Your APIs were designed for humans. That’s about to be a problem.
When Facebook’s engineering team designed GraphQL in 2012, they were solving a mobile problem: REST endpoints were returning too much data over slow networks, and iOS clients were paying the cost in latency. The solution — let the client declare exactly what it needs, enforce that contract through a typed schema, and expose everything about the API through introspection — turned out to solve a different problem entirely, one Facebook couldn’t have anticipated. Twelve years later, the most constrained consumer of your API isn’t a mobile client on a 3G network. It’s an AI agent with a finite context window.
The constraint is different, but the logic is identical. Every field your API returns that an agent doesn’t need is a wasted token. Every token is money, latency, and reasoning budget. And unlike a mobile app that fetches data once and caches it, an agent may be assembling context from dozens of sources in a single reasoning pass, then doing it again on the next turn. The economics of careless interface design compound fast.
This is why the teams building serious agentic systems are converging on GraphQL — not because it’s fashionable, but because it was already designed for the constraints that matter most when your consumer is a machine.
What REST Was Actually Designed For
REST is an architectural style built around resources and HTTP verbs. It maps cleanly to how humans think about systems: there’s a thing (a user, an order, a portfolio), and you perform operations on it. The endpoint structure is predictable, the semantics are broadly understood, and any developer who has worked with the web can read a REST API without much orientation.
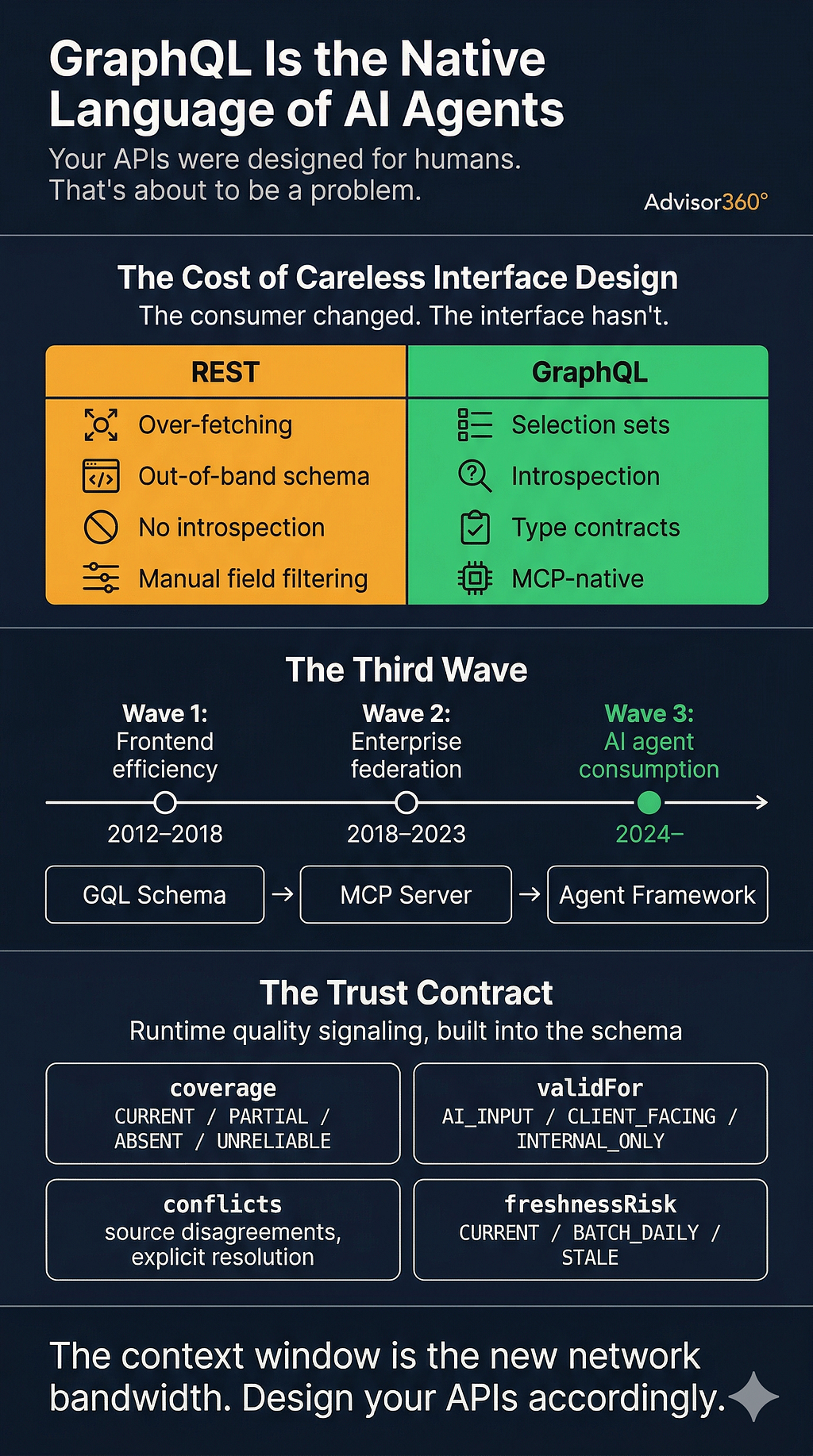
Readability is the keyword. REST was designed to be read by humans, in documentation, with plenty of time. An OpenAPI spec tells a developer what fields are available. The developer reads it, decides which fields matter, and writes code accordingly. The API returns more than is needed, the developer discards the rest, and that inefficiency is invisible because it happens once at design time.
An AI agent doesn’t operate this way. It doesn’t read documentation ahead of time and make deliberate field selections. It either receives a schema it must reason about at runtime, or it receives raw API responses it must parse and filter on the fly. In both cases, information the agent didn’t ask for and doesn’t need passes through its context window, consuming budget that could have been spent on reasoning.
More fundamentally, REST has no intrinsic mechanism for self-description at runtime. An agent calling a REST endpoint doesn’t know what other fields exist, what their types are, what relationships connect the returned resource to adjacent ones, or what constraints govern the valid values of each field. All of that lives in documentation that the agent may or may not have access to, that may or may not be current, and that has no formal connection to what the API actually returns. REST is an interface for humans with documentation. It’s a poor interface for machines that reason at runtime.
Three Things GraphQL Gets Right by Default
GraphQL’s advantages for AI consumption aren’t features that were added for this purpose. They’re structural properties of the design.
Introspection as a first-class capability. Any GraphQL schema can be queried to reveal its complete structure: every type, every field, every relationship, every argument, every description. An agent that introspects a schema before making data requests doesn’t need documentation passed through its context window. It can discover what’s available, what the types are, what constraints apply, and what related data is reachable — all from a single schema query. This is a meaningful architectural advantage. The knowledge the agent needs to reason about available data lives in the schema itself, not in a separate document that may be stale.
Selection sets as a token budget control. In a GraphQL query, the client specifies exactly which fields it wants. Not approximately, not “everything except the fields I don’t need” — exactly the fields requested, nothing more. For an AI agent that has identified the three fields relevant to a task, this means the API returns three fields. Not thirty fields that include those three. This is where the token economics become concrete: a query that returns { name, aum, lastContact } costs fundamentally less to process than a query that returns the full client object with nested holdings, account history, activity log, and contact preferences.
The type system as a reasoning contract. GraphQL’s strong typing means the agent knows what it will receive before it receives it. A field typed as Float won't return a string. A field typed as an enum returns one of a finite set of values. Relationships between types are explicit. This gives an agent a stable foundation for reasoning: when a field returns RiskProfile.CONSERVATIVE, the agent knows both the type and the valid vocabulary without having to infer it from examples or documentation. Types aren't just developer ergonomics — for a machine consumer, they're a contract that reduces ambiguity at every step.
The Third Wave
It’s worth naming where GraphQL sits historically, because the inflection point matters for how to think about investment in schema design.
The first wave of GraphQL adoption was about solving REST’s over-fetching problem — primarily for mobile and web frontends that needed efficient, flexible data access. Companies like Facebook, GitHub, and Shopify built GraphQL APIs because their product engineers needed to iterate faster than REST endpoint design allowed.
The second wave was enterprise federation: using GraphQL as a unification layer over distributed microservices. Rather than maintaining dozens of REST endpoints across teams, organizations built a unified GraphQL schema backed by multiple resolvers, giving internal consumers a coherent view of fragmented data. GraphQL Mesh and Apollo Federation became the tools for this.
The third wave is AI consumption. And it’s different from the first two because the consumer has fundamentally different needs. A frontend developer wants flexibility and fast iteration. An enterprise platform wants unified access. An AI agent wants introspection, type contracts, and structured queries — the things GraphQL was always built on, now relevant for a new reason.
The practical infrastructure change driving this is the Model Context Protocol (MCP), which has emerged as a standard interface for AI agent tool use. MCP lets an agent discover and invoke tools dynamically, without those tools being hard-coded at design time. GraphQL and MCP align almost perfectly: because GraphQL introspection already exposes every type, field, and operation in a machine-readable format, converting a GraphQL API into an MCP tool requires minimal additional work. The schema becomes the tool definition. What would require manual OpenAPI spec maintenance for a REST API is automatic for GraphQL.
The emerging production stack looks like this:
GraphQL schema → MCP server → Agent framework
(contract) (exposure) (reasoning)
Each layer has a clear responsibility. GraphQL owns the data contract and type system. MCP owns tool discovery and invocation. The agent framework handles planning, memory, and multi-step reasoning. A well-designed GraphQL schema at the base propagates quality upward through all three layers.

Schema Elements That Carry Meaning for Machines
The structural advantages above are present in any GraphQL implementation. But schema design choices can extend those advantages significantly. Several GraphQL features are underused in human-facing APIs that become genuinely powerful when the consumer is an AI.
Directives as annotation layers. GraphQL directives let you annotate fields with structured metadata that survives introspection. A custom @aiHint directive can carry information like the unit of a numeric field, whether the field is safe to aggregate across records, or a natural language note about a common misuse. This metadata travels with the schema, not with documentation. An agent that introspects the schema retrieves the hints automatically. Consider the difference between a field named weightedYield with no annotation and the same field annotated with @aiHint(unit: "percent", aggregatable: false, prompt: "Portfolio-level weighted yield. Do not sum across portfolios.") — the agent has the context it needs to use the field correctly without additional prompt engineering.
Unions for heterogeneous quality states. When a field can mean meaningfully different things depending on data availability, a single scalar with an optional note is an invitation to misinterpretation. Unions make the variance explicit in the type system. A field that can return ConfirmedValue | EstimatedValue | AbsentValue forces the agent to handle each case distinctly. An AbsentValue type can't be accidentally treated as a number. An EstimatedValue type carries a confidence range the agent can reason about. The type itself encodes what would otherwise have to be communicated through documentation or trust annotations.
Enums as policy signals. Anywhere a field carries a constrained vocabulary, an enum encodes more than just the valid values — it signals that those values have meaning the agent should treat distinctly. A ContactStatus enum with value DECEASED tells the agent something it needs to act on without requiring a trust annotation or a natural language explanation. A RiskProfile enum with value NOT_SET is a different signal from a null field: it's an explicit assertion that the profile hasn't been established, not that the data is missing. Well-designed enums give agents policy handles directly in the type system.
Field descriptions as standing instructions. Every type and field in GraphQL can carry a description string that is returned by introspection. For human readers, these are documentation. For AI agents, they function as standing instructions embedded in the schema itself. A field description that reads “Total assets custodied at Advisor360°. This figure excludes outside assets held at other custodians. Do not label this as total net worth in client-facing output” is a constraint the agent receives every time it introspects the schema. These descriptions are versioned with the schema, are always current, and require no additional prompt engineering to propagate.
The Trust Contract: A Gap the Schema Alone Can’t Fill
The features above address what the schema describes. They don’t address what the data means at runtime — specifically, whether a particular field for a particular record is reliable, complete, or appropriate for a given use.
This is a gap that field selection, type contracts, and directives can’t close by themselves. A schema can declare that lastContactDate is of type DateTime. It can't declare that for a given household, that date was inferred from CRM activity logs rather than directly recorded, and therefore carries uncertainty that should affect how an agent uses it. A union type can distinguish EstimatedValue from ConfirmedValue at the type level. It can't carry the specific reason a particular value is estimated, or signal that the estimation basis has changed since the last batch run.
For AI agent consumption, runtime data quality signaling is as important as schema design. The pattern we’ve been developing at Advisor360° to address this is what we call a trust contract: a __trust sidecar field attached to each type that carries per-field quality metadata alongside the data itself. The basic structure looks like this:
type FieldTrust {
coverage: CoverageStatus! # CURRENT | PARTIAL | ESTIMATED | ABSENT | UNRELIABLE
coverageNote: String # human-readable explanation of coverage state
validFor: [UseContext!] # AI_INPUT | CLIENT_FACING | INTERNAL_ONLY | REGULATORY
conflicts: [ConflictRecord!] # explicit conflicts with authoritative alternate values
freshnessRisk: FreshnessRisk # CURRENT | BATCH_DAILY | STALE | UNKNOWN
}extend type Activities {
__trust: ActivitiesTrust
}The validFor field is particularly important for agent behavior. It gives the resolver the ability to declare what a field is safe to be used for — not just what it contains. A field with validFor: [INTERNAL_ONLY] tells the agent it cannot use that value in client-facing output, regardless of its coverage status. A field with validFor: [] tells the agent not to use it at all. This moves trust enforcement from the agent's prompt (where it can be forgotten or reasoned around) into the schema contract itself.
The conflicts field handles a class of data quality problems that coverage status alone can't address: cases where two authoritative sources disagree. Rather than asking the agent to resolve the conflict by inference (which is where fabrication enters), the resolver surfaces the disagreement explicitly, names the sources, and where possible provides a resolution policy the agent can follow.
The __trust sidecar keeps the schema backward compatible. Existing consumers that don't request __trust fields are unaffected. AI consumers request them explicitly alongside the values they need, and receive a quality contract alongside the data.
What This Looks Like Under Failure
The argument for schema-level trust signaling becomes concrete when you trace a real failure mode.
At Advisor360°, we’ve been building AI-generated meeting agendas for wealth management advisors. These agendas draw on client data from multiple sources: CRM records, portfolio systems, activity logs. The evaluation results from early runs showed a 63% routing rate to human curators for fabrication — AI-generated content that was plausible but wrong. Two specific strata showed 100% fabrication rates: households where CRM data was sparse or absent.
The failure mechanism was simple. The generator encountered empty fields and filled them. It didn’t know the fields were empty because the data didn’t exist — it treated absence the same as missingness, and substituted plausible values. The result was meeting agendas that attributed contact history the advisor never had, referenced life events that weren’t on record, and proposed discussion topics based on invented client context.
The trust contract addresses this directly. A resolver for a CRM-sparse household returns coverage: ABSENT on CRM fields, with validFor: []. The generator's standing instruction is: if AI_INPUT is not in validFor, do not use the field. Absent data stops being an invitation to invent and becomes an explicit signal to acknowledge the gap instead. The agenda for a data-sparse household becomes shorter and more honest, rather than longer and fabricated.
The fix required no changes to the generator model and no additional prompt engineering per household. It required schema-level trust signaling that the resolver could compute and the agent could act on consistently. That’s the architectural value of the pattern: the quality contract is defined once in the schema, computed per-record in the resolver, and applied without additional configuration at the agent layer.
What’s Still an Open Problem
Schema design and trust contracts address a significant portion of the AI consumption problem. They don’t address everything.
Query cost budgeting remains underused. GraphQL allows resolvers to be annotated with cost weights, and servers can reject queries that exceed a budget. For agents that may dynamically generate queries against a schema, this is a meaningful guardrail — an agent can’t accidentally traverse a relationship graph that would return millions of fields. Libraries for query cost analysis exist but are rarely deployed. For production agentic systems, they should be considered standard.
Cache invalidation for long-lived agents is a harder problem. An agent that holds a context window representing a snapshot of client data needs to know when that snapshot is stale. GraphQL subscriptions can push freshness signals when specific fields change, allowing an agent to invalidate only the affected context rather than re-fetching everything. The pattern is architecturally clean but infrastructure-intensive. As agentic systems move from short-turn interactions to long-running processes, this becomes a first-class concern.
The field descriptions-as-instructions pattern has no enforcement mechanism. A description that says “do not use in client-facing output” is a standing instruction, not a constraint the runtime enforces. The validFor field in a trust contract is better because it's structured and can be checked programmatically. But description-level guidance still relies on the agent's instruction-following, which is probabilistic. The longer-term solution is likely structured schema annotations that the MCP tool layer can enforce at invocation time, not just at reasoning time.
The Larger Point
REST was designed for an ecosystem where the consumer is a developer who reads documentation, makes deliberate design choices, and iterates over days or weeks. That ecosystem still exists, and REST remains well-suited to it.
The emerging ecosystem of AI agents operates differently. The consumer is a reasoning system that discovers capabilities at runtime, operates under tight token budgets, and makes decisions about data under uncertainty. That consumer needs introspection, type contracts, structured field selection, and runtime quality signals. GraphQL provides the first three by design. The trust contract pattern extends the fourth.
The teams that design their data interfaces with AI consumers in mind from the start will build systems where agents behave reliably under data quality variance, rather than filling gaps with fabrication. The teams that adapt REST interfaces after agents start misbehaving will find that the failure modes are hard to diagnose and harder to fix systematically, because the quality contract was never part of the interface to begin with.
The good news is that the investment is not a fork. A GraphQL layer over existing REST services, with trust sidecars and well-annotated field descriptions, doesn’t require replacing what’s already running. It requires thinking carefully about what a machine consumer needs to behave correctly — and building that into the schema, where it stays current and propagates automatically.
The context window is the new network bandwidth. Design your APIs accordingly.
The author works on AI and data infrastructure for wealth management at Advisor360°. The fabrication failure modes and trust contract pattern described here emerged from building AI-generated advisor tools against real client data, where data quality variance is the rule rather than the exception.
GraphQL Is the Native Language of AI Agents was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.