Where Agents Meet Data Foundations
In the early days of analytics and AI projects, especially proofs of concept, data rarely lived where it should. We passed around CSV files, Excel sheets, and one-off extracts. Models were trained offline and insights were generated in isolation. It worked for demos, but it was never how production systems were meant to operate.
Those days are largely behind us.

In modern enterprises, data is cleansed, governed, and continuously available inside databases and warehouses. Pipelines are stable. Schemas are standardized. Metrics are well defined. The system of record is always on. And now, with the rapid evolution of AI and agents, something important has changed again. Instead of exporting data to AI, AI increasingly comes to the data. Models and agents connect directly to the warehouse, query live systems, and act in place.
That shift is subtle but significant. When AI operates directly on production data, performance, cost, and reliability suddenly matter a lot more than experimental prototypes.
Over the past year, AI Agents have moved from experimentation to everyday architecture. Planning loops, tool calls, memory, and autonomous reasoning are no longer research ideas; they are production patterns.
The Data Engineer’s Perspective

As someone who leads an AI practice and actively builds agent-based systems, I am genuinely excited about what agents enable. They unlock automation and reasoning workflows that were previously impossible. At the same time, coming from a data engineering and SQL background, I have spent years optimizing queries, designing schemas, and building deterministic pipelines that run at scale.
That foundation changes how you evaluate architecture decisions. It teaches you to respect simplicity. It teaches you that the fastest system is often the one with the fewest moving parts. It also teaches you something that is easy to forget in an era of rapidly evolving tooling. Just because something is new does not mean it belongs everywhere. Just because a capability exists does not mean every problem needs it.
Data engineers live with the consequences of their decisions in a way that is hard to appreciate until you have been on call for a pipeline failure at midnight, or watched a poorly written query bring down a dashboard that a hundred people depend on. That experience builds a certain discipline. You learn to be skeptical of complexity. You learn that every abstraction has a cost, and that cost compounds over time.
Bringing that discipline into AI architecture is not about being conservative. It is about being precise. Agents are genuinely powerful tools. The goal is to deploy them where that power is actually needed and resist the temptation to reach for them simply because they are available.
Because in production environments, ROI beats novelty every time.
When the answer already exists in your data
Sometimes, enterprise questions are not reasoning problems. They are retrieval problems. They are questions like what was last month’s revenue by region, how many students attended this week, or how many customers churned yesterday. The answers already exist, cleanly structured, inside the warehouse. In these situations, the most efficient solution is not an agent. It is simply a direct query.
This distinction matters more than it might seem. There is a natural temptation, especially when new AI capabilities are available and exciting, to route everything through an intelligent layer. It feels more capable. But capability is not the same as appropriateness. A retrieval problem dressed up as a reasoning problem does not become smarter. It just becomes slower and more expensive.
The warehouse is already doing the hard work. Data has been ingested, cleaned, modeled, and made queryable. Metrics are defined. Schemas are stable. The system of record is always on. When the answer exists in that layer, the right move is to go get it directly, not to route it through anotherlayer that needs to figure out what you already know.
Recognizing retrieval problems for what they are is one of the most underrated skills in modern AI system design. It requires you to understand your data well enough to know that the answer is already there, and to have the discipline to resist adding intelligence where none is needed.
The Deterministic Approach: SQL and Stored Procedures
A few lines of SQL are often enough for such queries.
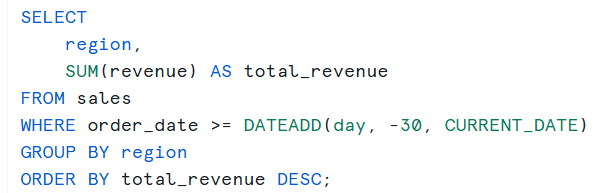
If this logic is reused frequently, it can be wrapped into a stored procedure and shared safely across dashboards and applications:
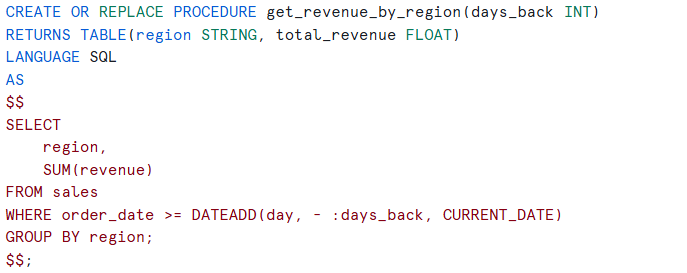
This runs directly inside the database. It returns in milliseconds. It is deterministic and easy to test. There are no tokens, no prompts, and no orchestration layers. Any compute cost incurred is negligible in comparison. From both a performance and cost perspective, it is extremely hard to beat.
While this was a relatively simple SQL example, even complex mathematical logic can yield immediate results at low cost when executed natively at the data layer. It is here that foundational database design, including strategic indexing and schema optimization, proves its worth. This ensures that performance remains predictable and highly efficient even as the computational complexity grows.
Why Using an Agent Here Would Be Overkill
Now imagine solving the same request using an agent. The question would be interpreted by an LLM, translated into SQL, executed through a tool, possibly validated or re-tried, and then formatted. Model selection itself becomes another variable. Multiple model calls. Extra latency. Additional failure points. More infrastructure. Yet the final step is still the same database query.
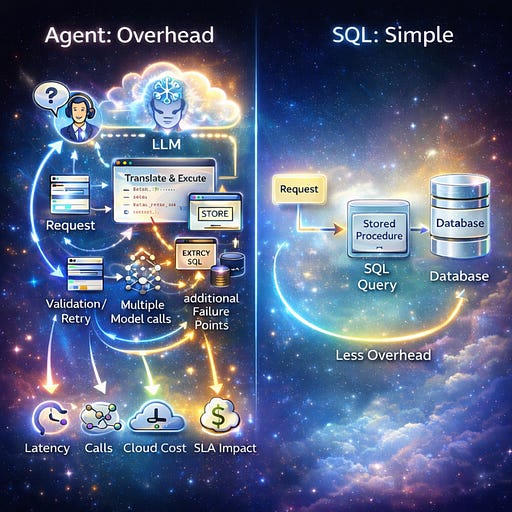
In this case, autonomy does not add value. It simply adds overhead. And at scale, overhead becomes expensive very quickly. Every extra second affects user experience. Every extra model call increases cost. Every extra abstraction makes debugging harder. When systems run thousands or millions of times per day, these tradeoffs show up directly on your cloud bill and your SLAs.
Where Agents Truly Shine
Agents are incredibly powerful when used where they truly belong. They shine when the path to the answer is not predefined, when you need to interpret messy text, reason through ambiguity, choose between multiple tools, or adapt dynamically.

Think of triaging thousands of support tickets, summarizing customer reviews, analyzing transcripts, extracting from documents, or orchestrating workflows across APIs. Vendor contracts that need non-standard clauses flagged and routed without human intervention. Incident response workflows where the agent reads error logs, queries system metrics, identifies the likely cause, and drafts the stakeholder update in a single loop. Employee onboarding pipelines that provision access across multiple systems and adapt based on role and location. Competitive intelligence workflows that gather signals from disparate sources, reconcile them, and surface what actually matters to the business.
What makes these solvable by agents is not just the tooling but the underlying reasoning patterns. ReAct loops let agents alternate between thinking and acting, refining their approach based on what each tool call returns. Plan and execute patterns break complex goals into sequenced steps, allowing the agent to adapt when intermediate results deviate from expectations. Reflection patterns let agents critique their own outputs before surfacing them. Memory patterns, both short term within a session and long term across sessions, allow context to persist and accumulate. These are not academic constructs. They are the architectural primitives that determine whether an agent handles a workflow reliably or collapses under ambiguity.
These are problems where deterministic logic struggles and reasoning adds real value. The input is unstructured, the path is non-linear, or the task requires judgment calls that no fixed pipeline can anticipate. Here, the extra complexity is justified because it unlocks capability you otherwise would not have. This is also where thoughtful architecture becomes important.
Designing Agentic Systems with Clear Boundaries
When we build agentic frameworks, it helps to be explicit about where intelligence is actually required and where it is not. Some steps should clearly route through reasoning and tool selection, while others should bypass the agent entirely and go straight to deterministic retrieval such as SQL or stored procedures. Designing these boundaries deliberately, rather than defaulting every request to an agent, creates a far more efficient system. The result is faster execution, lower cost, and fewer surprises, while still preserving the flexibility agents provide where it matters most.
This balance is what makes agentic systems practical, cost-effective, and not just impressive.
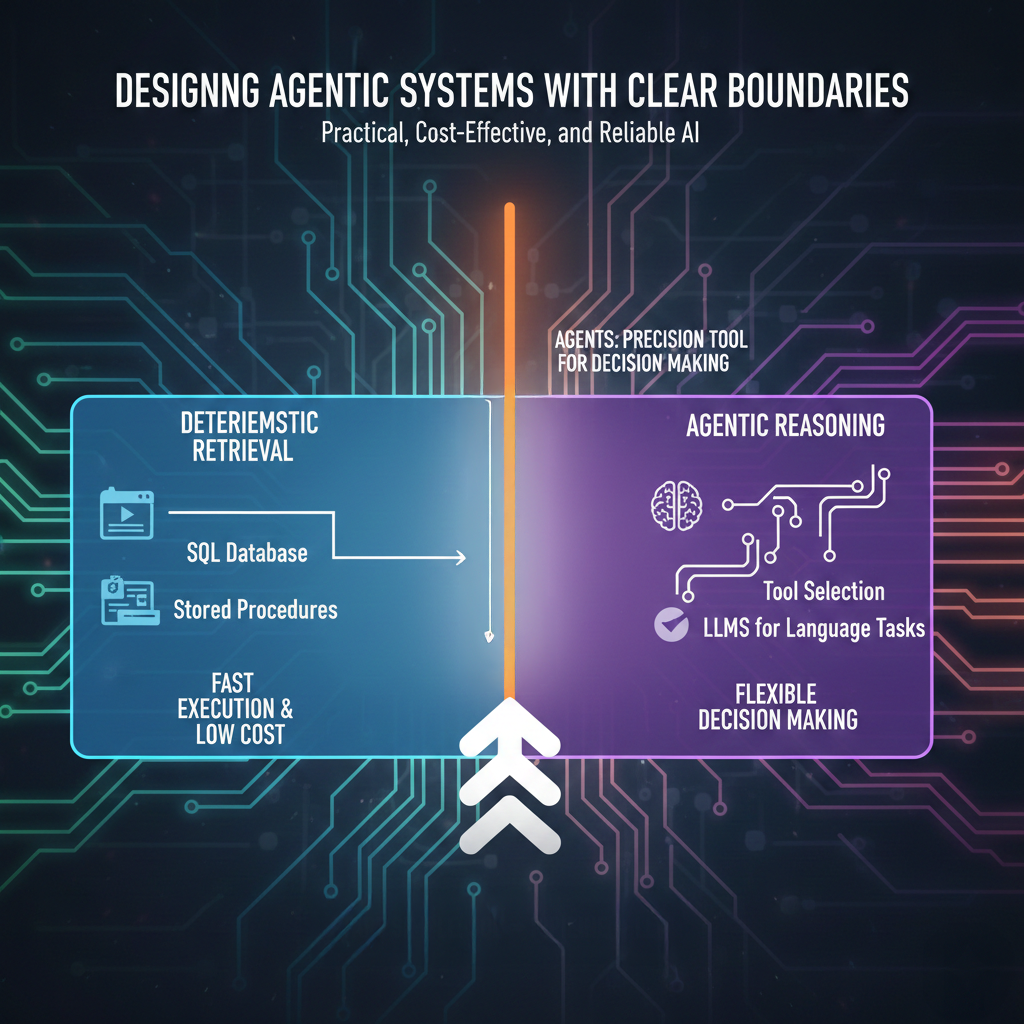
Over time, I have found a simple mindset works well. Start with the simplest solution that works and move upward only when necessary. If SQL solves it, use SQL. If a deterministic pipeline handles it, keep it that way. Add LLMs for language tasks. Bring in agents only when the workflow genuinely requires decision making. Agents then become a precision tool rather than a default pattern.
Eventually, the systems built this way tend to be better systems. They are faster, cheaper, easier to maintain, and easier to trust. Intelligence is applied exactly where it earns its keep.
Why SQL Skills Matter Even More in the AI Era
Bring all of this together and one truth stands out clearly. When you understand your schema and metrics deeply, you know when to go straight to the source. You don’t need an intelligent intermediary for something the database already does perfectly. Sometimes, the highest ROI “AI optimization” is simply better SQL or cleaner pipelines.
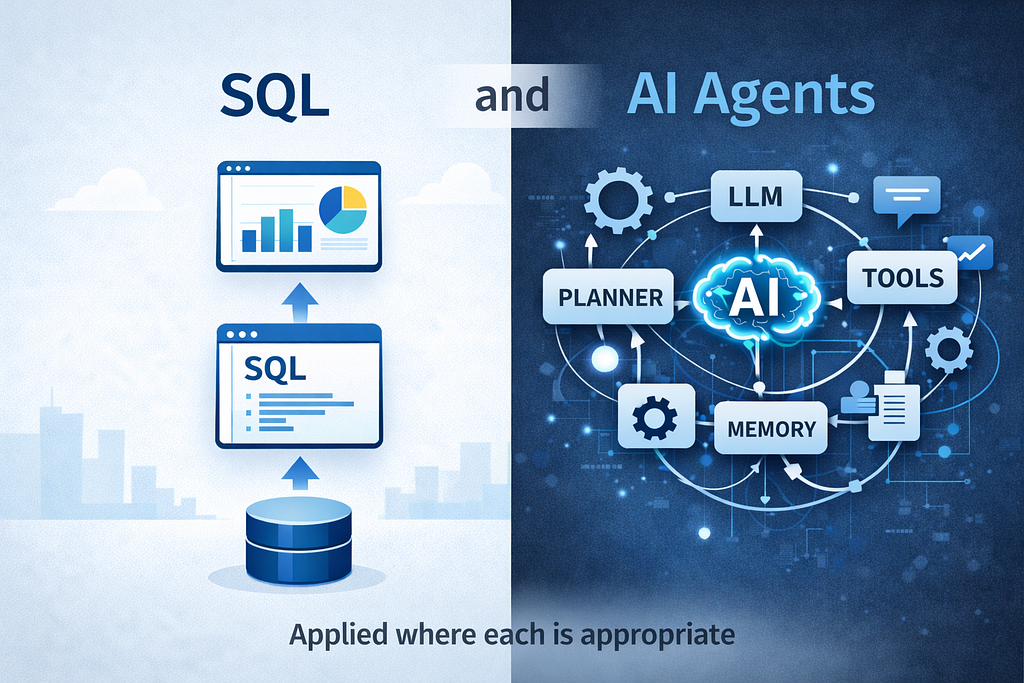
This is exactly why strong data skills matter even more in the AI era. Foundational data skills become more important, not less. The winning skill set is not “agent everywhere” or “SQL only.” It is the combination of both. Understanding databases deeply enough to avoid unnecessary complexity, and understanding agents well enough to deploy them where they create true leverage. That blend is what modern AI engineering really demands.
Because good architecture is about choosing the right kind of intelligence for the job. And sometimes, the smartest system is still just a well-written query.
I share hands-on, implementation-focused perspectives on Generative & Agentic AI, LLMs, Snowflake and Cortex AI, translating advanced capabilities into practical, real-world analytics use cases. Do follow me on LinkedIn and Medium for more such insights.
Agentic AI in Action — Part 21 - Where Agents Meet Data Foundations was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.