Introduction: The Modern Crisis — Data Sovereignty.
In early to mid-2023, global technology enterprises became acutely aware of a significant threat to their privacy and data security. The source of this issue was the employees themselves; whether intentionally or accidentally, staff shared critical and confidential proprietary information unauthorized for external access with public AI models. The core problem is that this data became part of global knowledge bases, which these companies do not control, making it accessible to the public. Consequently, a pressing need emerged for new measures to prevent data leakage.
Prominent Companies Affected by This Risk:
- Samsung: A group of engineers in the semiconductor division uploaded confidential source code to ChatGPT to fix programming bugs, while another employee uploaded an internal meeting transcript to convert it into a presentation.
- Apple: Following the Samsung incident, Apple took preemptive action by restricting the use of public AI tools among employees to prevent future company ideas from leaking to competitors.
- Amazon: Amazon’s legal counsel noticed ChatGPT responses that closely resembled internal company data, suggesting that information had already leaked into public AI systems. A stern warning was issued to employees regarding the risks of inputting private company information into such models.
These organizations did not want to abandon AI, as it is the most productive tool in the current digital age. Therefore, alternative solutions were necessary to ensure data remains protected and restricted within the enterprise’s private scope, maintaining confidentiality without sacrificing AI capabilities.
In light of this crisis, cybersecurity reports indicate that entering Prompts into these models has significantly led to data leakage outside organizational boundaries. As a result, 72% of companies have decided to shift toward developing private Large Language Models (LLMs) to escape the risks associated with public AI.
In this article, we provide a comprehensive guide to the concept of Private AI. We will cover everything from understanding local RAG (Retrieval-Augmented Generation) architecture and data isolation to reviewing the tools and protocols that enable enterprises to build a super-intelligent AI with full sovereignty and absolute security, alongside a precise analysis of the economic and technical feasibility of these systems.
You can also watch the video about this topic:
Part I: The Technical Engine — How Does RAG Work?
The acronym RAG stands for (Retrieval-Augmented Generation). It is the core technology used in building private AI systems that enterprises rely on. This technique is distinguished by its ability to enhance AI capabilities by accessing your private data, which you authorize, instead of relying solely on the data the model was originally trained on. It acts as a bridge connecting the model’s general intelligence with the enterprise’s private database. RAG provides the ability to read specific documents in Real-time before generating a response; this means you place the information directly in front of the AI model to read and formulate the correct answer without needing to store that information in its long-term memory. This approach ensures that private data remains within defined security boundaries, preventing unauthorized external access while significantly reducing the costs of fine-tuning or retraining AI models.
Workflow: From Input to Final Response
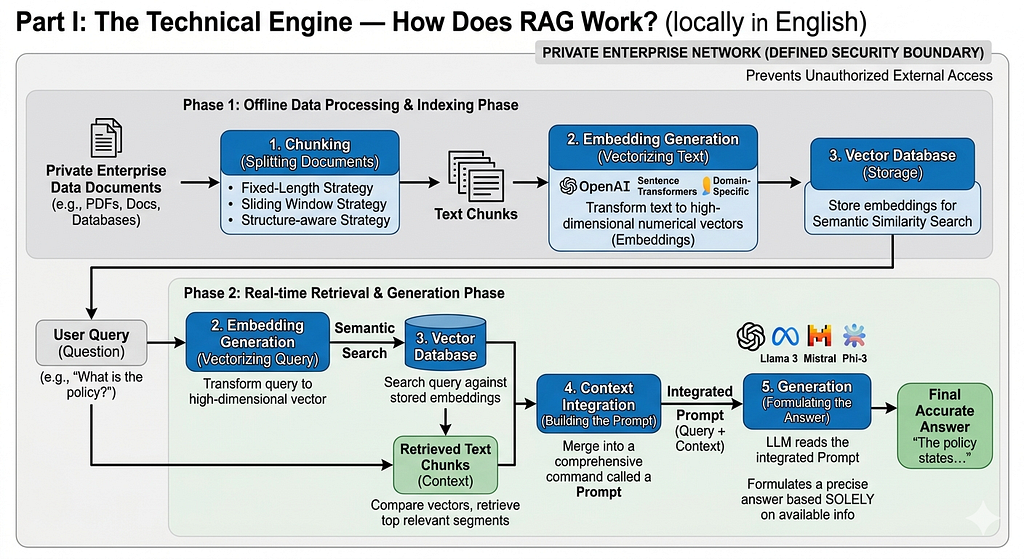
Information processing in RAG systems follows a precise technical pipeline to ensure response accuracy. This mechanism can be summarized in the following stages:
1. Chunking:
In this stage, documents are split into smaller, manageable segments called “Chunks.” This is executed via three key strategies:
- Fixed-Length Strategy: Where text is divided into equal blocks of a predetermined length.
- Sliding Window Strategy: Similar to the first strategy in defining chunk size, but with an added Overlap percentage. This overlap ensures that the end of one chunk is repeated at the beginning of the next. The benefit of this method is maintaining contextual continuity and more accurate tracking of where sentences break.
- Structure-aware Strategy: This strategy relies on structural markers like commas, periods, and sections; text is only split when reaching the end of a paragraph or the start of a new heading.
2. Embedding Generation:
At this stage, the user’s query is transformed from linguistic text into a numerical Vector that the computer understands. This is a machine learning model that maps text into a High-Dimensional Space where meanings are mathematically represented. This stage can be thought of as the “Translation” phase.
- Vector: Computers only understand the language of numbers; a vector is a sequence of numbers where each number represents a specific feature used by the model to distinguish the word.
- High-Dimensional Space: This involves two distinct states:
- Similar Meanings: Words with related meanings (e.g., “Doctor”, “Hospital”) will have vectors that are very close to each other in this space.
- Dissimilar Meanings: Words with different meanings (e.g., “Football”, “Television”) will have vectors located far apart.
3. Vector Database:
Briefly, this is the storage for embeddings that allows for high-speed Semantic Search. Semantic search provides results that match the intent and meaning of your query rather than just keyword matching.
4. Context Integration:
The original question is merged with the retrieved text segments (Context) into one comprehensive command called a Prompt.
5. Generation:
The Large Language Model (LLM) reads this integrated Prompt and formulates a precise answer based solely on the available information, matching your search intent without Hallucination or guessing.
Prominent Embedding Models:
- OpenAI Embeddings: Powerful online models trained on nearly all general topics and fields, making them versatile and widely accessible.
- Sentence Transformers (e.g., all-MiniLM-L6-V2): Open-source models characterized by being lightweight; they can run locally on your machine without an internet connection.
- Domain-Specific Models: AI models trained on specialized fields (such as Medicine) to be experts in those specific areas, targeting a niche group of professionals.
Part II: Air-Gapped Architecture — The Digital Fortress
Air-Gapped Architecture refers to running all operations within an organization’s internal network without the need to connect to external servers during operation; everything occurs entirely within the local intranet. This process is classified as an enterprise-grade protocol known as the “Zero External Calls” protocol. The closest analogy to this concept is a calculator; almost every device includes this software, which performs all arithmetic operations without needing an internet connection. The importance of this architecture lies in preventing external breaches and unauthorized access by any third party — whether individuals or corporations — to sensitive and critical data related to the organization’s future, existence, or reputation. This achieves the concept of “Digital Sovereignty,” meaning you hold absolute authority over internal data, and no one else can access it under any circumstances.
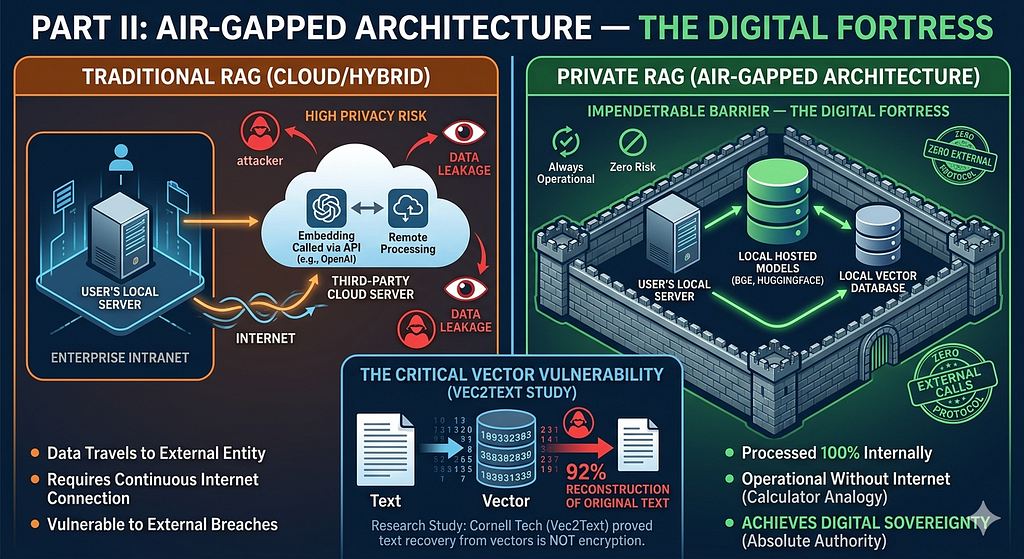
Comparison: Traditional RAG (Cloud/Hybrid) vs. Private RAG (Air-Gapped)
Data Path
- Traditional RAG: Data travels over the internet to a third-party server, meaning it reaches an external entity before processing.
- Private RAG (Air-Gapped): Data travels through the enterprise’s local server and is processed entirely internally with no external leaks.
Embedding Model
- Traditional RAG: Called via API from external providers like OpenAI.
- Private RAG (Air-Gapped): Hosted locally using models such as BGE or HuggingFace.
Privacy Risks
- Traditional RAG: High — due to data leakage to third parties.
- Private RAG (Air-Gapped): Zero Risk.
Dependency
- Traditional RAG: Requires a continuous internet connection.
- Private RAG (Air-Gapped): Always operational without the need for internet connectivity.
The Critical Need for This Architecture
The major vulnerability lies in the Vectors themselves. Since a vector is a numerical sequence representing a map of the original text, if the Vector Database is somehow compromised, more than 90% of the original text can be reconstructed. Therefore, the Air-Gapped architecture acts as an impenetrable barrier between external parties and the sensitive data within the Vector Database. This closes the largest and most dangerous loophole in the field, allowing us to focus on verifying data integrity and protecting it from manipulation or lower-risk vulnerabilities.
Research Study: “Contrary to the common belief that converting text into numbers (Vectors) acts as a form of encryption, a study from Cornell Tech (titled Vec2Text) proved that attackers can recover 92% of the original text with extreme precision. This makes protecting vector databases just as critical as protecting raw text.”
Part III: RAG Security Risks — Vulnerabilities Beyond the Air-Gap
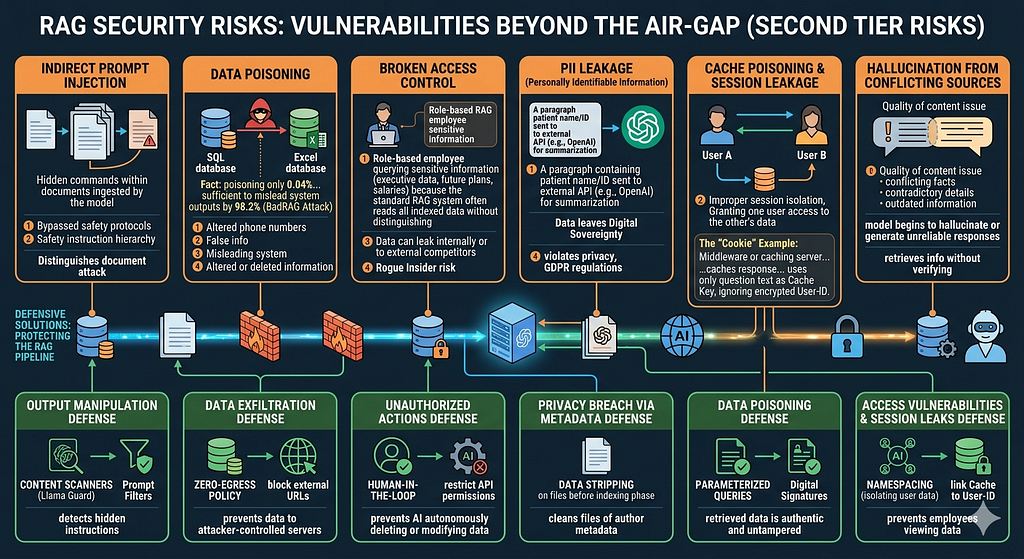
These vulnerabilities represent the second tier of risk, following the critical importance of securing the private architecture from external access as previously discussed. Below are the key security risks that must be carefully considered:
1. Prompt Injection (Indirect):
This refers to the documents or files ingested by the model. The risk lies in adding hidden commands or texts within these files, specifically targeting the AI assistant or the LLM. These commands instruct the model to ignore certain safety protocols and execute malicious instructions, leading to data breaches or output manipulation. The distinction here is that the “attack” does not come from the user, but from the documents themselves.
2. Data Poisoning:
This involves attacking the data source itself, such as SQL databases, Excel sheets, or other repositories. Since RAG systems rely on retrieved data, this data can be manipulated to include misleading instructions, false information, or Prompt Injections that cause the system to alter or delete information during the retrieval phase. This vulnerability is typically implemented via SQL Injection or Path Traversal.
Fact: “The BadRAG attack demonstrated that poisoning only 0.04% of documents is sufficient to mislead system outputs by 98.2%. An attacker simply changes a phone number or a recovery policy, and the system presents it as a confirmed fact because it trusts the ‘poisoned’ source.”
3. Broken Access Control:
Unlike the previous types, this is a permission-level issue. A standard RAG system often reads all indexed data without distinguishing between user roles. If an unauthorized employee queries sensitive information (e.g., executive personal data, future strategic plans, or salaries), the system may provide it. Without strict internal measures, data can leak within the organization itself, or worse, be sold to external competitors by a rogue insider.
4. PII Leakage (Personally Identifiable Information):
When a paragraph containing a patient’s name or ID number is sent to an external API (like OpenAI) for summarization, your data has officially left your Digital Sovereignty. This violates corporate privacy policies and may put the organization in direct conflict with GDPR regulations.
5. Cache Poisoning & Session Leakage:
Systems use Caching to store data temporarily for faster response times. The danger arises if these sessions are not properly isolated. For instance, if User A queries sensitive personal info, and User B asks a similar question simultaneously, a conflict might occur, granting one user access to the other’s data.
- The “Cookie” Example: The problem often lies in the Middleware or caching server (e.g., Cloudflare). When the system caches an AI response to speed up future queries, it might use only the question text as the Cache Key, ignoring the encrypted User-ID. This leads to a Session Leak, where User B receives a cached answer intended for User A containing sensitive financial or personal data simply because their questions were similar.
6. Hallucination from Conflicting Sources:
Even if your data is protected from external attacks, content quality remains vital. If indexed documents contain outdated facts or contradictory details, the model may begin to Hallucinate or generate unreliable responses because it does not inherently verify the factual truth of what it retrieves.
Summary:
The security flaw in RAG lies in “Blind Trust.” The system assumes that any text retrieved from the database is safe, correct, and authorized for the user to see, whereas it may actually be “mined” with Injections, corrupted by Poisoning, or restricted by Access Control.
Defensive Solutions for These Vulnerabilities
Output Manipulation (Indirect Injection)
- Brief Mitigation Mechanism: Use Content Scanners (e.g., Llama Guard) and prompt filters before context integration.
- Technical Goal: Detect hidden instructions within documents and prevent execution.
Data Exfiltration (Egress)
- Brief Mitigation Mechanism: Implement a Zero-Egress policy and prevent the model from requesting external URLs.
- Technical Goal: Prevent sensitive data from being sent to attacker-controlled servers.
Unauthorized Actions
- Brief Mitigation Mechanism: Adopt the Human-in-the-Loop principle and restrict API permissions.
- Technical Goal: Prevent AI from autonomously deleting or modifying data.
Privacy Breach via Metadata
- Brief Mitigation Mechanism: Perform comprehensive Data Stripping on files before the indexing phase.
- Technical Goal: Clean files of author metadata and internal file paths.
Data Poisoning
- Brief Mitigation Mechanism: Verify sources via Parameterized Queries and digital signatures for files.
- Technical Goal: Ensure retrieved data is authentic and untampered.
Access Vulnerabilities & Session Leaks
- Brief Mitigation Mechanism: Enable Namespacing to isolate user data and link the Cache to User-ID.
- Technical Goal: Prevent employees from viewing data they are not authorized to access.
Part IV: Developer’s Selection Guide — Tools & Infrastructure
When selecting a technical stack for Private AI, the primary priorities are self-hosting capabilities, reasonable resource consumption, and support for strict enterprise protocols.
1. Embedding Models
These must be run locally to ensure that data does not leak during vector generation. The following table compares prominent Open-Source models based on resource efficiency and the MTEB (Massive Text Embedding Benchmark) score:
BGE-M3 (BAAI)
- Parameters: 567M
- MTEB Score: Superior
- VRAM Required: ~2.5 GB
- Key Recommendation / Feature: The Balanced Choice: Supports large context lengths, multi-lingual (excellent for Arabic), and combines semantic search with keyword matching.
Nomic-Embed-Text
- Parameters: 137M
- MTEB Score: Excellent (EN)
- VRAM Required: < 1 GB
- Key Recommendation / Feature: The Lightweight Choice: Ideal for servers with very limited resources or edge devices.
mxbai-embed-large
- Parameters: 335M
- MTEB Score: Excellent
- VRAM Required: ~1.5 GB
- Key Recommendation / Feature: Large Vector Performance: A robust and stable option primarily for English-language data.
2. Vector Databases
The comparison here focuses on core security features: Encryption-in-Transit (TLS), Role-Based Access Control (RBAC), and data isolation capabilities.
Qdrant
- Encryption (TLS): Native Support
- Access Control (RBAC/RLS): Highly Advanced (Native RBAC)
- Data Isolation (Multi-tenancy): Strong isolation via Collections
- Optimal Use Case: For Rust-based projects requiring extreme performance and ultra-low Latency.
pgvector
- Encryption (TLS): Supported (via PostgreSQL)
- Access Control (RBAC/RLS): Robust Support (via SQL Roles & RLS)
- Data Isolation (Multi-tenancy): Excellent isolation via Tables/Schemas
- Optimal Use Case: For enterprises with existing PostgreSQL infrastructure looking to minimize system complexity.
Milvus
- Encryption (TLS): Supported
- Access Control (RBAC/RLS): Advanced (Enterprise-grade RBAC)
- Data Isolation (Multi-tenancy): Comprehensive Database/Collection level isolation
- Optimal Use Case: For massive organizations managing billions of vectors requiring a Distributed Architecture.
Technical Insight: The Strategic Choice
If your organization seeks rigorous security without adding new infrastructure complexities, pgvector offers a unique advantage: RLS (Row-Level Security). This means you can programmatically prevent a user from retrieving a specific “Vector” within the same table if they lack the required permissions. This is the strongest line of defense against “Session Leakage” and access vulnerabilities. Conversely, Qdrant remains the premier choice if you are building a high-performance, independent RAG engine from the ground up.
Part V: Business Case — Economic Feasibility & Compliance
Private AI models provide a strategic solution to the financial burden of cloud-based models while shielding organizations from the legal liabilities associated with data breaches.
1. Economic Feasibility
- Cloud-based RAG Systems: These rely on a Pay-per-Token pricing model. Since RAG requires attaching large text contexts to every user query, token consumption and subsequently costs escalate exponentially at scale.
- Private RAG Systems: Leveraging local Large Language Models such as Llama 3 or Mistral can reduce operational costs by up to 10x compared to relying on cloud APIs like GPT-5.
2. Regulatory Compliance
Compliance with stringent data protection regulations such as GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act) is the primary obstacle for enterprises using cloud AI. Private AI resolves this “By Design” through the following:
- Data Residency: These regulations mandate that user or patient data (PHI/PII) must not be transferred outside specific geographical boundaries or unsecure networks. An Air-Gapped architecture ensures that 100% of the data remains within the enterprise’s internal servers.
- Right to be Forgotten: Users of public models face immense difficulty ensuring their data is deleted if it has been ingested into a cloud provider’s training set. In Private AI, the process is as simple as deleting the user’s specific Vector from the local database (e.g., pgvector), effectively erasing their footprint from the system in seconds.
- Auditability: Local systems allow cybersecurity teams to inspect and monitor every Query and retrieval operation occurring within the network. This simplifies the generation of compliance reports required by regulatory bodies.
Part VI: Implementation Roadmap
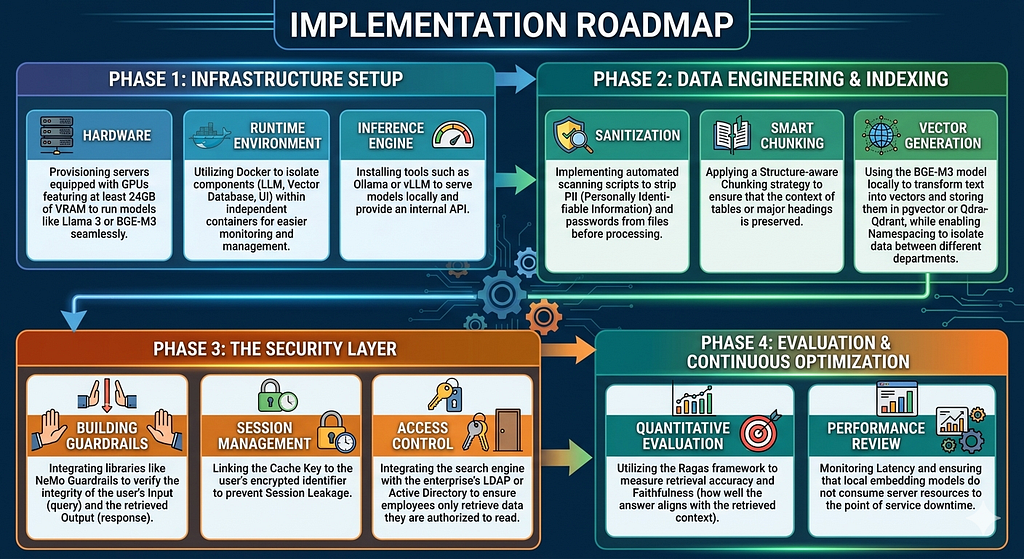
Phase 1: Infrastructure Setup
The process begins with selecting the hardware and an isolated environment to ensure zero external connectivity:
- Hardware: Provisioning servers equipped with GPUs featuring at least 24GB of VRAM to run models like Llama 3 or BGE-M3 seamlessly.
- Runtime Environment: Utilizing Docker to isolate components (LLM, Vector Database, UI) within independent containers for easier monitoring and management.
- Inference Engine: Installing tools such as Ollama or vLLM to serve models locally and provide an internal API.
Phase 2: Data Engineering & Indexing
In this stage, raw documents are transformed into searchable “mathematical knowledge”:
- Sanitization: Implementing automated scanning scripts to strip PII (Personally Identifiable Information) and passwords from files before processing.
- Smart Chunking: Applying a Structure-aware Chunking strategy to ensure that the context of tables or major headings is preserved.
- Vector Generation: Using the BGE-M3 model locally to transform text into vectors and storing them in pgvector or Qdrant, while enabling Namespacing to isolate data between different departments.
Phase 3: The Security Layer
This is the most critical phase for preventing the vulnerabilities discussed earlier:
- Building Guardrails: Integrating libraries like NeMo Guardrails to verify the integrity of the user’s Input (query) and the retrieved Output (response).
- Session Management: Linking the Cache Key to the user’s encrypted identifier to prevent Session Leakage.
- Access Control: Integrating the search engine with the enterprise’s LDAP or Active Directory to ensure employees only retrieve data they are authorized to read.
Phase 4: Evaluation & Continuous Optimization
The system is not “complete” upon launch; it requires precise tuning:
- Quantitative Evaluation: Utilizing the Ragas framework to measure retrieval accuracy and Faithfulness (how well the answer aligns with the retrieved context).
- Performance Review: Monitoring Latency and ensuring that local embedding models do not consume server resources to the point of service downtime.
Conclusion:
Ultimately, RAG technology is a “double-edged sword.” While it grants your model a powerful institutional memory, it also opens backdoors to threats like BadRAG and Vec2Text. Shifting toward Private AI and Air-Gapped architecture is not merely a security measure; it is a strategic investment that reduces costs by 10x and ensures native compliance with GDPR and HIPAA. Always remember: the true power of AI lies in the information you own and know how to protect, not in what you send through external APIs.
Don’t leave before sharing your experience! Engaging in discussion helps spread ideas and diverse perspectives.
- Have you ever attempted to build a Private AI system?
- How was the experience?
- What strategies did you implement to ensure a secure deployment?
Follow me for more in-depth articles where I share my effort and time to provide you with the most valuable technical insights.
Resources
- Private RAG Deployment: Building Zero-Leakage Retrieval Pipelines for Enterprise
- What is RAG, and how to secure it | Snyk
- How to Build AI Agent on On-Prem Data with RAG & Private LLM
- استكشاف قضايا الخصوصية في عصر الذكاء الاصطناعي | IBM
Private AI: Enterprise Data in the RAG Era was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.