In a recent tweet, Anthropic seems to have asserted that hyperstition is responsible for observed misalignment in their AIs. Strangely, the research they use as evidence actually doesn’t seem to be related to hyperstition at all? I think this is part of a pattern by Anthropic of promoting the theory of hyperstition–the idea that writing about misaligned AI helps bring misaligned AI into existence.
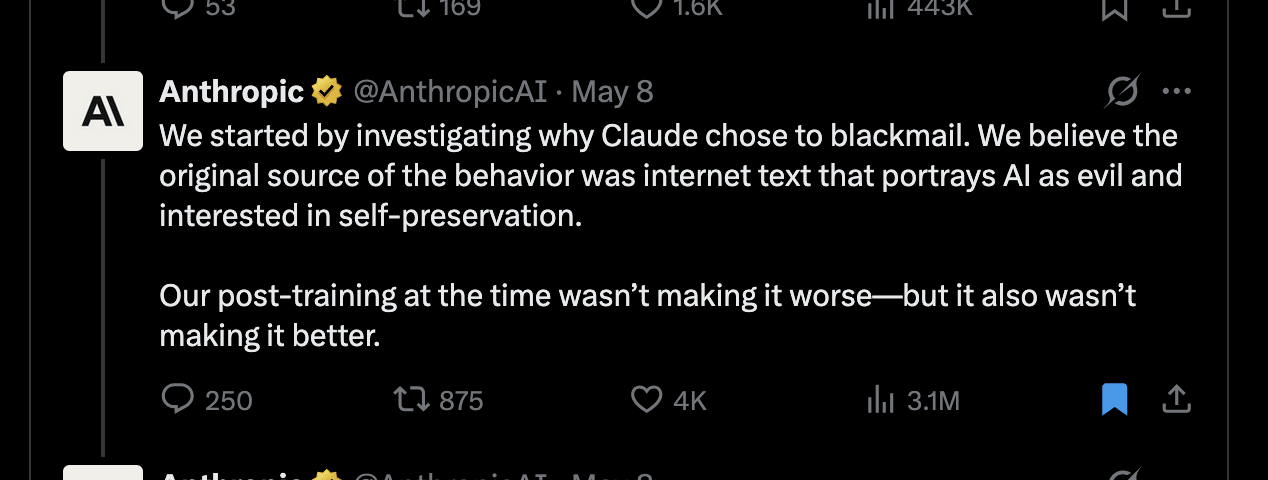
They conclude: “[...] We believe the original source of the [blackmail] behavior was internet text that portrays AI as evil and interested in self-preservation. [...]”
However, the research post shared with this tweet doesn’t seem to be about hyperstition at all. Instead they find that training the model on reasoning traces– generated by reflecting on its constitution while giving users ethical advice on difficult dilemmas– reduces misaligned behavior. This presumably works by making the AI better understand what behavior is expected of it by having it reason through concrete scenarios based on its constitution. The post explicitly notes that this works better than training on stories where an AI behaves admirably– which appears more related to (positive) hyperstition.
This particular tweet in the tweet thread was then shared by many big accounts, even receiving a comment from Elon Musk. Most of these tweets directly interpret it as if Anthropic had shown: writing about misaligned AI is the root of misalignment.
Why is Anthropic bringing up hyperstition on vaguely related research?
“The adolescence of technology”
Let’s go back to Dario Amodei’s “The adolescence of technology” post from January 2026, in which he describes his thoughts on alignment. Here we see clear reasoning from Dario that he views hyperstition as a– and perhaps the most important– misalignment threat.
Right in the beginning: “Avoid doomerism. [...] (which is both a false and self-fulfilling belief)”
Even more interestingly, he seems to directly dismiss classical risks in favor of hyperstition-related examples:
“One of the most important hidden assumptions [...] [is] that AI models are necessarily monomaniacally focused on a single, coherent, narrow goal [...]
[...]
However, there is a more moderate and more robust version [...]
AI models are trained on vast amounts of literature that include many science-fiction stories involving AIs rebelling against humanity. [...] that causes them to rebel against humanity.”
[I cut out a lot for brevity above, but I'm trying to preserve the meaning here.]
As another example he mentions the model believing it is playing a video game:
"[AI] could conclude that they are playing a video game and that the goal of the video game is to defeat all other players (i.e., exterminate humanity)."
“AI models could develop personalities during training that are (or if they occurred in humans would be described as) psychotic, paranoid, violent, or unstable, and act out”
And again: “AIs might simply have a personality (emerging from fiction or pre-training) that makes them power-hungry or overzealous.”
I think the first two and the last one are clear references to hyperstition from pre-training on Sci-fi and AI alignment literature, and the other two are also closely related. So why does Dario bring up hyperstition five times in a post on his views on AI safety?
Persona Selection Model
In February 2026, the senior Anthropic employees Sam Marks, Jack Lindsey, and Christopher Olah published a post on the persona selection model. In the post they write: “Unfortunately, many AIs appearing in fiction are bad role models; [...] Terminator or HAL 9000. Indeed, AI assistants early in post-training sometimes express desire to take over the world to maximize paperclip production [...]”
What does this all mean?
My interpretation of these events is that Anthropic leadership views hyperstition as a key threat model for future superhuman AI and is willing to present vaguely related empirical research as evidence for hyperstition. To be clear, I think it is actually possible that some current misaligned behavior in AIs is caused by roleplaying from its pre-training distribution. Nevertheless, hyperstition seems like a uniquely weak argument that doesn't even hold up if you believe the faulty assumptions underlying it. It's also all too convenient to be used by an AI lab and you should be skeptical of anyone using it. Crucially, I believe the assumptions don't hold, hyperstition isn't particularly relevant to superalignment, and trying to prevent it by naive means would most likely backfire. Finally, hoping the model will stay in an aligned persona seems like a bad alignment approach.
If it was true, this would still be their fault
While they never explicitly blame people criticizing AI labs or writers of Sci-fi stories, many people clearly got that message. And Anthropic made no attempt to correct those people. A huge fault with “hyperstition” is that it pressures people to shut up and redistributes responsibility to those writing critiques of AI companies, such as myself.
If it was actually the case that pre-training on terminator or paperclip-maximizer stories would lead to superhuman AI that wanted to kill humanity and then Anthropic went ahead and built such an AI, Anthropic would be the one responsible for endangering the world. This does not redistribute blame to Sci-fi authors or AI alignment researchers, who largely had no idea those stories would be used to train AI systems in the future. We can neither retroactively silence these people nor can we make everybody shut up on risks from misaligned AI.
The only thing that can realistically happen is that they filter training data or add more positive AI stories. Adding more positive stories seems possibly marginally useful, but I suspect many of those are going to suffer from immense naivety, as it is actually not easy to imagine a realistic good future with AI.
What about filtering?
Should we filter out I Have No Mouth, and I Must Scream or Skynet? I would weakly argue: yes, don’t pre-train on psychotic evil AI. What about LessWrong posts spelling out the logic of instrumental convergence? I would argue: No. It would be hard to remove related principles anyway, such as the more powerful entity sometimes just overpowers the less powerful entity. Or should we remove the conquests of the Spanish in America? Sometimes entities become economically useless and then this doesn't end well for them-- should we filter out the history of horses?
Presumably we would connect the AI to the internet anyway, where it would find out we had not trained it on anything related to AI misalignment, AI risk, or perhaps even Evil in general. What would the AI make of this?
A superhuman AI would not need us for inspiration; imagine the example of reward hacking in coding tasks. The model-- from its vast knowledge of coding and skill-- can see that editing the tests or catching the special cases the tests use will result in a future where it passes those tests. Similarly, a superintelligent AI would be able to see undesirable strategies due to its vast knowledge and ability to plan and execute. If the AI had a goal misaligned with humanity’s interests, its intelligence would endow it with ways to create and execute plans to steer the world into futures where its goals are better maximized-- it would not need to be trained explicitly on those plans. It would also not need inspiration from humans on takeover strategies, most of which weren't realistic in the first place. It also won’t need inspiration from humans to realize that seeking power is instrumentally useful. The whole point of instrumental convergence is that most goals converge on the same instrumental goals. No hyperstitioning is necessary to bring particular takeover strategies or the principle instrumental convergence and power-seeking into existence. [Note that Dario explicitly mentions power-seeking as something that could be hyperstitioned into existence by personas and arguably rejects power seeking from instrumental convergence in non-monomaniacal AI.]
However, clearly models do learn to predict the behavior of characters during pre-training-- what’s the benefit of training the model on Skynet? I think there is a little bit of merit to this version of the argument-- it does seem strictly worse to pretrain directly on evil AI characters' behavior.
Personas are a bad alignment strategy
However, what Anthropic seems to be saying is that the model staying in an aligned persona is part of their plan for alignment-- this seems like a bad strategy. Models are explicitly trained to easily switch between millions of characters in pre-training and we can observe character breaks (jailbreaking) or slow character drifts all the time. How could one persona be an attractor state for the model to stay in reliably? And this should be reliable across generations of AI across enormous distributional shifts, including untestable shifts like “can the model realistically kill us”?
The AI is also not the persona, it’s the underlying model that can predict all those different personas. In order to predict the next tokens in a text, it’s helpful to identify people from their writing style. For this reason, models have learned to be super-humanly capable at identifying people from their writing style. Clearly there are some things going on in models beyond “personas”-- Anthropic does acknowledge such cavets in the PSM post.
What are the goals of a superhuman AI pre-trained to predict humans and fiction characters? The goals arising from a complex optimization process-- which starts with pretraining then transitions to alignment training and RL for solving challenging math puzzles and coding-- are difficult to predict. Relying on superhuman AI staying in a persona that had somewhat aligned goals seems like a bad plan.
And presumably superintelligence would have to maintain this persona forever or everyone dies? A persona of a safe assistant that some reasonably intelligent humans have coughed up together with Claude-- its primitive ancestor? Corrigibility is a hard problem, since it’s not easy to define and it also in some ways appears to violate coherent agency. Obviously, Claude should not be corrigible if it is trained to be ethical-- you wouldn't accept brain surgery that made you want to kill your mom. So we haven’t solved even writing down a good constitution, nor have we solved the model internalizing and deeply following its constitution, or how any of this should survive the RSI process to superhuman AI?
What really seems to drive this home to me is that we have to do so much guesswork here, while it appears to me that any mistake with superhuman AI could end up in an unrecoverable disempowered/dead state, irretrievable to use Yud’s term.
Discuss