Rethinking Open-Source AI Deployment

From cost-prohibitive closed systems to truly capable, flexible open models — Gemma 4 is changing the game for developers seeking genuine intelligence without compromise.
I remember the sting of that moment, hunched over my laptop at 2 AM, debugging an open-source LLM agent. It was supposed to automate a complex data analysis task, a multi-step workflow involving dynamic queries and conditional logic. Instead, it was looping endlessly, making elementary reasoning errors, costing precious cloud credits, and pushing my “AI pilot” project firmly into a state of purgatory. I felt a familiar frustration: the dream of accessible, powerful open AI often crashed against the rocks of actual implementation.
We’ve all been there. You want the flexibility, the cost-efficiency, and the ownership that open models promise. Yet, the moment your ambitious AI agent needs to perform truly advanced reasoning or manage intricate, multi-stage agentic workflows, many open-source options suddenly feel… limited. They struggle with context, falter on planning, and often deliver outputs that are more “creative” than “correct.” This is precisely the chasm Gemma 4 aims to bridge.
Gemma 4 represents a significant leap for open models, offering unprecedented capabilities in advanced reasoning and agentic workflows previously reserved for larger, proprietary systems. It provides developers with powerful, efficient, and customizable foundations for building intelligent AI agents, optimizing deployment costs and fostering innovation in the open-source community.
Why are most open models still falling short on complex reasoning?
For a long time, the open-source landscape felt like a playground for smaller, less capable models, or larger ones that were a nightmare to run locally. If you wanted something truly smart, something that could parse a complex request, break it down into sub-tasks, execute them sequentially, and learn from feedback — you were often pointed towards the towering, expensive walls of proprietary APIs. It felt like asking a junior intern to manage a Fortune 500 company’s strategic planning.
The core issue lies in the nuances of “reasoning.” It’s not just about spitting out coherent sentences. It’s about understanding implied intent, connecting disparate pieces of information, planning multi-step solutions, and even self-correcting. Many open models, while excellent at text generation, falter when presented with tasks requiring genuine cognitive flexibility, like those found in sophisticated AI agent workflow optimization. They might ace a single-turn question but crumble on a chain of thought.
Imagine trying to teach a complex recipe to a robot that only understands one instruction at a time. It’ll follow “chop onions,” but struggle with “now, sauté them until translucent while simultaneously prepping the garlic.” Advanced reasoning, the kind we need for robust customizable AI solutions, requires connecting these dots intelligently and proactively. This often translates into fragile agentic systems prone to errors, expensive retries, and developer burnout.
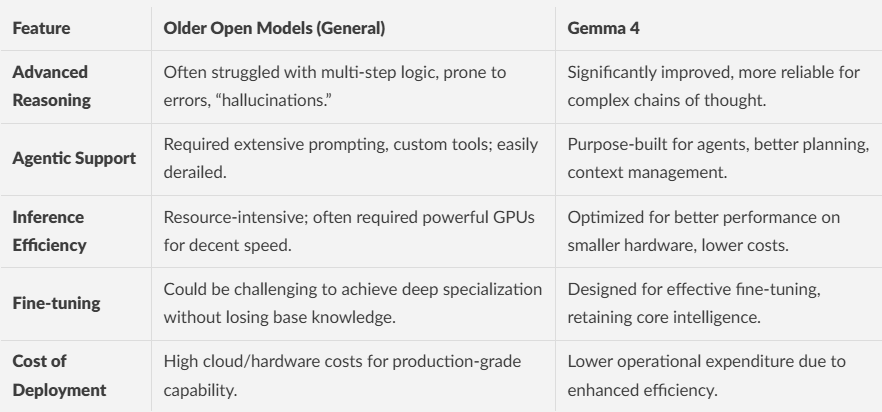
Bottom Line: Older open models often lack the deep reasoning and planning capabilities essential for robust, autonomous AI agents, leading to brittle and expensive implementations.
Can open models truly compete with proprietary giants on efficiency and cost?
Here’s another common headache: even if you find an open model with decent capabilities, actually deploying open models for real-world applications can feel like a financial trap. Large, capable models demand serious hardware — think multiple high-end NVIDIA B200 GPUs or substantial cloud instance allocations. This quickly negates the “free” aspect of open source. Suddenly, your promising prototype hits a wall of escalating operational expenditure, often making it unfeasible for production, especially for startups or smaller teams.
The challenge is multi-faceted. Training a model is one thing, but running inference at scale, efficiently and cost-effectively, is another beast entirely. Quantization techniques help, but often come with a performance hit. Fine-tuning an open model to your specific data can be transformative, but the initial model size often dictates the computational resources needed for that process, too. It’s like trying to run a formula one race with a standard SUV; it might technically work, but you’ll burn through fuel and wear down the engine at an alarming rate.
This tension between capability and cost has long forced a difficult choice: sacrifice performance for affordability, or break the bank for state-of-the-art results. Developers managing cloud costs are constantly looking for models that punch above their weight, delivering intelligence without the exorbitant infrastructure demands. Without this balance, many innovative projects remain trapped in the proof-of-concept phase, unable to scale.
Bottom Line: The high compute and inference costs associated with many large open models make scaling intelligent AI solutions financially challenging for many developers and businesses.
Introducing Gemma 4: The Byte-for-Byte Breakthrough
This brings us to Gemma 4, Google DeepMind’s latest entry into the open-model arena. The core promise here isn’t just “another open model.” It’s about delivering byte-for-byte, the most capable open models for critical applications like advanced reasoning and truly functional AI agent workflow optimization. It’s engineered from the ground up to offer a powerful blend of intelligence and efficiency.
What makes Gemma 4 stand out? It leverages the architectural innovations of Google’s flagship Gemini models, bringing that high-fidelity intelligence down to a more accessible scale. This isn’t just about making models smaller; it’s about making them smarter within their given parameter count. Imagine taking a highly skilled artisan and teaching them to create masterpieces with fewer, more precise tools — that’s the kind of optimization at play.
This means a model that can process complex instructions, reason through multi-step problems, and maintain coherence across longer interactions, all while being significantly more resource-efficient than comparable models. For developers, this translates into more intelligent applications, faster iteration, and a real chance to deploy sophisticated AI agents without massive infrastructure investment. It’s a huge step towards making advanced AI truly practical and widespread.
Bottom Line: Gemma 4 provides Gemini-level intelligence in an open, efficient package, making advanced reasoning and agentic capabilities accessible to a broader developer community.
The Engineer’s Workbench: Where Does Gemma 4 Shine?
Let’s get down to the brass tacks: what can you actually do with Gemma 4 that was previously difficult or impossible with open models? Its capabilities are particularly exciting for anyone building dynamic, intelligent systems.
If you’re building autonomous agents that need to act intelligently: Consider a scenario in financial analysis where an agent needs to pull data from multiple APIs, analyze market trends, predict outcomes based on complex rules, and then suggest actionable trades. Older open models might fail at the synthesis or decision-making steps. Gemma 4’s enhanced Gemma 4 capabilities in reasoning make this kind of multi-modal, multi-step process far more robust, reducing the need for constant human oversight and error correction.
If you are a developer managing cloud costs for AI deployments: The improved efficiency of Gemma 4 means you can get more intelligent inference for fewer computational cycles. This directly translates to lower bills from AWS, Azure, or GCP. For edge AI inference or on-device applications, where resources are severely limited, Gemma 4 could be a game-changer, allowing sophisticated AI to run where it simply couldn’t before.
If you need custom, private AI solutions for sensitive data: The open nature of Gemma 4 allows for deep fine-tuning on your proprietary datasets without sending your data to a third-party API. This is crucial for industries like healthcare, legal, or defense, where data privacy and security are paramount. You can tailor Gemma 4 to your specific domain knowledge and workflows, creating a truly bespoke AI that remains under your control. This fosters true customizable AI solutions rather than generic ones.
Bottom Line: Gemma 4 offers tangible benefits for agent development, cost-conscious deployment, and custom, private AI solutions, making sophisticated AI more accessible and practical.
The Reality Check: What Gemma 4 Won’t Do (Yet)
Now, let’s inject a healthy dose of realism. While Gemma 4 is a monumental step forward, it’s not a silver bullet. It’s crucial to understand its current limitations to avoid falling into the hype cycle.
Firstly, no open model, including Gemma 4, is currently going to achieve Artificial General Intelligence (AGI) right out of the box. While its reasoning capabilities are significantly advanced, it’s still a specialized tool. It excels at the tasks it was trained for, but it won’t suddenly gain human-level intuition or common sense. Expecting it to solve every problem without careful prompting and architectural design is setting yourself up for disappointment.
Secondly, while it’s more efficient, “more efficient” doesn’t mean “free.” Running these models, especially the larger variants, still requires compute resources. For highly niche or extremely complex tasks, you’ll still need to invest in thoughtful fine-tuning and potentially more robust infrastructure. The bar is lowered, but it’s not removed entirely. Building a truly performant AI agent still demands engineering skill and careful optimization.
Finally, like all LLMs, Gemma 4 can still “hallucinate” or provide incorrect information, especially when dealing with ambiguous prompts or topics outside its training distribution. While its open-source LLM reasoning is strong, it’s a probabilistic model, not a definitive knowledge base. Always validate critical outputs, particularly in high-stakes applications. This means the human-in-the-loop remains essential, especially in the early stages of agent deployment.
Bottom Line: Gemma 4 is not AGI, still requires compute, and can hallucinate, underscoring the ongoing need for careful engineering and human oversight.
The Engineer’s Verdict: My Take on Gemma 4’s Trajectory
From where I stand, navigating the turbulent waters of AI development, Gemma 4 is a significant buoy for the open-source community. It’s a clear signal that the gap between proprietary behemoths and accessible open models is shrinking, especially when it comes to fundamental intelligence and capability. This release isn’t just an incremental update; it’s a paradigm shift in what we can reasonably expect from publicly available models.
For the developer weary of being locked into specific vendor ecosystems or struggling with the limitations of less capable open alternatives, Gemma 4 offers a compelling new pathway. Its emphasis on AI agent workflow optimization and advanced reasoning means that the dream of truly intelligent, customizable AI agents is now more within reach than ever before. It democratizes access to powerful AI foundations, fostering innovation across the board.
I predict that Gemma 4, and subsequent models built upon its architectural principles, will catalyze a new wave of open-source AI applications. We’ll see more sophisticated edge AI inference solutions, more robust enterprise agents, and ultimately, a much richer ecosystem of specialized, high-performing AI. It’s a reminder that true progress often comes not from walled gardens, but from the collaborative spirit of open innovation.
Bottom Line: Gemma 4 marks a significant milestone, democratizing access to advanced AI capabilities and paving the way for a more robust and innovative open-source AI ecosystem.
What are your thoughts on Gemma 4’s potential? Are you planning to integrate it into your next AI agent project, or do you have reservations? Share your experiences and predictions in the comments below!
Acknowledgements
This article draws heavily from the insightful official announcement:
Gemma 4’s Breakthrough: Why Your Open AI Agent’s Reasoning is About to Level Up was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.