Google’s TurboQuant shrinks AI’s working memory by up to 10x
A new compression algorithm from Google Research shrinks AI’s working memory by up to 10x — with near-zero accuracy loss. Here is how it works, and why it matters.
Every time you have a long conversation with an AI, ask it to summarize a document, or run a complex semantic search, the model is quietly filling up a working memory called the key-value cache. It is the model’s fast-access notepad — storing what it has already processed so it does not have to recompute everything from scratch with each new word. And at scale, it is enormously expensive.
The reason comes down to what is actually being stored. For every single token the model processes — every word, every punctuation mark — it stores two high-dimensional vectors: a key and a value. Each of those vectors contains thousands of numbers. And this happens independently across every layer of the network.
The numbers add up fast. For a typical large language model processing a 100,000-token document:
100,000 tokens × 4,096 dimensions × 2 (keys + values) × 32 layers × 2 bytes ≈ ~54 GB of memory for a single document
That is not a rounding error — it is the dominant memory cost in modern AI inference. It constrains how long a context window a model can support, how many users can be served simultaneously from a given hardware budget, and how fast a model can respond under load.
In March 2026, researchers at Google published a suite of algorithms — TurboQuant, PolarQuant, and QJL — that compress each of those numbers from 32 bits down to just 3 or 4, reducing that 84 GB to roughly 8 to 10 GB, while maintaining near-identical model accuracy across every benchmark tested.
This piece explains how the approach works, from first principles, without assuming a background in machine learning.
What quantization means — and where it usually breaks down
A 32-bit floating-point number can represent approximately 4.3 billion distinct values. A 3-bit number can represent exactly 8. Quantization is the process of mapping from the larger set to the smaller one — rounding a precise decimal to the nearest value in a much coarser grid. You save memory; you introduce rounding error. The challenge is controlling that error well enough that the model’s outputs are not meaningfully degraded.
Most aggressive quantization methods — those targeting fewer than 4 bits — have historically caused measurable major accuracy loss. The reason is not just the coarseness of the grid. It is an overlooked secondary cost.
The overhead problem
When you compress a block of numbers, you need to store metadata describing how they were compressed — the scale, the offset, the range — so the values can be decoded correctly later. These correction constants typically consume 1 to 2 additional bits per number.
At a 3-bit compression target, that overhead is not incidental. It means the model is effectively storing 4 to 5 bits of data while only recovering 3 bits of actual information. The savings are largely undone before they begin.
TurboQuant eliminates this overhead entirely. The two algorithms that make this possible — PolarQuant and QJL — each attack the problem from a different angle.
PolarQuant: a different geometry for the same data
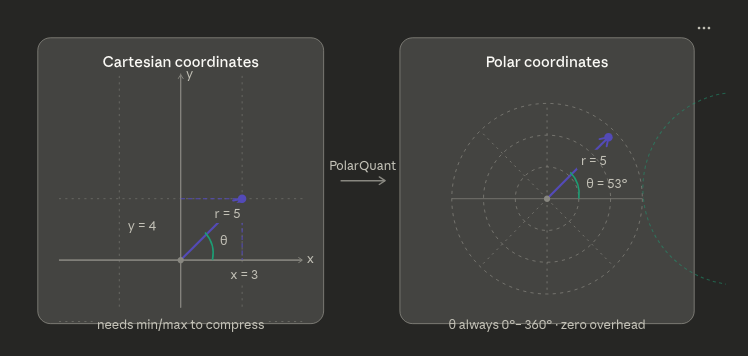
Each vector in the key-value cache is, geometrically speaking, a point in high-dimensional space. The conventional way to describe such a point is with Cartesian coordinates: one number per axis, each potentially ranging across an unbounded scale. To compress these numbers, you must first characterize their range — and storing that characterization is exactly the overhead described above.
PolarQuant replaces Cartesian coordinates with polar coordinates. The key insight is simple: angles are bounded by definition.
PolarQuant applies this conversion systematically to high-dimensional vectors. It groups coordinates into pairs and converts each pair into a radius and an angle using standard trigonometry. It then takes the resulting radii and converts those into a radius and angle — recursively — until the entire original vector is expressed as a single final radius and a collection of angles.
The angles, occupying a fixed and known range, are quantized with zero overhead. The final radius — capturing the overall magnitude of the vector — receives the majority of the allocated bits. The result is a compact representation that wastes none of its bit budget on metadata, recovering the 1 to 2 bits per number that traditional methods surrender to overhead and putting them to work on actual information content.
Random rotation: preparing vectors for efficient compression
Before any compression takes place, TurboQuant applies a random rotation to each vector. This step is mathematically straightforward but practically important.
Real-world AI vectors are frequently lopsided. Their energy — the meaningful variation in their values — tends to concentrate in a small number of dimensions, while the remaining dimensions carry values close to zero. Compressing such a vector is inefficient: a disproportionate share of bits gets spent encoding near-zero dimensions, while the information-dense dimensions are rounded too coarsely.
A random rotation redistributes that energy uniformly across all dimensions. Every dimension becomes equally significant, and compression becomes uniformly efficient across the entire vector. Crucially, a rotation preserves the vector’s length and all pairwise relationships — it changes how the data is described, not what it encodes.
Why you never need to reverse the rotation
The model is not trying to recover the original vector. It is trying to compute a dot product — a numerical measure of similarity between a query vector and a key vector, which is how attention scores are calculated.
Rotations preserve dot products exactly: if you apply the same rotation to both the query and the key, their dot product is unchanged. In practice, the query is rotated on the fly at inference time, and the dot product is computed directly in the rotated space. The original unrotated vector is never reconstructed. The rotation is a permanent, lossless preprocessing step.
QJL: one bit to eliminate systematic error
PolarQuant captures the vast majority of each vector’s information content, but no compression is perfectly lossless. A small residual error remains after the polar transformation and quantization. Left unaddressed, that residual can introduce bias — a systematic drift in the model’s attention scores that compounds across layers and degrades output quality over time.
Random errors are relatively harmless in this context: they tend to cancel out across the billions of computations a model performs. Biased errors do not cancel — they accumulate, and their effect grows with context length. This is the failure mode that makes aggressive quantization dangerous in practice.
QJL — Quantized Johnson-Lindenstrauss — addresses this with a single additional bit. It examines the residual error from PolarQuant and records only its sign: positive or negative. That single bit is sufficient to produce an unbiased estimator of the true dot product, a guarantee that follows from the Johnson-Lindenstrauss lemma — a classical result in mathematics showing that random projections preserve inner products and distances with high probability.
The overhead is exactly one bit per vector. The guarantee is that the compression pipeline, taken as a whole, introduces no systematic error — only random noise that dissipates across computations.
The full algorithm
Step 1 — Random rotation Each input vector is multiplied by a randomly generated rotation matrix, redistributing its energy uniformly across all dimensions. The same rotation is applied to query vectors at inference time, preserving dot products exactly. The original vector is never reconstructed.
Step 2 — PolarQuant Coordinate pairs are recursively converted to polar form. Angles are quantized with zero metadata overhead, since their range is fixed by definition. The single final radius receives the majority of the allocated bits. Combined cost: the bulk of the 3–4 bit target.
Step 3 — QJL residual correction The residual error from PolarQuant is encoded as a single sign bit using the Johnson-Lindenstrauss framework. This eliminates bias in the dot product estimate, ensuring errors remain random and self-cancelling rather than systematic and cumulative. Cost: exactly 1 bit.
The output is a compressed vector at 3 to 4 bits total, with zero metadata overhead, zero model retraining required, and a mathematical guarantee of unbiased dot product estimation.
Empirical results
The Google Research team evaluated TurboQuant across a comprehensive suite of long-context benchmarks — LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval — using open-source models including Llama 3.1, Gemma, and Mistral. Results were consistent across task types spanning question answering, code generation, and document summarization.
Metric Result Memory reduction vs. 32-bit ~10× Attention speedup on H100 GPUs (4-bit) 8× Minimum KV cache reduction 6× Accuracy loss on long-context benchmarks ~0
At 3-bit compression, TurboQuant matched full 32-bit precision on needle-in-a-haystack retrieval tasks — tests specifically designed to detect accuracy degradation in long-context settings. In vector search evaluations, it outperformed state-of-the-art baselines including PQ and RaBitQ on recall ratio, despite those methods using larger codebooks and dataset-specific tuning.
The speed improvement is worth emphasizing separately. Compression typically trades memory for computational cost. TurboQuant achieves the opposite: because quantized arithmetic is dramatically cheaper for modern GPU hardware to execute, the compressed model is both smaller in memory and faster at inference. These gains compound — you fit more context into memory, and you process that context faster.
Why this matters in production
The key-value cache bottleneck is not an abstract research concern. It is one of the primary constraints shaping how AI systems are deployed today. The size of the cache directly limits how long a context window a model can support in production, how many concurrent users can be served from a given hardware budget, and how responsive the system feels under real-world load.
Reducing that cache from 84 GB to 8 GB for a long document is not merely a cost saving. It is the difference between a system that can hold an entire research paper, a lengthy codebase, or a complex conversation in memory — and one that cannot.
“TurboQuant operates near the theoretical lower bound of what is achievable for this class of compression. This is not a practical heuristic — it is a provably optimal algorithm backed by formal mathematical guarantees.”
What distinguishes TurboQuant from prior engineering solutions is the theoretical foundation. The authors provide formal proofs that the algorithm operates near the theoretical lower bound for this class of compression problem — meaning no method working with the same bit budget can do meaningfully better. That kind of rigorous grounding makes TurboQuant not just a useful tool, but a durable contribution to the field.
Google’s TurboQuant Is Quietly Rewriting the Rules of AI Memory was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.