“The devil is in the details.”
This old saying perfectly captures the most significant hurdle in modern artificial intelligence. When we teach machines to see, missing small pixels can lead to massive misunderstandings. Imagine trying to read a blurry street sign from a moving car; if the resolution is low, the text becomes gibberish. In the world of AI, this challenge exists within Vision Language Models (VLMs). These systems combine Large Language Models (LLMs) with visual encoders to understand images and text together, a field known as multimodal learning. The ultimate goal is to capture fine-grained details, such as tiny text in a document or small objects in a complex scene.

The Bottleneck of Traditional Approaches
However, feeding high-resolution images into these models creates a severe bottleneck. Standard approaches flatten an image into a long sequence of visual tokens. These tokens are added to the text before processing begins, creating a memory overhead. The computational cost grows quadratically with sequence length due to the self-attention mechanism. To fix this, engineers previously used compression strategies. Tools like Q-Former, Perceivers, and resamplers reduce the number of visual tokens. A connector or projection module then maps these features to the language model.
These methods save memory but often sacrifice fine-grained details. This is problematic for tasks like Optical Character Recognition (OCR). Reading small text requires precise pixel information that compression often deletes. This limitation led to a novel routing strategy called DeepStack.
Seeing is believing, but understanding requires detail.
Introducing DeepStack: A Vertical Solution
DeepStack changes how visual information enters the model. Instead of dumping all tokens at the start, it stacks them vertically. It injects visual tokens into intermediate layers of the transformer. This is a bottom-to-top feeding strategy.
To understand why this works, we must look at transformer architecture. Researchers study transformers in a top-to-bottom way regarding data flow, but functionally, they operate hierarchically. The earlier layers work as feature extractors. They function similarly to layers in a Convolutional Neural Network (CNN), identifying edges, shapes, and local patterns. The later layers focus on the autoregressive nature of generation. They predict the next word based on previous context. DeepStack leverages this division. It feeds global context early and detailed features into subsequent layers.

Real-World Impact: The Qwen Evolution
This strategy is now used in state-of-the-art models. For instance, Qwen-3-VL implements this routing strategy. Compared to the previous Qwen2.5-VL series, the difference is significant. The newer model handles high-resolution documents with far greater accuracy. It reduces hallucinations where the model invents text that isn’t there. The earlier series struggled with dense information because it relied on flattening long sequences. DeepStack allows the newer version to process fine details without slowing down inference.
The Mathematics of Efficiency: Feature vs. Sequence
A key technical distinction lies in how data is combined. We must distinguish between concatenation along the feature dimension and sequence dimension. Think of tokens as an Excel sheet. Rows represent the sequence length. Columns represent features.
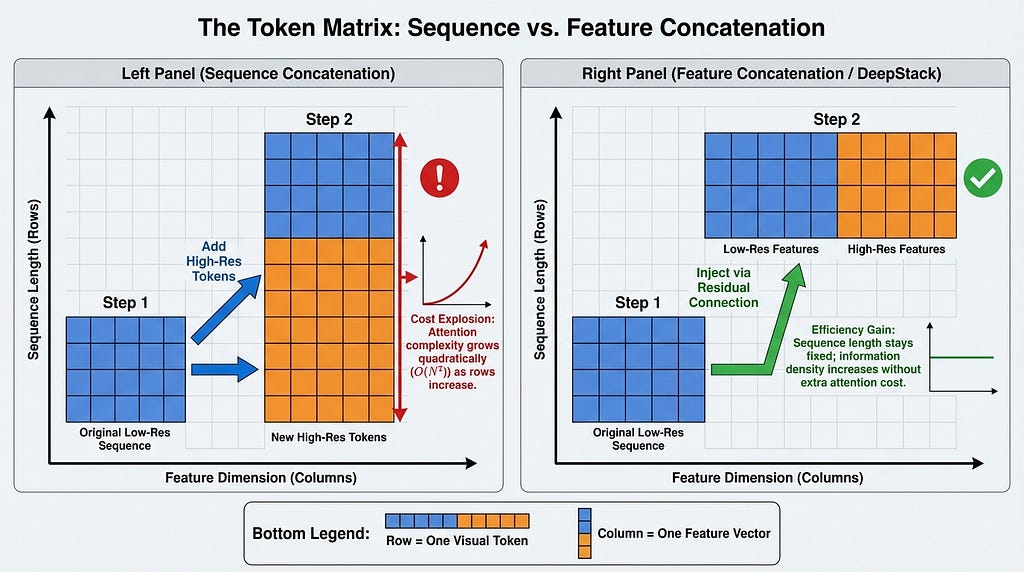
Concatenating along the sequence dimension adds more rows. This increases the context length and computational cost. Concatenating along the feature dimension makes the columns wider. The row count stays the same. DeepStack uses the latter approach effectively by injecting features without adding rows.
Under the Hood: Dual Streams and Spatial Dilation
So, how does it work behind the scenes? The system uses two different streams. One stream processes a low-resolution global view. This establishes the base context. The second stream handles high-resolution local details. It uses patches and cropping to focus on specific areas. The system employs upsampling to increase image size. It also uses spatial dilation. This term means sampling pixels with specific gaps to capture a wider spatial area without increasing the token count. It is akin to looking through a mesh screen to see the big picture while skipping some threads.

This process relies on residual connections. In deep learning, a residual connection allows data to skip layers. It is similar to how ResNet architectures function. ResNet uses skip connections to avoid vanishing gradients in deep networks. DeepStack uses them to inject visual tokens layer-by-layer. The visual tokens are added to the hidden states via residual addition. This preserves the original information while adding new detail.
Limits and Optimization Strategies
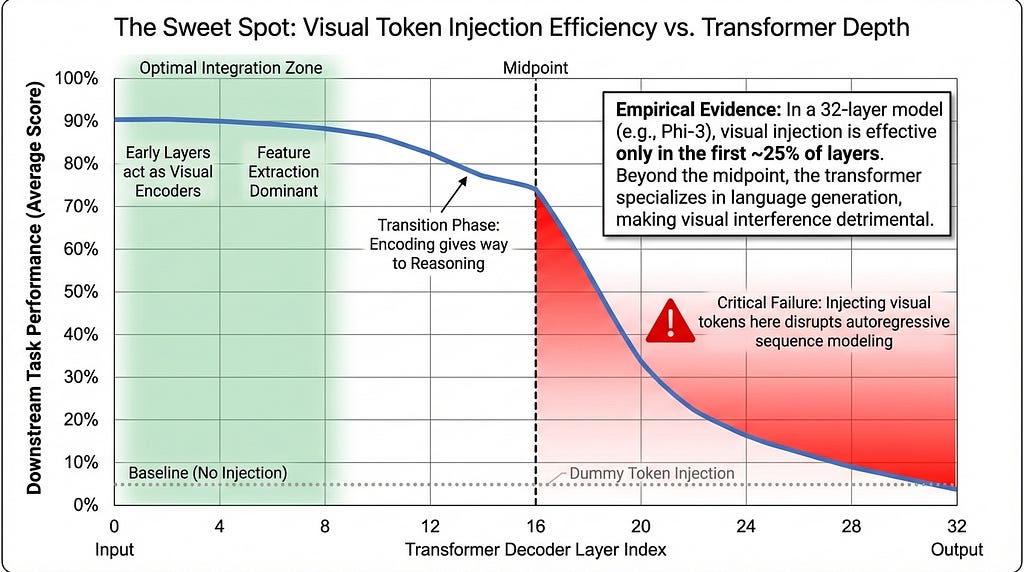
However, there are limits to this insertion. Experiments show insertion works up to the first 8 layers of a transformer. In a 32-layer model, adding tokens past the midpoint works ineffectively. Performance drops significantly if injected too deep. This confirms early layers are best for visual integration, while later layers should remain dedicated to language reasoning.
Resource constraints also matter. Engineers adjust the stacking interval for efficiency. In resource-constraint situations, they inject tokens less frequently. Qwen-VL uses this approach to balance speed and accuracy. They might stack tokens every few layers instead of every layer. This reduces compute load while keeping most benefits.

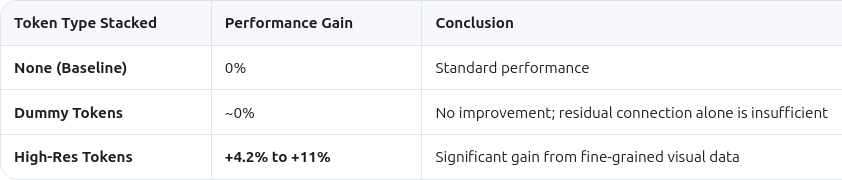
is Surprisingly Simple and Effective for LMMs
Researchers also tested dummy tokens. These are repeated original tokens stacked instead of high-resolution data. The results showed stacking dummy tokens yields no improvements. This proves the gain comes from new high-resolution information. It is not just a benefit of the residual connection structure itself.
Beyond Vision: An Architecture-Agnostic Future
One of the most powerful aspects is versatility. The DeepStack strategy can be used for any task utilizing the transformer as the foundational architecture. This makes the DeepStack architecture-agnostic. It does not change the transformer blocks. It only injects features into hidden states. For example, it can handle very long textual inputs. The strategy allows handling such long texts by injecting summary tokens into middle layers. This avoids exceeding context length limits while maintaining coherence.
The Heuristic Challenge
Despite its success, there are open questions. The author of this paper mentioned that the current insertion strategy is heuristic. This means it is based on practical experience rather than strict theory. They choose layers based on empirical testing. Whether the presented empirical evidences are enough is debated. The results are strong, showing clear performance gains on benchmarks like DocVQA. However, a theoretical framework explaining exactly why layer eight is the cutoff is still missing. Future work may find a more systematic way to decide layer selection dynamically.
In conclusion, DeepStack offers a simple yet effective solution. It bridges vision and language without high computational costs. By stacking visual tokens vertically, it preserves fine-grained details. This approach respects the internal logic of transformer layers. It keeps early layers for encoding and later layers for reasoning. As models grow larger, strategies like this will be essential. They allow machines to see the world in high definition, ensuring no detail is left unseen.
References
- DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
- Qwen3-VL Technical Report
Seeing the Unseen: How DeepStack Revolutionizes Vision Language Models was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.