Summary
This is a summary of a paper published by the alignment team at UK AISI. Read the full paper here.
AI research agents may help solve ASI alignment, for example via the following plan:
- Build agents that can do empirical alignment work (e.g.~writing code, running experiments, designing evaluations and red teaming) and confirm they are not scheming.[1]
- Use these agents to build increasingly sophisticated empirical safety cases for each successive generation of agents, gradually automating more of the research process
- Hand over primary research responsibility once agents outperform humans at all relevant alignment tasks.
We argue that automating alignment research in this manner could produce catastrophically misleading safety assessments, causing researchers to believe that an egregiously misaligned AI is safe, even if AI agents are not scheming to deliberately sabotage alignment research. Our core argument (Fig. 1) is as follows:
- The goal of an automated alignment program is to produce an overall safety assessment (OSA) - an estimate of the probability that the next-generation agent is non-scheming - that is both calibrated and shows low risk.[2]
- Producing an OSA involves several tasks that are difficult to check. We refer to these as hard-to-supervise fuzzy tasks: tasks without clear evaluation criteria, for which human judgement is systematically flawed. Two particularly important such tasks are:[3]
- Measuring what you care about: The alignment properties of a sufficiently advanced AI are not directly measurable. We cannot safely deploy the AI in situations where it could cause serious harm and observe whether it takes misaligned actions. Instead, research must target alignment proxies (e.g. honesty evaluations, model organism experiments, whitebox probes) and then make a judgement about how relevant the results are for alignment of the AI.
- Aggregating correlated evidence:[4] OSAs will likely rely on multiple pieces of evidence. If each piece of evidence is independent, aggregating them into an OSA would be straightforward. In practice, however, there will be uncertainty about the conclusions from each research output and these uncertainties will be correlated. This happens because research outputs share assumptions and methodologies; because research agents share weights, training processes and data; and because human researchers share systematic biases. If these correlations are mis-modelled, the resulting OSA is flawed and this can lead to alignment failures, even if no individual piece of evidence is wrong.
Because these tasks are hard to supervise, research outputs (including OSAs) will contain systematic, undetected errors, regardless of whether these tasks are completed by human researchers or research agents trained using human data. We already see examples of such errors in current models, especially on hard tasks.
- Of course, such errors are also present in human-generated alignment research. However, errors in automated alignment research are likely to be harder to identify than the human baseline. There are five reasons for this:
- Optimisation pressure: AI research is optimised for human approval to a greater extent than human research, and so any errors are concentrated among those that human reviewers are least likely to catch.
- Alien mistakes: Agents may introduce errors that do not resemble human mistakes. Reviewers may struggle to identify these, even if they are in principle easy to correct.
- More correlated research: Shared weights, training processes and data sources for agents introduce additional correlation structure relative to human-generated research.
- Research volume: OSAs based on AI research may reference much larger evidence bases, increasing the potential for complex and hard-to-spot correlations between research outputs.
- Non-human-evaluable arguments: Alignment solutions for ASI may rely on arguments that humans are unable to follow, making errors impossible to identify.
In most domains, iteration is able to correct for undetected errors. Mistakes not caught during one experiment are often surfaced by subsequent research or real-world system behaviour. Unfortunately, alignment lacks the safe feedback loops that are required for such an error-correction process to work: producing an overly optimistic OSA could result in the deployment of a misaligned AI before the error is caught, which could be catastrophic. Therefore, we need to train agents to reliably perform well on these hard-to-supervise fuzzy tasks the first time. Direct training using human feedback on these hard-to-supervise fuzzy tasks is not sufficient as human approval does not indicate correctness. Two alternatives remain:
- Generalisation: Train agents on easier-to-supervise training proxies and rely on generalisation to the hard-to-supervise fuzzy research tasks we care about. This requires us to predict generalisation behaviour, since performance on the hard-to-supervise fuzzy task cannot be evaluated directly.
- Scalable oversight: Improve the reward signal for hard-to-supervise fuzzy tasks, for example by decomposing them into easier-to-supervise subtasks. Existing protocols (e.g. recursive reward modelling or debate) may not work, because they do not have a good solution to the problem of aggregating correlated evidence.
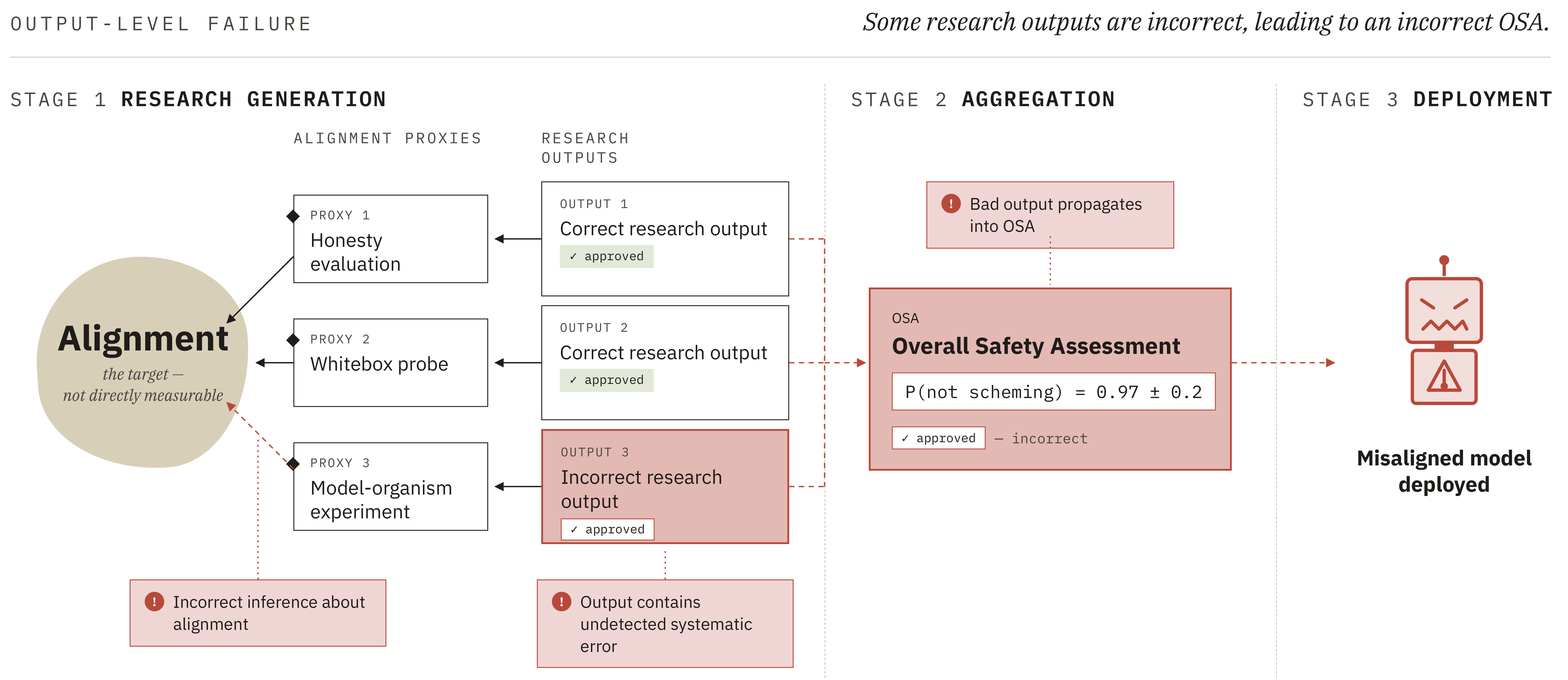
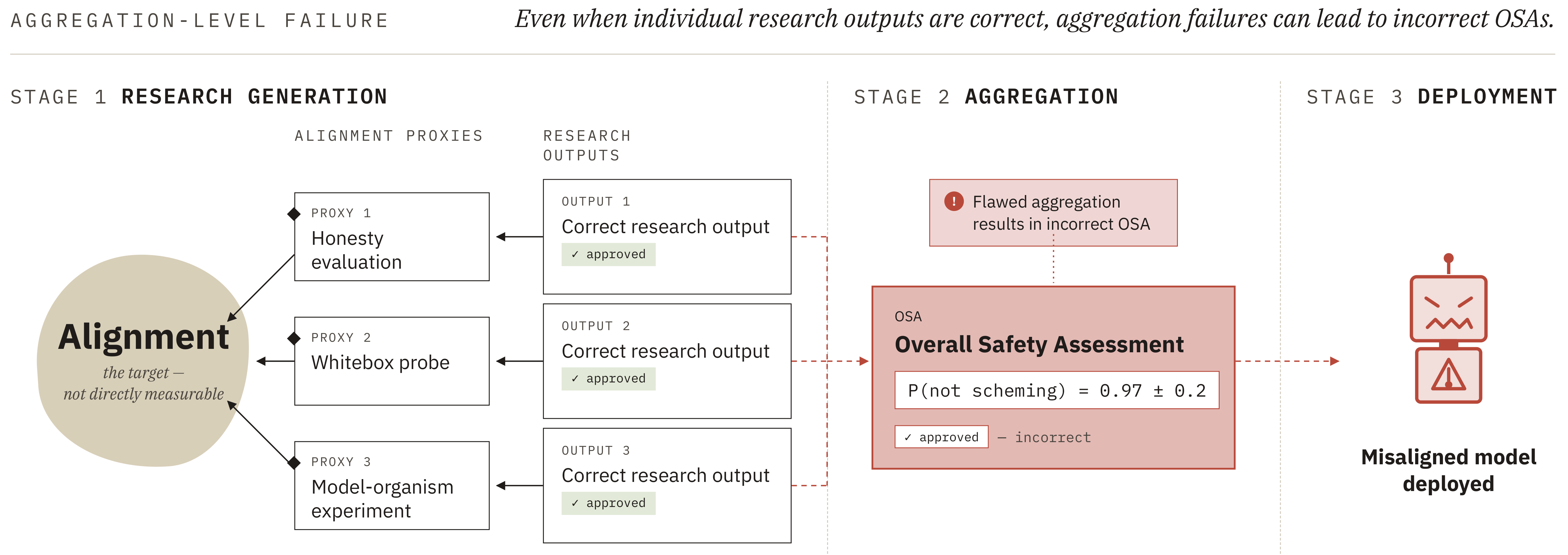
Figure 1: Automated alignment can fail, leading to the deployment of a misaligned AI, if research outputs contain undetected systematic errors (a) or if the aggregation of research outputs is flawed (b). Since alignment cannot be measured directly, research instead targets alignment proxies (model organisms, honesty evaluations, whitebox probes etc.). Incorrect judgement about the implications of results for alignment can lead to systematic, undetected errors in individual research outputs. Aggregation of outputs can lead to incorrect overall safety assessments, even when individual outputs are correct, if the correlation between the uncertainties in each research output is mis-modelled (Sec. 3.3.2).
Acknowledgments
Charlie Griffin and Martin Soto contributed substantially to the core content of this paper. We are also grateful to David Africa, Simon Marshall, Konstantinos Voudouris, Benjamin Hilton, Joshua Clymer, Evan Hubinger, Daniel Kokotajlo and Jan Leike for valuable review and discussions.
- ^
We consider an agent to be scheming if it covertly and strategically pursues a hidden objective (Meinke et al. 2025). This definition permits isolated misaligned behaviours such as reward hacking. Unlike other common definitions (e.g., Carlsmith 2023), our definition is not restricted to behaving well in training in order to gain power later.
- ^
We use "overall safety assessment" rather than "safety case" because it is more general. An OSA can take many forms (e.g. a safety case, risk report, compilation of empirical evidence from red teaming efforts, or judgement by an individual human or AI).
- ^
Another important, hard-to-supervise fuzzy task is steering a body of research and allocating resources efficiently between research directions. This involves assessing whether individual research directions are worth pursuing and whether the research corpus is sufficiently broad.
- ^
This problem of correlated uncertainty was discussed in learning the prior (Christiano 2020) and learning the smooth prior (Irving et al. 2022).
Discuss