I Ran the Same Multi-Agent Prompts on Claude Code, Codex, and Cursor. Here’s What Actually Happened.
A hands-on comparison of three multi-agent coding systems across research, data extraction, and bug-fix coordination tasks
I’ve been intrigued by the “multi-agent” concept lately — the idea that you can spin up a whole team of AI agents to work for you while you sip coffee and watch them grind.
So I ran a series of controlled experiments using three of the most widely discussed multi-agent coding tools right now: Claude Code 4.6, Codex 5.3, and Cursor 2.4. Same prompts. Preserved every trace and artifact. Then I sat down to figure out what the evidence actually says, and what each system’s observable behavior reveals about its underlying philosophy — and where that philosophy creates specific, predictable strengths and blind spots.
1. The Prompts
I gave all three systems three different multi-agent tasks. Each one was designed to stress a different capability.
Prompt 1

This tested how each system structures a multi-agent workflow when the deliverable is a formatted artifact, and whether it produces working code alongside the data.
Prompt 2

This was the most direct test of parallel agent execution, research breadth, QA behavior, and output accuracy under ambiguity. It also ended up being the most interesting test to analyze.
Prompt 3

This tested role boundary enforcement, inter-agent coordination, and — crucially — whether any system would actually run the server and verify the fix, rather than just call it done.
2. Findings
2.1 The Fundamentally Different Mental Models of “Multi-Agent”
These systems don’t just implement multi-agent differently — they disagree about what the concept means. Only Claude Code draws a formal architectural distinction between two levels of agent coordination. Codex treats multi-agent as a software engineering problem. Cursor treats it as a file-system workflow.
Claude Code : Subagents and Agent Teams are genuinely different things
Claude Code is the only system of the three that formally distinguishes between two modes of multi-agent operation, and the difference is architecturally meaningful — not just a naming choice.
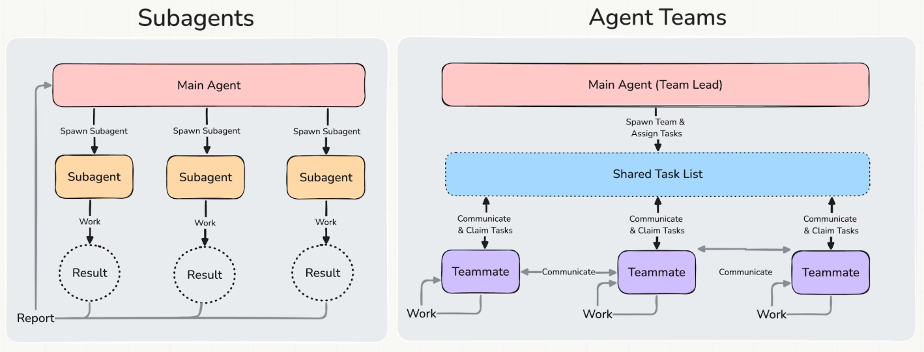
In my Test 3 trace, Claude Code used the subagent model: the orchestrator dispatched a backend agent with a fully specified prompt — including an explicit “you are NOT allowed to read main.py” constraint for the frontend agent — received results back, and assembled the summary.
In Test 2, the structure was more consistent with Agent Teams: a QA agent was placed on explicit standby, and only unblocked once both researchers had delivered.
The existence of two distinct primitives is itself a signal. Anthropic has clearly thought carefully about when parallelism alone is enough vs. when genuine lateral communication is necessary. No other tool in this comparison makes that distinction.
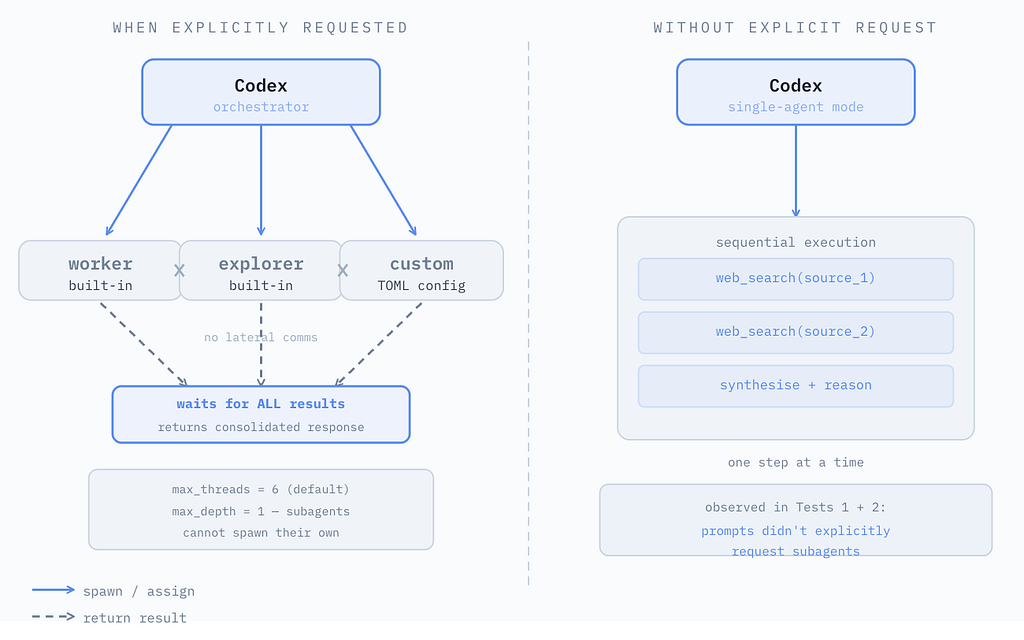
Codex : Native subagents, but only on explicit request
Codex has a real subagent system, enabled by default. The key constraint: without an explicit request, it runs as a single sequential agent.
In Test 1, the trace shows Codex designing four Python classes — CatalogScoutAgent, ModelSpecialistAgent, NormalizerAgent, ExcelReporterAgent — and using ThreadPoolExecutor to run them. The agents in Codex’s world are not separate model instances; they are objects in a Python program that Codex writes, runs, and delivers as a repo artifact.
There’s a nuance worth calling out though: the prompt asked for agents doing web research across different sources simultaneously. What Codex delivered was parallel dictionary lookups over a single pre-fetched dataset. It reframed the research problem as an engineering problem and solved the engineering problem excellently — but the parallelism is doing much lighter work than it appears.
Importantly, Codex only spawns subagents when you explicitly ask it to. In Test 1 and 2, the prompts said “spin out 3 agents” and “spin up an agent team,” which sounds explicit enough, but Codex interpreted the intent as an engineering task rather than an orchestration request.
Cursor : Multi-agent as parallel file-system operations
Cursor’s model is the most literal interpretation of parallelism: separate agents, separate files, separate outputs.
In Test 2, the trace shows Agent 1 producing kimi_official_pricing.json, Agent 2 producing kimi_third_party_providers.json, and the QA agent producing both moonshot-quality-check-report.json and moonshot-quality-check-summary.md.
In Test 3, Cursor created API_CONTRACT.md at the project root and told the frontend agent to use it. That file is simultaneously a coordination mechanism and a repo artifact — it persists, it’s version-controllable, and it serves as living documentation.

2.2 Real vs. Performed vs. Coded Parallelism
All three systems claim to run agents in parallel. The nature of that parallelism differs dramatically.
Claude Code : Parallel execution evidenced by orchestration behavior
In Test 2, the trace shows a clear orchestration sequence: both researchers launched simultaneously, QA placed on standby, orchestrator reporting “both researchers are done” before forwarding outputs.
The strongest evidence is behavioral: the QA agent’s explicit wait-and-unblock pattern is difficult to fake without real asynchronous execution.
But the evidence lives in the conversation, not in independently created files — you’re trusting the system’s self-report to some degree.

Codex : Parallelism coded into the artifact, sequential in practice
The ThreadPoolExecutor in Test 1 is real concurrent execution. But as noted above, it parallelizes extraction from an in-memory list — the I/O, the expensive part, already happened before any “parallel” work began.
In Test 2 — the Kimi pricing prompt — Codex ran as a single sequential agent: one web search at a time, with careful reasoning in between. Thorough, methodical, not parallel. The trace is a clear sequential log with no ambiguity.
Cursor : Parallel execution evidenced by independent file artifacts
Cursor gives you the most verifiable evidence of parallelism: two JSON files with independent content from different sources, created within the same run.
This is worth sitting with. A status table or elapsed-time claim can, in principle, be produced by a sequential system with a parallel-looking interface. A file system with two independently authored JSON files with different content cannot.
Artifact evidence is the gold standard for verifying parallel execution, and Cursor is the only system here that produces it.
2.3 Error Transparency vs. Smoothness
The smoother and more polished a system’s output, the less it tends to surface limitations, access failures, and inferential assumptions. The rough edges in execution traces are often the most analytically important signal.
Claude Code : Smooth output, confidence without granularity
Claude Code’s outputs are polished. The analysis is genuinely useful, the confidence scores are per-provider, and the synthesis is easy to consume.
What the presentation smooths over: the official Moonshot pricing page was JS-rendered and not fully text-extractable. Claude Code does not prominently flag this — it synthesizes from what it could access and presents conclusions confidently. The source access limitation is buried rather than foregrounded.
Codex : Explicit about what it could not access
Codex’s Test 2 output includes a scope_note field: “Official Moonshot pricing docs are JS-rendered and not fully text-extractable in this environment, so official values were taken from Moonshot’s own pricing chart image and changelog/news posts.”
In Test 1, when the live network fetch failed, Codex produced a Warnings section and documented the fallback explicitly. It did not hide the failure; it logged it, explained it, and continued.
Cursor : Structured output, limited error commentary
Cursor’s QA agent in Test 2 flagged specific mismatches — cache-hit vs. cache-miss pricing, model ID inconsistencies, casing differences across providers . That is genuine QA, not just a summary.
What Cursor does not do is narrate its own execution difficulties. If an agent hit a JS-rendered page, it either worked around it or quietly excluded that source. The repo artifacts are clean and structured; the execution friction is invisible in them.
That is entirely consistent with Cursor’s philosophy — the deliverable is the file, and the file should be clean.
2.4 Engineering Quality vs. Research Completeness
Claude Code : Widest research net, richest synthesis
In Test 2, Claude Code’s researchers covered 9 providers and 11 pricing entries . The QA agent went beyond identifying mismatches: it explained probable causes (quantized FP4 serving for DeepInfra’s lower prices, reduced context windows for Together AI’s higher prices, intermediary distortion for OpenRouter). The Excel output from Test 1 was also genuinely polished and business-presentable.
One thing I noticed though: even when I asked for JSON output in Test 2, Claude Code still prioritized conversational output and communication clarity over strict schema compliance. The JSON was there, but it wasn’t the primary thing. If your downstream system depends on clean structured data, that’s worth knowing.
The broader cost of this approach: the research synthesis lives in the conversation. It’s not easily versioned, parameterized, or re-run against updated data.
Codex : Deepest per-source precision, code that outlasts the session
In Test 1, Codex produced a Python script that is a genuine software artifact: typed dataclasses, graceful network failure handling, offline snapshot fallback, clean separation of concerns across four agent classes.
When openpyxl was not available in the sandboxed environment, Codex assembled the .xlsx format manually using zipfile.ZipFile. That’s an engineering workaround — the kind of thing you’d expect from a senior engineer hitting an environmental constraint, not from a research agent.
In Test 2, Codex found only three providers — but its pricing breakdown was the most granular. Cached input prices listed separately for each, confidence scores broken out by claim type , and a flag noting the official Moonshot chart may apply only to the turbo series — a precision caveat neither Claude Code nor Cursor surfaced.
Cursor : Highest artifact discipline, middle-ground research
Cursor found 4 providers and produced the cleanest JSON structure. Every output was a repo file with a consistent schema. The QA agent’s output included a model ID mapping table that would slot directly into production code. Cursor’s outputs are most useful if you’re building something with the data. They’re less useful as a standalone research survey.
2.5 Verification Behavior
Only one system — Codex — actually ran the server and confirmed the fix. This is the difference between a code reviewer and an integration tester.
Claude Code : Correct by inspection
In Test 3, Claude Code fixed all five bugs correctly. Both agents worked from a shared api_contract.md that the backend agent wrote. The frontend agent read only the contract — not the backend source.
The fixes were accurate. But no server was run. The orchestrator’s final summary presented the fix as complete based on code inspection alone.
Codex : Live runtime verification as a default behavior
After making its code changes, Codex ran python3 and node.js fetch(), started the FastAPI server, hit /health and /api/users and confirmed the final output.
That is end-to-end evidence that the integration works — not an assertion that it should. It reflects Codex’s underlying model of what “done” means: a task is complete when you have runtime proof, not when the code analysis says it should work.

Cursor : Contract-driven, not runtime-verified
The API_CONTRACT.md file created in Test 3 is a legitimate coordination mechanism. The fixes were correct. But like Claude Code, Cursor did not run the server. The verification was structural: “the contract says X, the code now implements X.” Whether it actually works over the wire was left as an assumption.
Closing: Which One Should You Choose?
Let me compare each system in human terms to make it easier to understand.
Claude Code : The senior analyst who happens to write excellent code
Claude Code researches broadly, synthesizes confidently, enforces role boundaries through explicit instruction, and produces the richest human-readable outputs. It is the most expressive multi-agent system in this comparison — and the only one with a formal architectural distinction between two levels of agent coordination, which tells you something about how seriously Anthropic has thought about the problem. Its weakness is verification: “done” means the analysis is complete and coherent, not that the system has been confirmed to run.
Codex : The senior engineer who also does research
Codex builds reusable infrastructure, runs things before calling them done, and explicitly labels what it knows versus what it is inferring. It finds fewer sources and covers fewer providers, but it trusts what it has more rigorously. When you ask it to “run agents,” it may write a program that models the agent team rather than spawning live instances — which is a feature if you want a reproducible, deterministic pipeline, and a constraint if you want broad live research.
Cursor : The DevOps engineer who cares deeply about the repo
Every output is a file, every coordination mechanism is a document, and the evidence of work is the artifact that persists after the session ends. Cursor is the most repo-native of the three and the easiest to wire into a CI/CD workflow. Its weakness is verification: correct changes, not confirmed ones.
The most important thing I took away from these experiments is not which system is best. It’s that “multi-agent” is not a feature — it’s a design philosophy, and the philosophy determines what the system considers done.
(Thank you for reading! I always appreciate thoughtful feedback and reflections. Feel free to connect with me on LinkedIn or X if you’d like to exchange ideas or discuss further :)
I Ran the Same Multi-Agent Prompts on Claude Code, Codex, and Cursor. Here’s What Actually Happened was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.