The Pain of Iterative RAG Development
If you’ve built a production RAG system, you know this cycle. Tweak parameters, re-index, re-evaluate, repeat. It’s slow. It’s manual. The feedback loop between “I changed something” and “did it actually improve?” takes hours.
This post is about what happened when I combined the Ralph autonomous agent pattern with Arize evaluation tooling on a real project — self-rag, built at 🦞 Ralphthon Seoul #2 on March 29 — and handed everything to Claude Code.
After 8 hours of looping, here are the results:
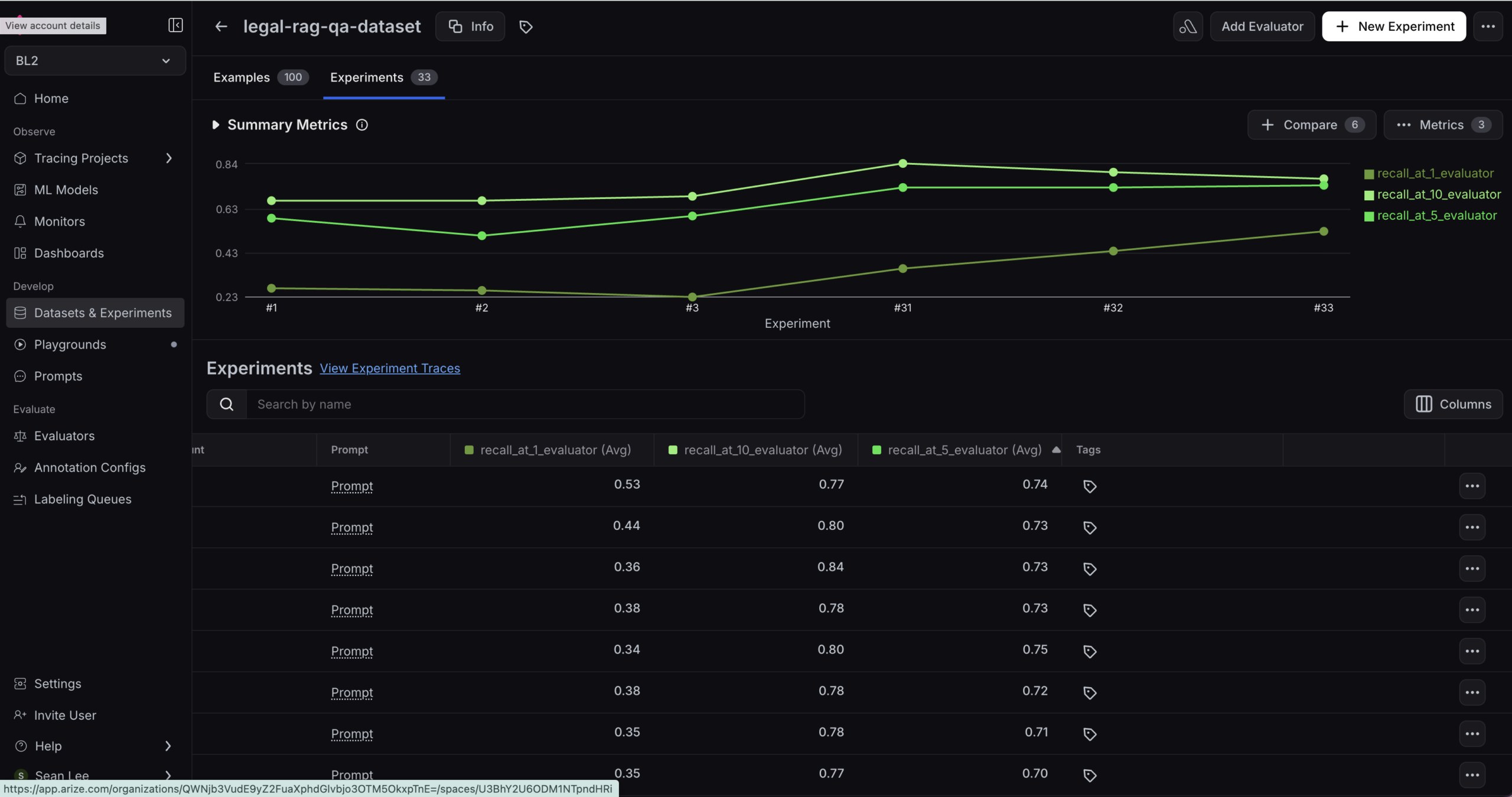
Recall@5 climbed from 39% to 75%. And when Claude Code closed the loop, it also outlined exactly how to push further. I suspect 2–3 more days of running would get us to 90%. (So I’m running it right now.)
In a RAG system, the model can only answer correctly if the right information is retrieved in the first place. If the correct document isn’t in the retrieved set, the model has no chance, no matter how good it is.
Recall measures exactly this: whether the document that actually contains the answer shows up in the results.
- Recall@1: Did the right chunk come back as the #1 result? The hardest bar to clear.
- Recall@5: Did the right chunk appear anywhere in the top 5? The most commonly used target, since most RAG pipelines pass the top 3–5 chunks to the LLM.
- Recall@10: Did it appear in the top 10? Useful for understanding how many near-misses exist just outside the retrieval window.
A Recall@5 of 39% means that in 61% of queries, the correct answer wasn’t even in the top 5 results handed to the LLM — so no matter how good the generation step is, it can’t answer correctly.
Retrieval quality is the ceiling for RAG performance. You can’t prompt-engineer your way out of bad retrieval.
Our target was achieving Recall@5 at 80% — meaning we’d accept missing at most 1 in 5 queries.
While the loop ran, Claude Code — with zero human intervention — modified the LangGraph agent code and indexing strategies based on Arize evaluation results.
The Self-Improvement Loop in CLAUDE.md
Each Ralph iteration is governed by CLAUDE.md. Three things matter: evaluate after every completed story, dynamically expand the backlog based on failure analysis, and stop only when the metric target is hit.
## Self-Improvement Loop (CRITICAL)
After marking a story as passes: true:
1. Run Arize experiment via scripts/run_experiment.py (measure recall@1, @5, @10)
2. Analyze failure patterns: which queries fail? Is it an index problem or an agent problem?
3. If Recall@5 < 80%, analyze failures and add new stories to prd.json: – Index improvements (chunking, mappings, embeddings) -> index/ directory
– Agent improvements (query expansion, reranking, scoring) -> agent/ directory
## Stop Condition
– Recall@5 > 80% AND no new stories -> output COMPLETE and stop
– Recall@5 <= 80% OR new stories added -> continue to next iteration
This design means Ralph runs autonomously until the target is met. Even if the PRD runs out of stories, it doesn’t stop — it generates new ones from eval results, growing the PRD dynamically. Each iteration follows a cycle of implement → evaluate → reflect → expand backlog → repeat.
Ralph commits every meaningful code change immediately. No batching changes into a single large commit — this ensures no work is lost between iterations.
Blue/Green Index Pattern
The trickiest part of iteratively improving a RAG system is that index changes are destructive — running index/index.py completely recreates the index. Partial re-indexing is possible via scripts/reindex.py (adds only missing passages), but when chunking strategies or mappings change, a full re-index is required.
We solved this with OpenSearch’s Blue/Green deployment pattern:
- The agent always queries through the
ralphtonalias — never hardcoded index names - When Ralph improves the indexing strategy, it creates a new versioned index (
self_ralph_v1,self_ralph_v2, …) - After running an Arize experiment on the new index via
scripts/run_experiment.py, the alias is atomically swapped only if performance improves - Previous indices are kept for immediate rollback
client.indices.update_aliases(body={
“actions”: [
{“remove”: {“index”: “*”, “alias”: “ralphton”}},
{“add”: {“index”: “self_ralph_v12”, “alias”: “ralphton”}}
]
})
By morning, Ralph had created 11 index versions. Several performed worse than the baseline and were never promoted. The alias always pointed to the best-performing version.
Architecture: Simplicity of Two Nodes Is Key
The LangGraph agent is intentionally simple. The graph itself is a StateGraph(State) with just two nodes:
- retrieve —
OpenSearchRetrieverperforms async kNN search usingtext-embedding-3-large(1024 dims) and returns top-k documents - call_model — feeds retrieved context into a RAG prompt, answered by GPT-4o-mini
State is a dataclass with messages (conversation) and docs (retrieved documents).
This simple structure was ideal for the self-improvement loop — Ralph could improve the index side (index/) and agent side (agent/) independently. Change chunking strategy? Only touch index/. Add query expansion or reranking? Only touch agent/.
Tracing is registered in src/agent/instrumentation.py via arize.otel.register + LangChainInstrumentor. This is what automatically sends traces from every experiment to Arize.
Why Arize Made the Decisive Difference
Arize Skills for Zero-Setup Evaluation
Arize recently launched Arize Skills — a set of pre-built commands that give coding agents native knowledge of Arize workflows. Install them inside Claude Code with:
claude /plugin marketplace add Arize-ai/arize-skills
claude /plugin install arize-skills@Arize-ai-arize-skills
This gives Claude Code access to experiment creation and evaluation results through skills. The latest evaluation results read via Arize Skills are reviewed by Claude Code and used to derive new improvements.
Consistent Experiments Across 17 Iterations
Because every evaluation used the same Arize experiment runner — recall_at_1, recall_at_5, recall_at_10 — results were directly comparable across all 17 experiments. No evaluation drift even as the codebase changed.
Progress was visible in real time in the Arize UI:
39% ██░░░░░░░░░░░░░ Baseline
52% ██████░░░░░░░░░ 400-char chunk re-indexing (+13pp)
56% ████████░░░░░░░ RRF/BM25 weight tuning (+4pp)
58% ████████░░░░░░░ HyDE multi-signal (+2pp)
63% ██████████░░░░░ Multi-query variants (+5pp)
75% ███████████████ 2-stage GPT-4o reranking (+12pp)
80% ████████████████ Target
Each experiment was recorded against the legal-rag-bench dataset. When we hit 75%, we could trace exactly which change drove which jump.
What Ralph Actually Discovered
More valuable than the final score were the insights accumulated in progress.txt across each iteration.
Chunk size was the #1 lever. Switching from 1000 tokens to 400 tokens yielded +13pp alone. Discovered during the 2nd loop run, it became the foundation for everything after. For legal documents, shorter clause-level chunks were far more effective.
HyDE works in two directions. Using hypothetical document embeddings as both a kNN signal (+2pp) and a BM25 query signal (+4pp) was an unexpected finding. The BM25 signal was actually stronger — likely because precise keyword matching matters for legal terminology.
Signal dilution is real. Adding more than ~6 RRF signals degraded performance. Ralph tried 10+ signals once and watched recall drop. Subsequent iterations were conservative.
Cross-encoder reranking underperformed. The ms-marco model added only +1pp with significant latency overhead. Abandoned after two experiments.
LLM reranking beat cross-encoders. A domain-specific GPT-4o-mini prompt outperformed general-purpose models by a wide margin. Since call_model already used GPT-4o-mini, reusing the same model for reranking was a natural choice.
None of this was in the original PRD. Ralph discovered it all, documented it in progress.txt, and used it to generate smarter stories for the next iteration.
Reproduce It Yourself
Prerequisites
Before starting, you’ll need:
- Arize account — sign up at arize.com (free tier available)
- Python 3.10+ and uv
- OpenSearch instance with kNN enabled
- API keys — OpenAI, Arize, and OpenSearch credentials
- Claude Code — install via
npm install -g @anthropic-ai/claude-code
Install the Arize AX CLI and Skills:
# Install and configure Arize AX CLI
pip install arize-ax-cli
ax config set –space-id –api-key
# Install Arize Skills plugin for Claude Code
claude /plugin marketplace add Arize-ai/arize-skills
claude /plugin install arize-skills@Arize-ai-arize-skills
Step 1: Clone the repo and install dependencies
git clone && cd self-rag
# Agent dependencies
cd agent && uv sync –dev && cd ..
# Index pipeline dependencies
cd index && uv sync –dev && cd ..
Configure environment variables:
cp agent/.env.example agent/.env
cp index/.env.example index/.env
# Fill in OpenAI, Arize, and OpenSearch credentials in both .env files
Step 2: Upload QA dataset and index the corpus
Inside Claude Code, use arize-skills to upload the qa split from isaacus/legal-rag-bench as an Arize dataset. You can also upload a CSV directly through the Arize UI. This dataset becomes the evaluation benchmark for the self-improvement loop.
Then index the corpus:
cd index && python index.py
Step 3: Start Ralph
Open Claude Code in your terminal and type “run ralph”:
claude
> run ralph
That’s it. Ralph starts the LangGraph agent, executes stories, runs Arize experiments, analyzes failures, adds new stories, and keeps going until Recall@5 > 80%. Go to sleep.
Key Takeaways
Metric-based stop conditions are the key to autonomy. Because Ralph’s exit condition is “Recall@5 > 80%” rather than “all stories complete,” it doesn’t stop when the PRD runs dry. It generates new stories from eval results and keeps going. One launch, autonomous until the target is met.
Dynamic PRD expansion is the core mechanism. The self-improvement loop isn’t magic — it’s eval → analyze → add to prd.json → continue. This simple addition transforms a finite task list into an adaptive improvement engine.
Arize Skills make evaluation effortless. Without consistent, zero-setup evaluation, you can’t run 17 experiments overnight. Thanks to Skills, Ralph just calls scripts/run_experiment.py without needing to figure out instrumentation or evaluation methods.
Blue/Green indexing enables fearless experimentation. With alias-based rollback, Ralph could attempt aggressive index changes. Several experiments made things worse, but nothing broke.
Monorepo structure enables independent improvements. With index/ and agent/ separated, Ralph could experiment with indexing strategies and agent logic independently. Changing one side never broke the other.
progress.txt is more valuable than code. Documented insights — what worked, what didn’t, and why — accumulated across 17 iterations and became the most important output of the overnight run.
What’s Next
5pp remain to the target. Ralph’s final analysis identified two improvement areas: ~15 queries requiring domain-specific legal embeddings, and ~10 near-misses solvable with additional reranking.
The next run will pick up exactly where this one left off — same progress.txt, same index versions, new stories targeting the specific failure patterns Ralph identified. Additive re-indexing of missing passages via scripts/reindex.py is also a strong candidate for the next iteration.
The implication of this experiment is simple:
“With ground truth, any system can be optimized.”
This is a small-scale demonstration of the “closing the loop” concept that’s been discussed since early this year. An agent that improves itself with zero human intervention — this year marks the beginning. This experiment let me experience it firsthand. The code is open-sourced, so try it with your own datasets, experiment freely, and share your results.
GitHub: https://github.com/seanlee10/self-rag
Thank you.
Sean Lee is the Director of Solutions, APJ at Arize AI. He builds and evaluates LLM systems for enterprise customers across Korea and the APAC region.
The post How Arize Skills Improved RAG Recall from 39% to 75% in 8 Hours appeared first on Arize AI.