We are releasing the course materials of the Iliad Intensive, a new month-long and full-time AI Alignment course that runs in-person every second month. The course targets students with strong backgrounds in mathematics, physics, or theoretical computer science, and the materials reflect that: they include mathematical exercises with solutions, self-contained lecture notes on topics like singular learning theory and data attribution, and coding problems, at a depth that is unmatched for many of the topics we cover. Around 20 contributors (listed further below) were involved in developing these materials for the April 2026 cohort of the Iliad Intensive.
By sharing the materials, we hope to
- create more common knowledge about what the Iliad Intensive is;
- invite feedback on the materials;
- and allow others to learn via independent study.
We are developing the materials further and plan to eventually release them on a website that will be continuously maintained. We will also add, remove, and modify modules going forward to improve and expand the course over time. When we release a new significantly updated version of the materials, we will update this post to link the new version.
Modules
The Iliad Intensive is structured into clusters, which are a loose collection of related topics, which decompose into modules that are taught within one day. Each module consists of learning outcomes, prerequisites, and the content itself, including a fast-track and pointers for how to learn more. Sometimes, a teaching guide is added that explains how the content was taught during the April Intensive if this seems sufficiently informative.
We now summarize each cluster and module. You can find the main content in the linked tabs of the main google doc.
0 Prerequisites. This module collects what is useful to know before engaging with the materials. It points to writings that inform a background worldview — why AI matters, and safety risks — and then lists the technical prerequisites: deep learning, linear algebra, calculus, probability & statistics, information theory, and some theoretical computer science. General mathematical maturity is also very valuable.
Cluster A: Alignment
This cluster is on AI alignment, the problem of how to align AI systems or collections of such systems with a vision for how they should behave.
A.1 AI Alignment Introduction. In this module, we introduce the AI alignment problem as two combined challenges: We need to choose an alignment target, which is our vision for how an AI system or a collection of such systems should ideally behave; and we need to solve the technical problem of how to align AI systems with this vision. We discuss frameworks for how to decompose the technical problem further and critiques thereof in a learning framing, and how the potential goal-directedness of AI poses additional challenges. We conclude by surveying different viewpoints on the difficulty and severity of the AI alignment problem, and the spectrum of solution approaches to the technical problem that the field pursues.
A.2 Alignment in Practice. We step through the model development pipeline — pretraining, post-training, deployment — and build intuitions about what affordances each of the development phases gives us for model alignment. We then illustrate these affordances by discussing the state of the art methods employed by the major labs in each of the phases. We also mention key empirical results that are useful to build an intuitive model of LLM behavior. In the deployment phase specifically, we take a high-level view and briefly discuss the non-technical parts of aligning models — responsible scaling policies, safety cases, economic impacts of AI, and AI governance.
A.3 Reward Learning Theory. Reward learning is a particular framework to approach the outer alignment problem: Instead of specifying a reward function directly, we learn such a function from observing human behavior, most prominently in the form of trajectory comparisons in reinforcement learning from human feedback (RLHF). We reason through the assumptions that motivate the research area as a whole, and we show that RLHF leads to an outer aligned objective under the strong additional condition of human Boltzmann rationality. We then discuss ways in which real humans deviate from such ideal conditions, including limited competence or capacity to evaluate complex behaviors for difficult tasks. We conclude by discussing how reward learning can be embedded into the framework of assistance games, which is one potential, but controversial, conceptualization of the entire alignment problem.
Cluster B: Learning
The most powerful modern AI systems are based on deep learning, and it is increasingly likely that the first AGI systems will be too. Yet we lack a satisfying theoretical understanding of why deep learning works at all, let alone how to ensure its safety properties hold in new settings. This cluster asks what a rigorous understanding of deep learning would look like and why it matters for safety. We begin with the theoretical foundations of learning in general and the specific empirical mysteries of deep learning, then spend three days on concrete research directions — singular learning theory, training dynamics, and data attribution — that each attack a piece of the puzzle.
B.1 Principles of Learning. We ask: if AGI is a learning machine, what can we say about it in principle? We draw on the fields of statistical learning theory and algorithmic information theory. We first explore three fundamental barriers that any powerful learning system must overcome — approximation (can the hypothesis class express the truth?), generalization (can finite data distinguish truth from noise?), and optimization (can the learner find good hypotheses efficiently?) — and examine why these barriers are in tension with each other. We then introduce Solomonoff induction, which elegantly resolves the first two barriers via a universal hypothesis class and a simplicity prior, but completely fails on the third. Along the way, we cover the bias-variance tradeoff, the no free lunch theorem, and cryptographic hardness arguments for why efficient universal learning is impossible in the worst case. This is necessarily a lightning tour of large fields; the goal is to establish a shared conceptual vocabulary and theoretical reference point that the rest of the deep learning theory cluster builds on.
B.2 Mysteries of Deep Learning. We turn from learning in principle to learning in practice. Deep learning appears to overcome all three barriers from Day B.1, in ways that classical statistical learning theory could not predict or even actively counterpredicted — overparameterized networks generalize despite having the capacity to memorize, SGD finds good solutions on non-convex landscapes, and networks compactly represent functions in millions of dimensions. Beyond these, deep learning exhibits additional empirical phenomena that the classical framework doesn’t even address: learned representations converge across different architectures and training setups, models display in-context learning abilities that were never explicitly trained, etc. We survey these mysteries and explore candidate explanations, including the hypothesis that deep learning may be overcoming these barriers with similar mechanisms to Solomonoff induction. As with Day B.1, this is a broad lightning overview; the subsequent case study days (SLT, training dynamics, data attribution) each develop one specific line of attack on these mysteries in depth.
B.3 Singular Learning Theory. Within a neural network architecture, certain weight vectors correspond to structurally simpler neural networks. These degeneracies complicate the relationship between the neural network’s parameter space and the resulting space of functions. In turn, learning in neural networks is substantially richer than learning in classical statistical models. Singular learning theory (SLT) is a theory of learning that places degeneracies at the center. This module explores qualitative definitions of degeneracy in terms of the parameter–function map, the Fisher information matrix, and curvature of the loss landscape. We then introduce SLT’s central quantitative definition of degeneracy, the local learning coefficient, from the perspective of volume scaling asymptotics. Finally, we consider Watanabe’s free energy formula for Bayesian inference as a case study on the implications of degeneracy for learning.
B.4 Training Dynamics. This module discusses some key results of learning dynamics in deep neural networks, focusing on implicit regularization and emergence. The implicit regularization section examines how the training process, specifically stochastic gradient descent, can have an implicit bias towards simple solutions. The topics include loss landscape geometry, the edge of stability, simplicity bias, the neural tangent kernel (NTK), and the influence of initialization on training regimes (lazy vs. rich) in deep linear networks as an important toy model of deep learning. The emergence section investigates the puzzle of unexpected "emergent capabilities" (e.g., grokking, induction heads, silent alignment). It uses theoretical concepts like phase transitions to explain these phenomena, such as viewing grokking as a transition from the lazy to the rich regime. One application of this phase transition perspective is to understand and enable the early detection of emergence for AI safety.
B.5 Data Attribution. We turn the focus from the weight space to training data. We pose the question: how can we measure which training examples cause which model behaviors? After discussing the general role of data attribution for the purpose of alignment, we frame this as a technical question: how can we understand the counterfactual impact of perturbing, specifically reweighting, individual data points? We then develop three frameworks that each make the problem tractable by interpreting the map from data to trained model differently: influence functions (as an implicit function of data weights at a unique minimum), Bayesian influence functions (as a posterior distribution over parameters), and unrolling (as a concrete optimization trajectory). These turn out to be closely connected: influence functions emerge as a limiting case of both alternatives, and the degeneracy phenomena studied on the SLT day reappear in understanding where and why the classical theory breaks down.
Cluster C: Abstractions, Representations, and Interpretability
This cluster studies the internal representations and mechanisms of cognitive systems: how can we reverse-engineer the features and circuits of trained neural networks (C.2, mechanistic interpretability), what is the structure underlying optimal prediction in context, and do transformers recover it (C.3, computational mechanics), and how can we define a notion of “natural” abstractions on which different agents modelling the same world converge (C.4, abstractions and natural latents). C.1 provides the practical ML engineering foundation for the cluster.
C.1 Intro to ML Engineering. This module equips participants with the practical skills needed to follow the rest of the intensive and run their own empirical experiments. Split into two parallel morning tracks by prior experience, participants learn the essentials of training neural networks in PyTorch: tensor operations, training loops, autograd, optimizers, loss functions, and core architectures like CNNs and transformers, alongside the engineering realities of empirical work, including renting GPUs via Runpod, tracking experiments with WandB, lightweight experimentation through fine-tuning APIs and Tinker, and managing datasets and checkpoints on Huggingface. The afternoon turns to LLMs specifically: tokenization, the transformer architecture, and the full lifecycle of a modern language model from pretraining and scaling laws to RLHF and reasoning training, with hands-on exercises implementing an MLP and attention step by step.
C.2 Mechanistic Interpretability. We take a look at the science of reverse engineering the learned structures of a neural network. By going through the history of mechanistic interpretability, we examine the methods used to identify features and circuits, the ontology and assumptions underlying those methods, and we sample the main findings that mechinterp has made so far. We start with early work on CNNs and then turn to transformers, looking specifically at linear probes, steering vectors, and directional ablations; superposition and sparse autoencoders, including their compressed sensing motivation, evaluation, and known failure modes like feature absorption and splitting; and circuit discovery via logit attribution, the logit lens, path patching, ACDC, attribution graphs, and causal scrubbing. Throughout, we include hands-on exercises on feature visualization, logit lens, induction heads, SAE training, and exploration of Neuronpedia. The day closes with a group discussion of major critiques of the field.
C.3 Computational Mechanics. Suppose a neural network is performing near-optimal prediction of a fixed stochastic process: what internal representations should we expect it to maintain? Computational mechanics addresses this question by identifying convergent structures of optimal prediction. In this module, we develop this framework for processes admitting a generalised hidden Markov model (GHMM) realisation. Starting from hidden Markov models (HMMs), we motivate the definition of GHMMs through considerations of minimality and uniqueness. We then develop two complementary perspectives on Bayesian inference over HMM emissions: a geometric perspective through belief states, and an algorithmic perspective through the mixed state presentation (MSP) — both of which naturally extend to GHMMs. Participants will design their own processes and explore the empirical evidence that transformers trained on GHMM data learn belief-state geometry in their residual streams, before developing mechanistic hypotheses about how this geometry is constructed and used.
C.4 Abstractions and Latents. Human values are expressed in terms of latent variables in our world models rather than in terms of low-level physical states. Transferring values to an AI therefore requires establishing a correspondence between the human's and the AI's internal representations of the world, which is tractable only if different agents converge on the same abstractions. This module develops the formal theory of natural latents — latent variables pinned down by mediation and redundancy conditions — and the complementary condensation framework, which explains how world models decompose into discrete, interpretable conceptual structure. Together they provide agreement and translatability theorems grounding the hope that value-relevant concepts are shared across agents.
Cluster D: Agency
The alignment problem is believed to be particularly difficult if AI systems act as agents with long-term goals in an unbounded environment, thus displaying agency, which we study from a largely theoretical perspective in this cluster.
D.1 Reinforcement Learning. We provide a brief introduction to Reinforcement Learning from the fundamentals, covering tabular RL (chapters 2-4 of Sutton and Barto) in two streams. The empirical stream directly follows Day 1 of ARENA and covers implementing policy iteration/evaluation, Q-learning, and SARSA for toy gridworld environments in Python. The theory stream proves a series of results including the Bellman equations, the convergence of policy iteration and its rate, and the convergence of Q-learning, and derives an analytic solution to the Bellman equation.
D.2 Idealised Agency. This day is split into two parts.
Part (1) on AIXI closely follows An Introduction to Universal Artificial Intelligence (UAI). This theory module is based on a set of self-contained exercises that introduce the history-based RL framework that UAI works in. We prove some results about interaction measures over histories and Bayesian mixtures, we define the optimal Bayesian agent AIXI, we prove well-defineness of the optimal value and existence of optimal policies, and we build up to three main results: The Bayesian mixture converges on-policy to the true environment, AIXI cannot be fooled by deterministic environments, and AIXI can learn to perform well in an environment in which learning is possible (the self-optimizing property).
Part (2) introduces the notion of preferences as a general way to encode goals and/or desires of general agents. Then, it presents which are the necessary and sufficient assumptions (in the form of axioms) to represent preferences as maximising (i) an utility function, (ii) an expected utility, and (iii) an expected discounted future reward. It also explores what are the consequences of dropping different axioms. It also briefly discusses the difference between these results related with representation of preferences, with stronger results pertaining to coherence and selection of agents.
D.3 Agent Foundations. A central challenge in alignment is that we must reason about the behavior of superintelligent agents before such systems exist and before we can learn from mistakes. This module develops formal tools for doing so across several agendas: coherence arguments and the Complete class theorem, Löb's theorem and the Löbian obstacle to safe self-modification, tiling agents and Vingean reflection, logical induction and reasoning under logical uncertainty, functional and updateless decision theory, and the thermodynamics of optimization.
D.4 World Models. World models are a key feature of advanced agents, which allows them to plan and consider counterfactuals without actually taking actions. This module focuses on developing a formal understanding of what world models are and what they are not, and how agents can use them to their advantage. The module is structured into three units: (a) a general introduction to world models and how they are used in modern AI, (b) an exploration of how world models can be formalised in the context of RL, and (c) and overview of how agents can use world models to build abstractions. In doing so, the module adopts an interdisciplinary approach combining ideas from computer science with principles from statistical physics, neuroscience, and cognitive science.
Cluster E: Safety Guarantees and their Limits
This cluster discusses debate, an approach to directly align AI systems with human overseers and a proposal for how its safety could be established, and several limits to ensuring the transparency and safety of AI systems in general.
E.1 Debate. How can we extend a reward signal for problem solving when AI systems may become smarter than their human evaluators? In purely syntactic domains, such as formal mathematics, correctness can in principle be verified by checking formal proofs step by step, but this becomes infeasible for exponentially long computations and does not apply cleanly to semantic, real-world tasks that depend on costly human judgment. The Debate framework addresses this by having two AI systems argue against each other, reducing difficult global verification problems to sequences of small local checks; in idealized settings, this yields logarithmic-depth verification and, in cross-examination settings, even constant-size local consistency checks. This course covers proof checkers, syntactic vs. semantic tasks, the complexity-theoretic power of Debate and Cross-Examination (including proofs that DEBATE=PSPACE and CX=NEXP), the practical limitations of finite debaters such as obfuscated arguments, the prover-estimator approach, and the UK AISI debate-based alignment safety case and its open problems.
E.2 Steganography and Backdoors. This module covers steganography and cryptographic backdoors as two classes of techniques that challenge interpretability, monitoring, and control of AI systems. It introduces steganography as the concealment of hidden messages inside innocent-looking outputs such as text, emphasizing cryptographically secure schemes that are computationally undetectable and discussing how channels like paraphrasing can destroy hidden communication. Students will study why steganographic behaviour is difficult to detect or prevent, including Merlin–Arthur classifiers as a possible counter-strategy, and examine theoretical foundations such as the proof that perfect steganography requires secret randomness satisfying H(M)≤H(K), alongside practical computationally secure schemes. The module also explores cryptographic backdoors in LLMs, including unelicitable backdoors based on computational hardness and white-box-undetectable approaches that hide triggers in random weight distributions, highlighting their implications for theoretical interpretability. Through paper readings, exercises, and discussions—including CoT obfuscation, collusion, weight exfiltration, cryptographic transformer circuits, and Goldwasser et al.’s ReLU construction—students will analyze how covert communication and hidden triggers could emerge in advanced AI systems and how such mechanisms might be designed, detected, or mitigated.
E.3 Worst-case Interpretability. Any interpretation of a neural network is a lossy compression: it trades the model's full complexity for a shorter, human-understandable description. How to formally deal with the resulting approximation error is unclear. We discuss proofs as a rigorous, but pessimistic, approach that immediately yields quantifiable metrics for faithfulness and compactness. A concrete example shows that worst-case pessimizations are too strict to be scalable and will lead to vacuous bounds even on simple models. This suggests that neither pure worst-case nor pure average-case evaluation is adequate on its own, opening the door for an intermediate approach. We conclude by connecting this to ARC's agenda of heuristic arguments.
Contributors
Here we briefly list all contributors to the Iliad Intensive with the modules they contributed to or their general role. In each module tab to the side of the main google doc, we also list the contributors to that module.
- Leon Lang (Iliad):
- Course materials coordination
- 0 Prerequisites
- A.1 AI Alignment Introduction
- A.3 Reward Learning Theory
- Exercise creation for B.1 and D.1
- Evžen Wybitul (University of Oxford):
- A.2 Alignment in Practice
- Zach Furman (The University of Melbourne):
- B.1 Principles of Learning
- B.2 Mysteries of Deep Learning
- B.3 Singular Learning Theory
- Kai Ogden (University of Oxford):
- B.3 Singular Learning Theory
- Matthew Farrugia-Roberts (University of Oxford):
- B.3 Singular Learning Theory
- Guillaume Corlouer (Moirai):
- B.4 Training Dynamics
- Louis Jaburi (EleutherAI):
- B.5 Data Attribution
- E.2 Steganography and Backdoors
- E.3 Worst-case Interpretability
- Julian Schulz (Meridian Research):
- C.1 Intro to ML Engineering
- C.2 Mechanistic Interpretability
- Adam Newgas (Timaeus):
- C.1 Intro to ML Engineering
- Xavier Poncini (Simplex):
- C.3 Computational Mechanics
- Daniel Chiang (Independent):
- General teaching support
- C.4 Abstractions and Latents
- D.3 Agent Foundations
- Satya Benson (Williams College):
- C.4 Abstractions and Latents
- D.3 Agent Foundations
- David Quarel (Australian National University):
- D.1 Reinforcement Learning
- D.2 Idealised Agency
- Fernando Rosas (University of Sussex):
- D.2 Idealised Agency
- D.4 World Models
- Stephan Wäldchen (Independent):
- E.1 Debate
- E.2 Steganography and Backdoors
- Adrian Worrall (Meridian):
- General teaching support
- Margot Stakenborg (Independent):
- Final-stage editing and coordination
- David Udell (Iliad):
- Head of Capacity Building, Iliad
- Alexander Gietelink Oldenziel (Iliad):
- Executive Director, Iliad
Guest lectures / Q&As:
- Paul Riechers and Adam Shai (Simplex): Q&A on computational mechanics
- Cole Wyeth (University of Waterloo): Lecture on reflective oracles and nonrealizability
- Aram Ebtekar (Independent): Lecture on decision theory
- Marie Buhl (UK AI Security Institute): Lecture on a safety case for debate
- Joar Skalse (Deducto Limited and King’s College London): Lecture on reward learning theory
- Richard Ngo (Independent): Lecture “Towards a Theory of Identity”
Impressions from April
Overall, participants liked our course and recommend it to others, and largely think it provides a unique learning experience that is hard to find elsewhere. Here are a few selected testimonials:
"Genuinely life changing, I could not imagine a better course for understanding AI safety than the Iliad Intensive. Taught by incredible teachers, explaining incredibly tough concepts.”
“Crazy pressure cooker for all of the interesting theoretical interp research agendas. New and ambitious, the best place to get a big uplift in both overview and depth of the field.”
“Iliad Intensive has given me a clear view and intuitions for the landscape of more theoretical AI alignment research directions, and a clearer picture of how I can contribute to this.”
“To my knowledge, this is a really one-of-a-kind course in goals and content: it filled a niche that I had long felt overlooked, i.e. theoretical upskilling or transition towards AIS research.”
“This was the most beneficial learning experience in AI safety I have had so far.”
“The Intensive was a game changer for me. It gave me a coherent view of the AI safety/alignment landscape, showed me how to connect math and physics skills with alignment, connected me with a network of researchers, and afforded me the time to start work in this area. It also came at the perfect moment, as AI is rapidly transforming much of society, including my corner of academia.”
Yet when looking into the feedback, we find many avenues for improvement. For example, the teaching quality was not consistently at the standards we aspire to:
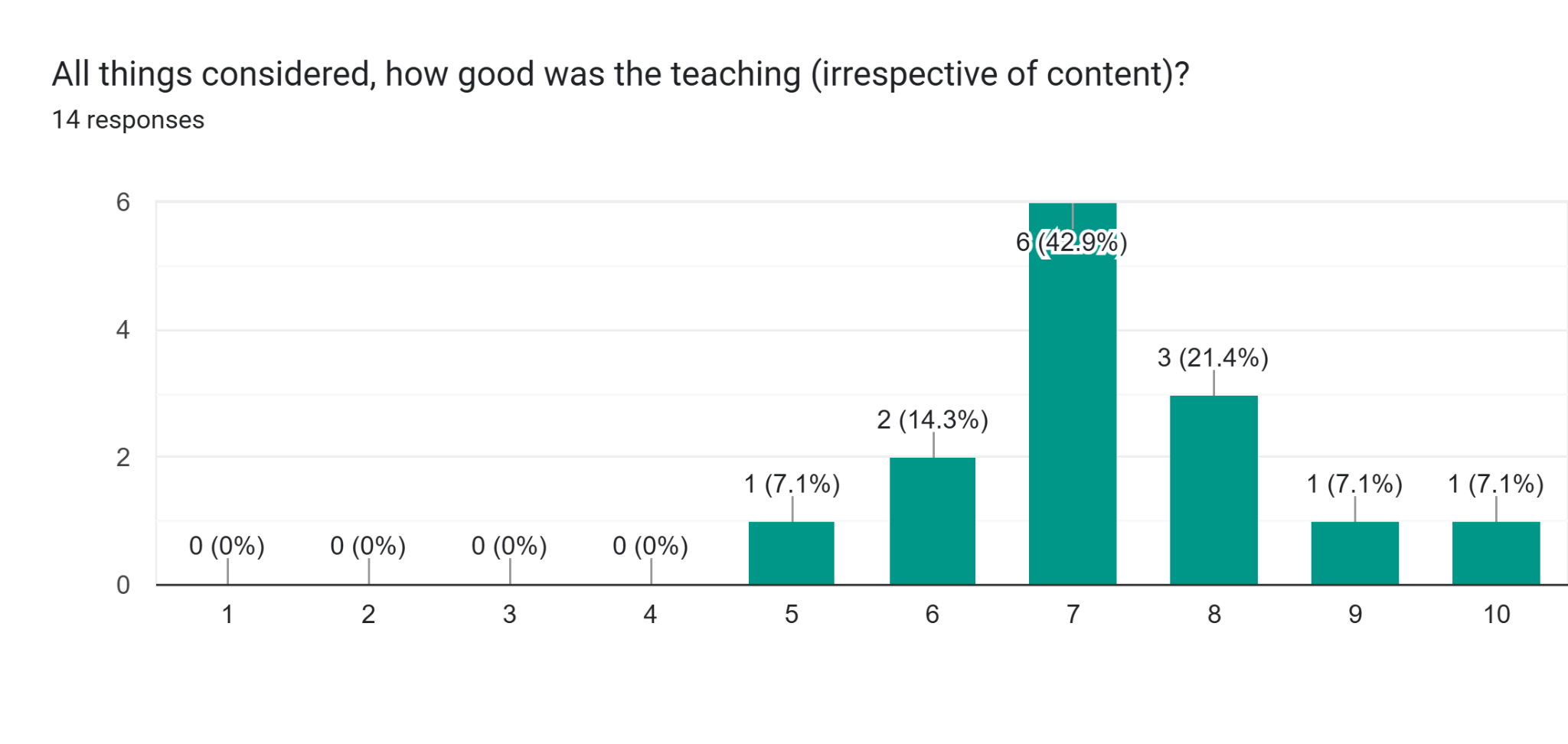
And the selection of topics did not convince every participant:
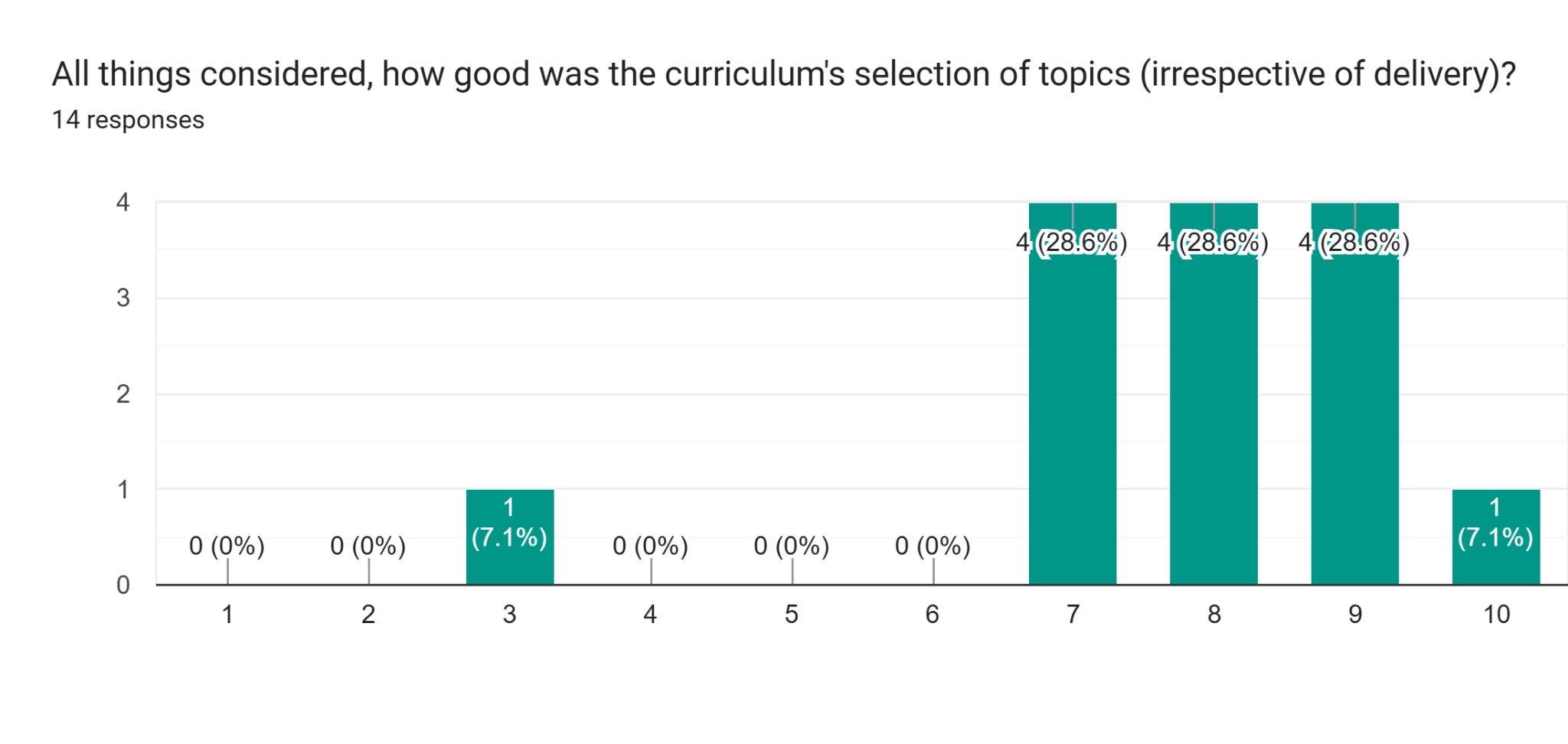 A more comprehensive analysis of the Iliad Intensive, including avenues for further improvement, may follow after future iterations. Meanwhile, we continue to improve the Iliad Intensive to make it the best course it can be.
A more comprehensive analysis of the Iliad Intensive, including avenues for further improvement, may follow after future iterations. Meanwhile, we continue to improve the Iliad Intensive to make it the best course it can be.
Acknowledgments
We thank the London Initiative for Safe AI (LISA) for hosting us during the April iteration.
Feedback
Please provide feedback on the materials either in the comments of this post, or as an email to feedback@iliad.ac.
Discuss