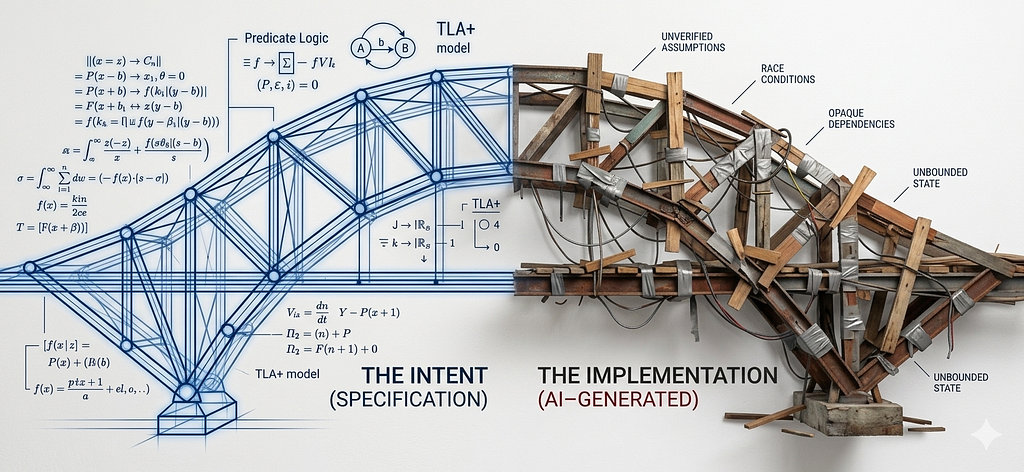
A framework for figuring out when AI-generated code can be formally verified — and when you’re kidding yourself.
I’ve been thinking about a problem that’s been bugging me for a while. We’re all using AI to write code now. Copilot, Claude, ChatGPT, internal tools — whatever your flavor. And the code is… surprisingly good? It passes tests, it looks reasonable, it usually does what you asked for.
But “usually” is doing a lot of heavy lifting in that sentence.
Here’s the thing nobody talks about at the stand-up: testing can show you bugs exist. It cannot prove they don’t. That’s not a philosophical position. It’s a mathematical fact, courtesy of Dijkstra, circa 1972. And it matters a lot more now that we’re generating code at a pace where human review is becoming a bottleneck rather than a safety net.
So I started asking a different question. Not “is this code correct?” but something more fundamental:
Can we even know if this code is correct? And if so, how hard is it to find out?
That question led to a framework I’ve been developing — a way to classify any AI-generated artifact by how amenable it is to formal verification. Not testing. Not code review. Mathematical proof. I’m wrapping up an academic paper on this with machine-checked proofs of the core claims, and I plan to publish it soon. But the ideas are too useful to keep locked in a PDF, so here’s the practitioner’s version. Let me walk you through it.
The Five Things That Determine Whether You Can Prove Your Code Works
After a lot of analysis (and quite a bit of theorem proving), I identified five independent structural properties that determine verification tractability. Think of them as dials. Each one, independently, makes the proof harder or easier.
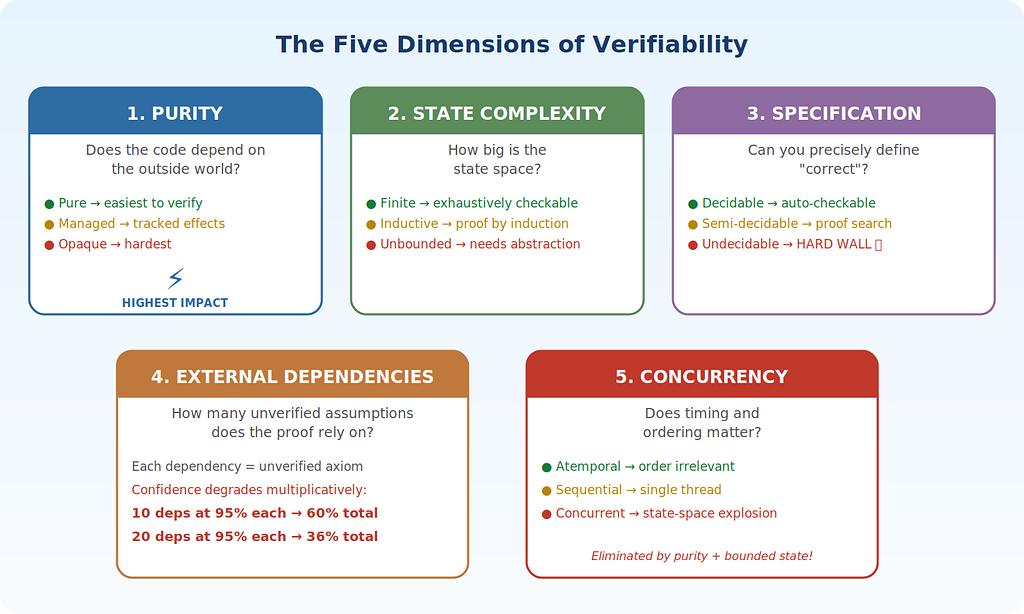
1. Purity — Does your code talk to the outside world?
A pure function takes inputs, produces outputs, done. No database calls, no API hits, no checking the clock, no random numbers. Give it the same inputs, you get the same outputs, every single time.
This is the single biggest factor. If your AI-generated function is pure, proving it correct is dramatically easier because the proof doesn’t need to account for every possible state of the universe. It just needs to reason about inputs and outputs.
The moment your code reads from a database or calls an external service, you’ve introduced the entire state of that external system into your verification problem. The proof now has to say “this works regardless of what the database returns,” which is a much, much harder claim.
Practical takeaway: If you’re configuring AI to generate code for critical paths, push it toward pure functions wherever possible. This isn’t just good software engineering — it’s the single most impactful thing you can do for verifiability.
2. State Complexity — How big is the state space?
A function that validates a credit card number using the Luhn algorithm has a tiny, well-defined state space. A real-time order book has a state space that grows with every order, every cancellation, every partial fill.
There are three flavors here:
- Finite — you can literally enumerate all possible states. Verification tools can exhaustively check all of them.
- Inductive — infinite states, but structurally regular. Think linked lists, trees, recursive data structures. You can prove things about all of them using induction (“if it works for a list of length n, it works for length n+1”).
- Unbounded — dynamically growing, irregular, no structural pattern to exploit. This is where proof gets really hard.
3. Specification Clarity — Can you even say what “correct” means?
This one catches people off guard.
Before you can prove code is correct, you need a precise definition of “correct.” Not a user story. Not a Jira ticket. A mathematical statement.
For some problems, this is easy: “the output list must be sorted and contain exactly the same elements as the input list.” That’s crisp. You can write a theorem about it.
For others? “The recommendation engine should surface relevant products.” Good luck writing a theorem about that.
There are actually three levels:
- Decidable — a machine can check it automatically, no human needed.
- Semi-decidable — a proof might be found, but you’re not guaranteed one. This is where interactive theorem provers live — they’ll find a proof if one exists within the search space, but they might search indefinitely.
- Undecidable — mathematically impossible to decide for all cases. Full stop. This is a hard wall. No amount of money, compute, or genius overcomes it. This isn’t a conjecture — it’s a proven consequence of Gödel’s Incompleteness Theorems, Turing’s resolution of the Entscheidungsproblem, and Church’s work on the lambda calculus, all from the 1930s. These results established that certain classes of questions about programs are inherently unanswerable by any algorithm. That fact is not going away.
Recognizing undecidability early saves you from pouring resources into a hole with no bottom.
4. External Dependencies — How many things are you trusting without proof?
Every external system your code calls — every API, every database, every third-party library — enters your verification as an unverified assumption. “We assume the payment gateway returns accurate status codes.” “We assume the market data feed delivers prices within 50ms.”
These assumptions might be true. They might not. The point is: your proof is only as strong as your weakest assumption.
And here’s the kicker: the confidence degrades multiplicatively, not additively. If each of 10 assumptions has a 95% chance of being correct, your overall confidence isn’t 50% (10 × 5% risk). It’s 0.9⁵¹⁰ ≈ 60%. With 20 assumptions at 95% each, you’re at 36%.
That math should make anyone with a lot of microservices a little nervous.
5. Concurrency — Does timing matter?
Code that processes one thing at a time: manageable. Code where multiple threads are reading and writing shared state simultaneously: nightmare.
The number of possible execution orderings (interleavings) grows combinatorially with the number of concurrent threads — this is the classic state-space explosion problem. For n threads of m steps each, the number of interleavings is on the order of (nm)! / (m!)ⁿ. Concretely, a system with 3 threads of 10 steps each has on the order of billions of possible interleavings. Testing can cover a tiny fraction of them. Proving correctness must account for all of them.
This is why concurrent systems are the last frontier of formal verification, and why race conditions haunt production systems for years before they manifest.
The Four Tiers: A Classification You Can Actually Use
Based on where a piece of software falls on these five dimensions, it lands in one of four tiers. I’ve formally proved that these tiers are exhaustive, mutually exclusive, and strictly ordered — every artifact goes into exactly one bucket, and the buckets are ranked by difficulty.9
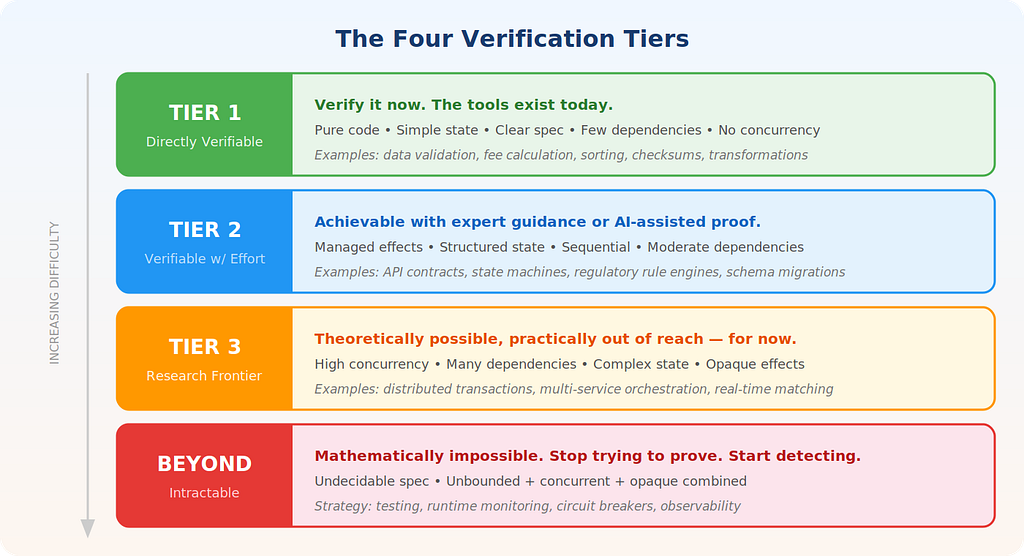
Tier 1 — Directly Verifiable. Pure code, simple state, clear spec, minimal dependencies, no concurrency. Current tools can handle this today. If your AI is generating pure data transformations, sorting algorithms, validation logic, or calculation engines — you can formally verify them. Right now. This is not speculative.
Tier 2 — Verifiable with Effort. Some managed side effects, structured state, sequential processing, moderate dependencies. You’ll need a theorem prover and either a human expert or a very good AI proof assistant, but it’s achievable. Think API contract verification, state machine correctness, regulatory rule engines.
Tier 3 — Research Frontier. High concurrency, many dependencies, complex state. Theoretically verifiable, but beyond what current tools can handle practically. Active research area. Think distributed transaction systems, real-time multi-service orchestration.
Beyond — Formally Intractable. The specification itself is undecidable, or the combination of unbounded state, full concurrency, and opaque dependencies makes verification provably impossible. Don’t throw money at formal verification here. Invest in robust testing, runtime monitoring, and circuit breakers instead. Know when to stop trying to prove and start trying to detect.
The Thing I Didn’t Expect: Purity Kills Concurrency
Here’s the result that surprised me the most.
If your code is pure (no side effects) and your state space is well-structured (finite or inductive), then the concurrency dimension collapses entirely. It effectively becomes zero.
Why? Because without side effects and with deterministic transitions, there’s only one possible execution trace for any given input sequence. There’s nothing to interleave. The scariest dimension of the framework just… vanishes.
This has a profound architectural implication: the way you generate the code determines whether you can verify the code. If your AI coding pipeline is configured to produce pure, structurally clean artifacts, you’ve preemptively eliminated the hardest verification challenge. This is a design-time decision, not a test-time one.
The Paradox: Who Verifies the Verifier?
Okay, but here’s the question sharp readers are already asking: if we’re using AI to write the code and AI to write the proofs, haven’t we just moved the problem?
Yes and no.
The proof-checking side is actually solved. Modern theorem provers have a tiny, human-audited kernel — typically a few thousand lines of code — that mechanically checks whether a proof is valid. This kernel is deterministic and exhaustively scrutinized. If it says the proof is valid, it’s valid. It doesn’t matter if the proof was generated by a human, an AI, or a monkey at a typewriter.
The specification side is NOT solved. If an AI generates both the code and the spec, it can (unconsciously, through optimization pressure) gravitate toward specs that are easy to prove rather than specs that are meaningful to prove. “I proved the output list has the same length as the input” is not the same as “I proved the output is correctly sorted.” The proof is valid. The spec is inadequate. You now have false confidence — the worst kind.
The fix: Specifications must remain under human review. The human says what the code should do. The AI figures out how to prove it does. The kernel confirms the proof is valid. Three-party separation of concerns.
Verified Pieces ≠ Verified System
One more finding that matters for anyone building systems from components: Tier 1 is not closed under composition.
Translation: you can have two individually verified components, combine them, and the result is not automatically verified. Why? Because each component’s verification depends on assumptions about its interfaces, and when you compose them, those assumptions accumulate. Two components with 2 external dependencies each combine into a system with 4, potentially pushing it past the Tier 1 threshold.
This is a real problem for microservice architectures. Each service might be verified in isolation, but the system-level guarantee requires an additional composition argument. That’s the subject of the next paper I’m working on.
So What Do I Actually Do Monday Morning? A Prescriptive Guide
Theory is nice. Toolchains are nicer. Here’s a tier-by-tier guide to what you can use today and what to watch for tomorrow.
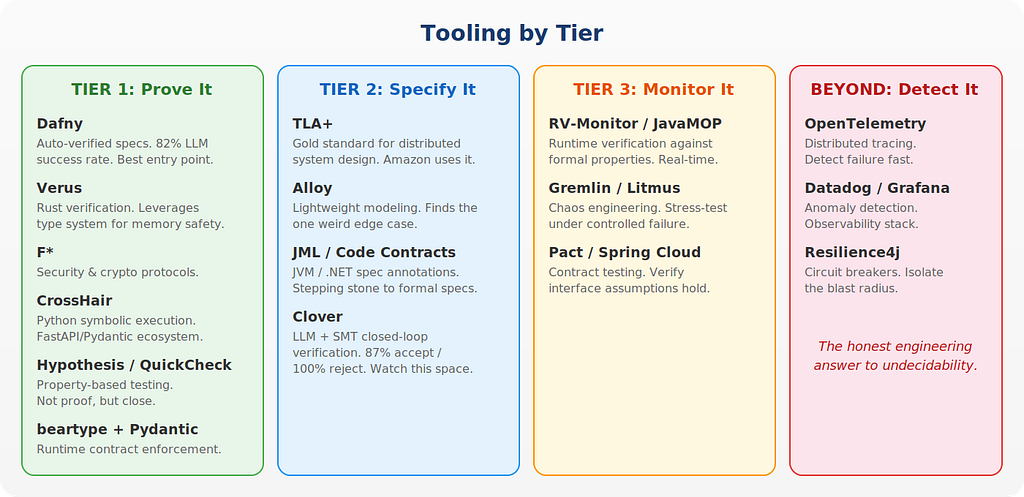
Tier 1 Artifacts: Verify Them. Seriously, Just Do It.
These are your pure functions, your data transformations, your business logic calculations. The tooling exists now:
- Dafny (Microsoft) — probably the most accessible entry point for working engineers. You write your code with specifications (pre/post-conditions, invariants) and Dafny’s solver proves them automatically. Recent benchmarks show LLMs can generate verified Dafny code with ~82% success rate. If you’re picking one tool to try first, this is it.
- Verus — if your team writes Rust, Verus adds verification to Rust programs. It leverages Rust’s type system to eliminate memory reasoning, letting you focus on proving functional correctness. Still maturing but extremely promising for systems-level code.
- F* (F-star) — designed specifically for verification-oriented programming. Strong in cryptographic protocol verification and security properties. If you’re writing code that touches authentication, encryption, or secure communication, look here.
- Property-based testing (Hypothesis, QuickCheck, fast-check) — not formal verification, but the next best thing for Tier 1 code where you’re not ready for a full theorem prover. These tools auto-generate thousands of random test cases from specifications. They won’t prove correctness, but they’ll catch far more edge cases than hand-written tests.
- CrossHair — if your team works in Python (and especially if you’re in a FastAPI / Pydantic ecosystem), CrossHair deserves a look. It uses symbolic execution to analyze your Python functions against their contracts — type annotations, preconditions, postconditions — and attempts to find counterexamples or prove their absence. It’s not a full theorem prover, but it bridges the gap between property-based testing and formal verification for Python code. Pair it with beartype or Pydantic’s built-in validation for runtime contract enforcement, and you get a lightweight Tier 1 assurance pipeline without leaving the Python ecosystem.
Tier 2 Artifacts: Invest in Specifications and Contracts
The bottleneck at Tier 2 isn’t the proving — it’s the specifying. Focus on making your intentions machine-readable:
- TLA+ (Leslie Lamport / Microsoft) — the gold standard for specifying distributed systems and state machines. It won’t verify your implementation directly, but it verifies your design. Amazon, MongoDB, and others use TLA+ to catch protocol bugs before writing a single line of code. If your AI is generating state machine logic or workflow orchestration, model it in TLA+ first.
- Alloy — lightweight formal modeling with automatic analysis. Great for exploring design spaces and finding counterexamples. Less about proving everything correct, more about finding the one weird case where your design breaks.
- JML (Java Modeling Language) / Code Contracts (.NET) — if you’re in a JVM or .NET shop, these let you add formal specifications directly to your codebase as annotations. They integrate with static analysis tools and provide a stepping stone from “tests that check examples” to “specs that constrain all behavior.”
- Clover / LLM-assisted verification pipelines — emerging research tools that use LLMs to generate code, specifications, and proofs in a closed loop, with an SMT solver rejecting anything that doesn’t check out. Early results show 87% acceptance of correct solutions and 100% rejection of incorrect ones. Watch this space.
Tier 3 Artifacts: Model, Monitor, Contain
You can’t prove these correct (yet), but you can be disciplined about managing risk:
- Runtime verification (RV-Monitor, JavaMOP) — these tools monitor running systems against formal properties in real time. If a specified invariant is violated at runtime, the system detects it immediately. Not a proof, but a safety net with teeth.
- Chaos engineering (Gremlin, Litmus) — if you can’t prove your concurrent distributed system is correct, stress-test it under controlled failure scenarios. Not formal verification, but a pragmatic complement for Tier 3 systems.
- Contract testing (Pact, Spring Cloud Contract) — for microservice compositions where interface assumptions are the weak link. Contract tests verify that each service honors the expectations of its consumers. This directly addresses the interface surface area dimension.
Beyond Tier 3: Accept, Detect, Recover
- Observability stack (OpenTelemetry, Datadog, Grafana) — when you can’t prove correctness, detect failure fast. Structured logging, distributed tracing, and anomaly detection become your primary assurance strategy.
- Circuit breakers and graceful degradation (Resilience4j, Hystrix patterns) — if a component can fail in ways you can’t prove it won’t, isolate the blast radius. This is the engineering honest answer to undecidability.
Where This Goes Next
The decomposition question. If a system is too complex for direct verification (Tier 3 or beyond), can we systematically break it into pieces that are verifiable, and does verifying the pieces give us confidence in the whole?
Early results say: it’s subtle. Decomposition and recomposition are not symmetric. But there are conditions under which it works, and I think they’re formalizable. Stay tuned.
I’d Love to Hear What You Think
Some questions I’m genuinely wrestling with and would appreciate perspectives on:
- How are you assessing trust in AI-generated code today? Is it code review? Testing? Vibes?
- Does the tier model match your intuition? When you think about the AI-generated code in your codebase, can you mentally place it in one of the four tiers?
- Where does formal verification fit in your organization’s risk posture? Is it seen as academic overhead, or is there appetite for it as AI-generated code proliferates?
- The specification problem — who in your organization would be responsible for writing the formal specs that AI-generated code gets verified against?
- Have you tried any of the tools above? I’d love to hear war stories — what worked, what didn’t, what surprised you.
Drop a comment. Disagree with me. Tell me I’m wrong about the tiers. That’s how this gets better.
I’m finishing an academic paper with the full formal framework and machine-checked proofs behind these ideas. I’ll share the link here once it’s published. If you work on formal methods, AI code generation, or software assurance and want to collaborate on the decomposition paper, reach out.
Your AI Just Wrote 500 Lines of Code. Can You Prove Any of It Works? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.