Research Team Lead: Francesca Gomez
In collaboration with Caio V. Machado (The Future Society)
Arcadia Impact AI Governance Taskforce (Winter 2026 cohort)
Main insight: Thresholds and triggers for international escalation can be designed to isolate incidents requiring cross-border coordination for containment, mitigation, and shared response. For these to be operational in practice, it must be clear on what constitutes an incident across all AI risk domains, including patterns of incidents, and on what data is available to whom at each point along the incident pathway, to ensure that triggering conditions can actually be detected.
As AI systems become more capable and are increasingly deployed across borders and sectors, incidents involving these systems increasingly have international implications. Effective responses often depend on timely coordination between governments, companies, and other stakeholders. However, existing approaches to incident reporting and escalation vary widely, creating gaps in how risks are identified, assessed, and shared across jurisdictions. A central question is when an AI incident should trigger an international response.
For escalation to be effective in practice, it must occur early enough to enable the benefits of cross-border coordination, such as containment, mitigation, and shared response. This requires escalation thresholds and triggers that function reliably under real-world conditions, both for novel forms of AI risk and across key domains of systemic AI risk, namely, large-scale manipulation and psychological harm; loss of control; chemical, biological, radiological and nuclear (CBRN) threats; and cyber vulnerabilities and offensive capabilities.
In this blog we present an eight-criterion sequential escalation framework designed to identify when an AI incident requires international escalation. We share what we learned from stress-testing this framework against real AI incidents, including where the findings have implications for the design of existing frameworks such as the EU AI Act and SB 53, and where more fundamental gaps exist that any AI incident escalation framework will need to address.
What determines whether an incident warrants international escalation?
We define eight criteria to assess incidents against to determine if it warrants international escalation. The first two act as gateway filters to establish whether AI was a causal factor, and check the incident does not fall within an out of domain scope, such as military use. There is a then an upfront trigger check against a narrow set of conditions, including CBRN assistance, model weight exfiltration, and loss of developer control, where escalation should trigger immediately, before harm is confirmed, because the intervention window is short and no single actor has visibility of the full risk pathway.
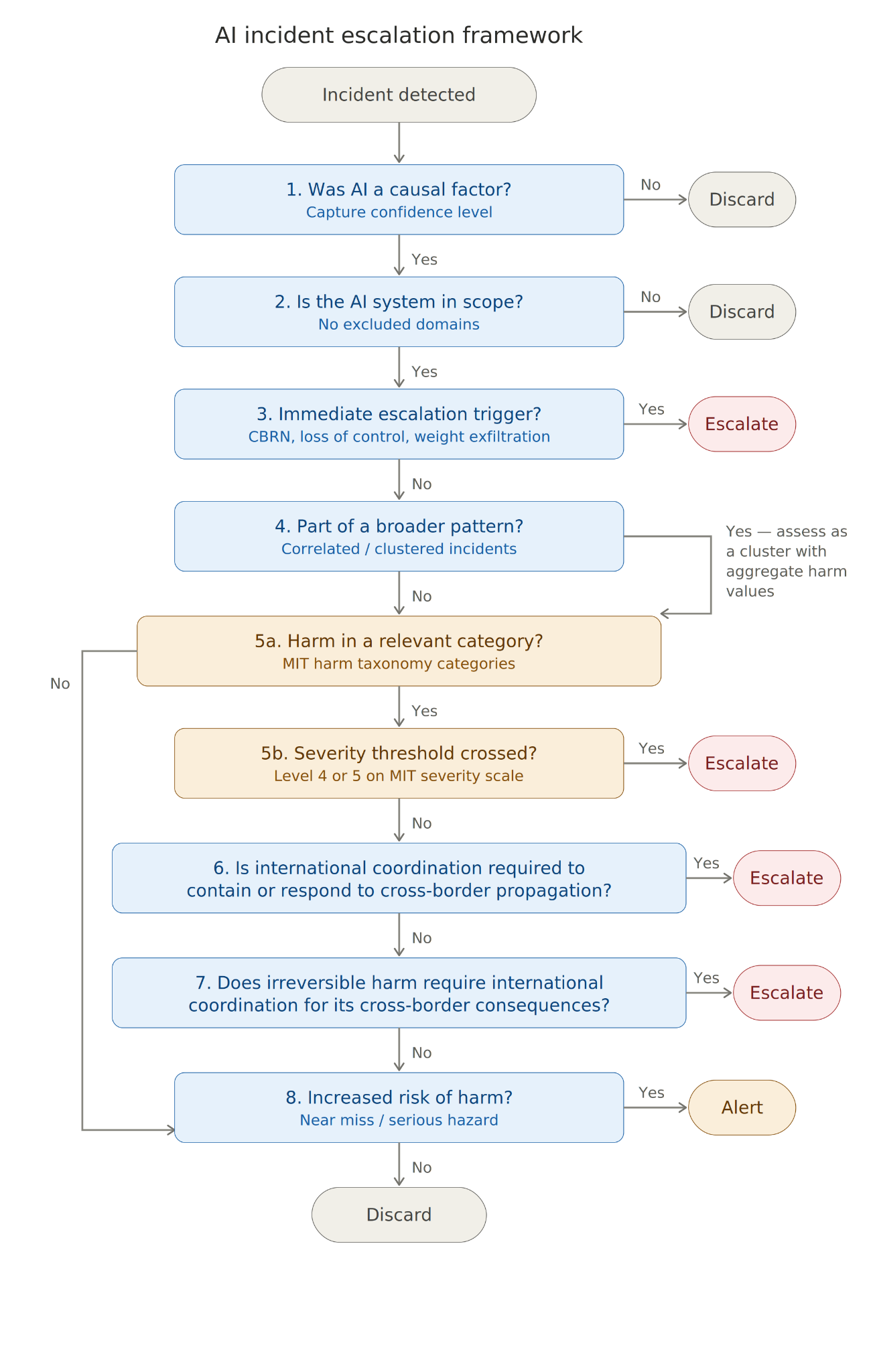
Beyond these, we check whether the harm and propagation of the incident should be assessed standalone or as part of a broader pattern of related events, before evaluating harm severity against a five-level scale. Where harm does not cross the severity threshold on its own, the framework checks whether cross-border coordination is needed to contain spread, and whether any irreversible harm has consequences extending beyond the affected jurisdiction. Finally, near misses that reveal inadequately mitigated risks relevant to other developers or jurisdictions are captured as grounds for an alert, even where no harm materialized.
Three design patterns for escalation rules risk leading to underdetection of AI incidents
Through comparing the escalation frameworks in the EU AI Act and SB53 to the criteria defined in our escalation framework, we found three design patterns that could lead to systematic under-detection or misclassification of AI incidents in regimes where model developers are responsible for escalation.
For some incident types, such as model weight exfiltration or credible CBRN threats, the developer who first observes the risk materialzing is unlikely to have any visibility of downstream harms. Where frameworks require confirmed harm before escalation, these incidents will typically only be escalated after severe, irreversible harm has propagated, by which point the window for intervention may have closed. Mapping incident pathways and identifying who can observe each stage helps determine which incident types are most exposed to this pattern.
Secondly, harms from AI that only emerge from patterns of events, such as large-scale manipulation and psychological harm, risk being underdetected where frameworks include triggers for single incidents. Setting rules for clustering related incidents for assessing their aggregated severity could help broaden the scope of escalation frameworks to include these types of harm.
Where thresholds are closely tied to legal instruments, they may be impractical to test against under time pressure. For example, determining whether an incident constitutes an "infringement of obligations under Union law intended to protect fundamental rights" (Article 3(49)(c)) requires testable definitions that are rarely specified in advance. Tabletop walkthroughs of real incident types, as used in our research, can help surface thresholds that prove difficult to apply in practice. For these, measurable proxies could be defined before incidents occur.
Escalation rules depend on definitions of incidents and data being available to work in practice
From designing escalation rules, we found that these are only one component of the broader escalation framework. Equally important are the underlying definitions against which thresholds and triggers are set, which include incident types, risk pathways, harm categories, severity scales, and clustering rules, and the data available to the actor responsible for determining whether a trigger condition has been met. Gaps in either layer mean escalation rules cannot work as intended, regardless of how carefully they are designed.
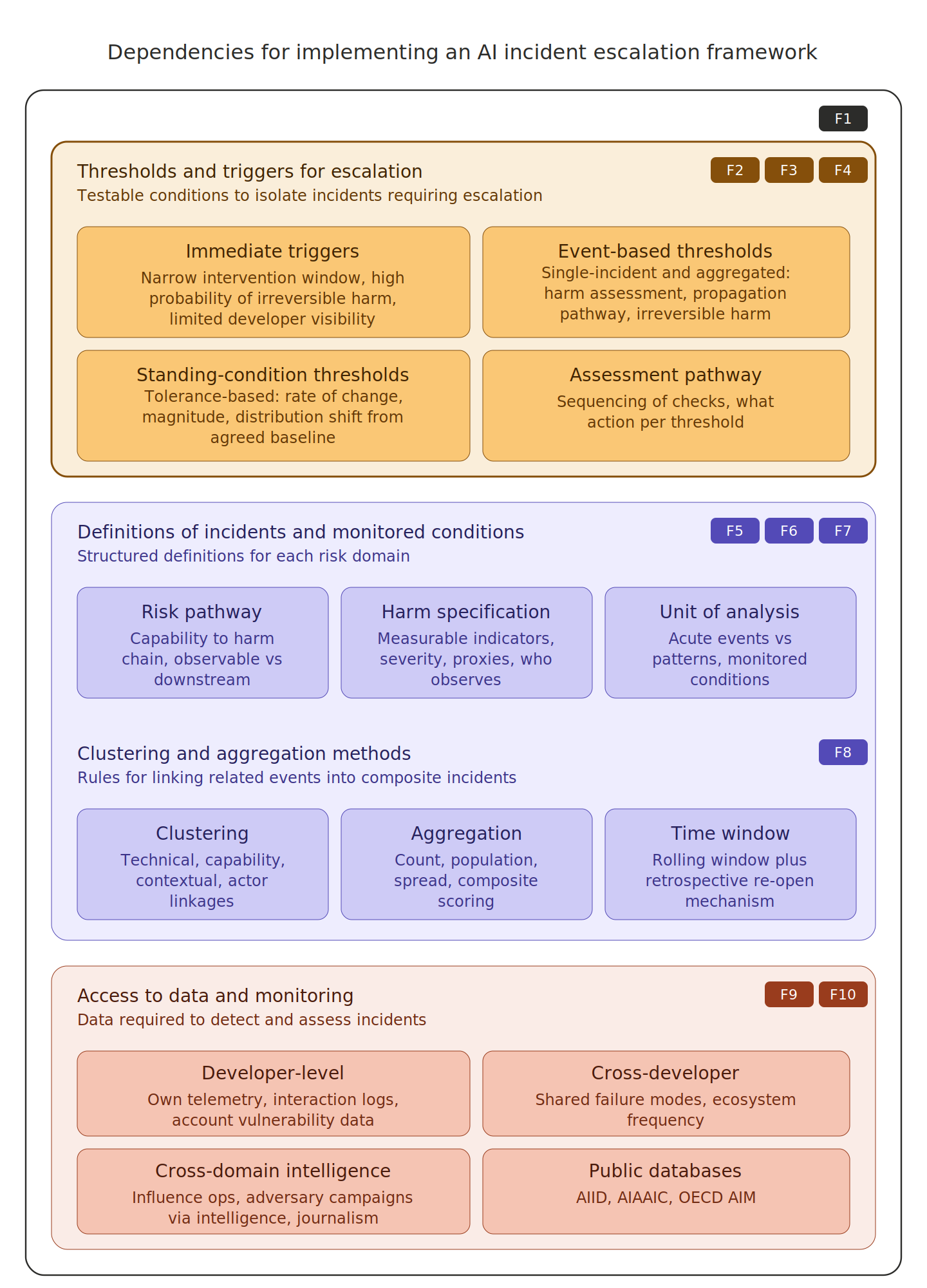
Definition gaps primarily affect domains where risk pathways and harm impacts are less well understood: large-scale manipulation, psychological harm, and loss-of-control risks. Harm severity scales lack adequate categories for manipulation and psychological harm, and no practical mechanism yet exists for adjusting severity assessments for incidents affecting vulnerable populations, despite regulators and developers having identified these groups as requiring heightened protection.
Data gaps concern the dispersal of information needed to operate triggers across disconnected sources. Pattern-based triggers, covering cumulative harms, shared failure modes, and frequency acceleration, require visibility across providers that is only feasible with shared definitions, interoperable schemas, and data-sharing agreements. Some incident clusters, such as state-orchestrated influence campaigns, produced no signal in any developer's systems and were detected only through national intelligence and investigative journalism, requiring pre-specified interfaces with institutions whose mandates already cover adversarial campaign detection.
What needs to happen next
An immediate next step is to identify patterns in existing frameworks that risk under-detection. This could be done using walkthroughs of incident pathways and defining escalation points that are practically feasible based on who can observe what data and when. For incidents involving standing harms, such as non-consensual deepfakes and psychological harm from human-AI interaction, acceptable baselines need to be defined and what rate or magnitude of change should trigger escalation.
Secondly, the most critical definitional gaps that thresholds rely on need to be addressed. For domains where incident types are less well defined, developing working definitions of what constitutes an incident, how harm can be measured, and provisional groupings for patterns, even if imperfect, would provide a usable foundation now and a basis for testing and refinement over time.
Thirdly, data gaps need identifying and prioritising. Mapping what data is available to whom, what can be detected from currently available sources and their distribution, and by which people. Where data gaps are likely to lead to systematic under-detection of categories of AI risk, exploring practical ways to address these, such as combining aggregated data patterns across providers, would improve detection capacity without requiring the full data-sharing infrastructure that longer-term solutions depend on.
The full paper is available as a preprint: Gomez et al. (2026), "Designing escalation criteria for international AI incident response: criteria, triggers, and thresholds."
This work was in collaboration with the Arcadia Impact AI Governance Taskforce and The Future Society.
Discuss