- labels
- counts
- weighted features
- short sequence fragments
- rows in sparse context tables
They became points in a learned relational space
So:
- cat drifted toward dog
- car drifted toward truck
- doctor drifted toward nurse
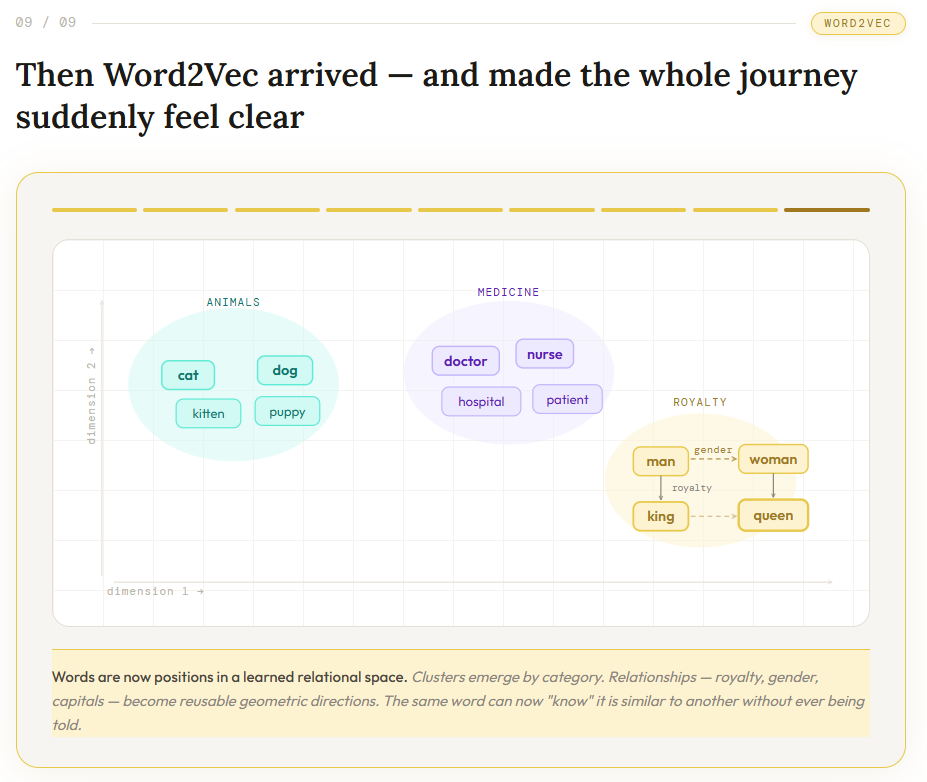
And that shift felt satisfying because it matched something the field had been slowly discovering all along:
words gain meaning through the worlds they repeatedly inhabit
Word2Vec did not invent that truth. It gave it a practical, scalable, elegant form. At the same time, Word2Vec did not finish the story of meaning. It changed the direction of the story. Once words became positions in a learned space, the next question became visible almost immediately:
Should a word always stay in one fixed place?
That would become the next major chapter.
The calm takeaway
Word2Vec did not come from a single invention. It emerged because NLP kept discovering, again and again, that language was richer than the representation it was currently using.
— Bag-of-words taught the field to count.
— TF-IDF taught it to weigh.
— n-grams taught it to model local sequence and prediction, even though they still did not learn semantic word representations.
— distributional methods taught it that context carries meaning.
— latent semantic methods taught it to look for hidden structure.
— neural language models taught it to learn vectors instead of handcrafting them.
And then Word2Vec brought those currents together into one elegant idea:
learn meaning by learning which words live near which other words
That is why Word2Vec was not merely another technique. It was the moment words stopped being treated as isolated labels and began to live inside a relational geometry. And once that happened, the door was open for later models to ask an even deeper question: not only how words relate in general, but how meaning changes as context unfolds.
One-line memory hook
Before Word2Vec, NLP learned to count, weigh, and sequence words. With Word2Vec, it finally learned to let words live in relation to one another — opening the door to later models that made those relations dynamic.
Before Word2Vec: The Strange, Fascinating Road from Counting Words to Learning Meaning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.