A quiet technique that lives between the model and your output: letting the scene decide what counts as a valid detection.
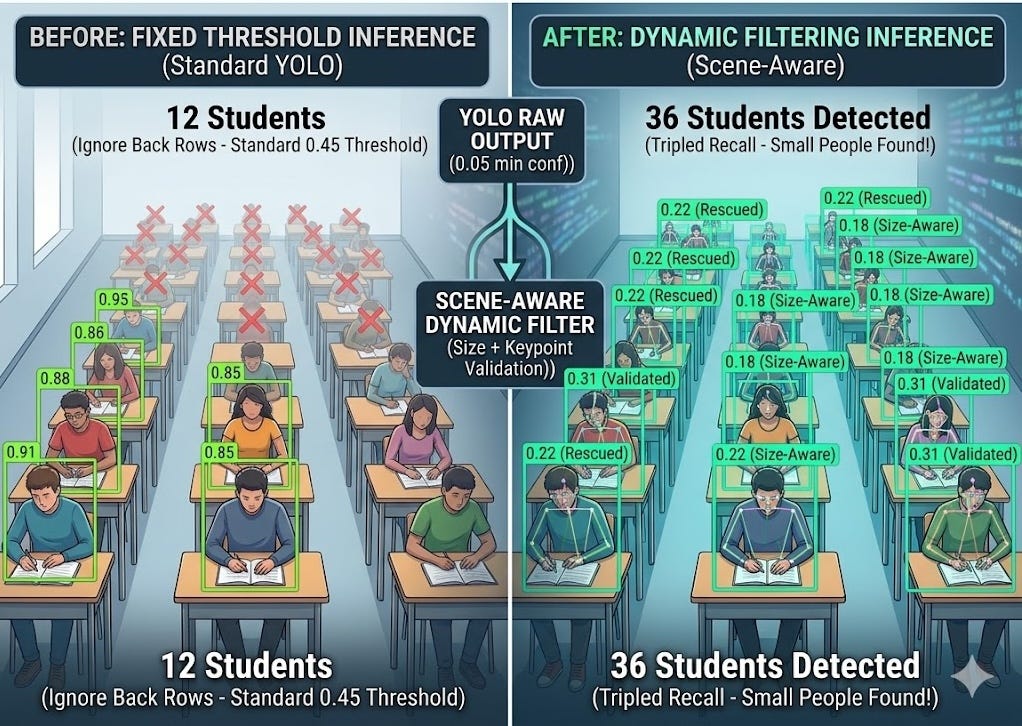
If you work with object detection in crowded spaces, like a classroom or an auditorium, you know the struggle. The students in the first three rows are detected perfectly with 0.85+ confidence.But Everyone further back? Ignored. Not because they weren’t there. Not because they were occluded. Just because they were small, and the model’s fixed confidence threshold was cutting them off.
I was running a pose-estimation YOLO model on a classroom feed. Out of about 40 students, standard inference was only picking up the 10–12 sitting nearest to the camera.
The standard advice here is usually:
- Annotate more data of tiny people and fine-tune.
- Use a much heavier model.
- Implement SAHI (Slicing Aided Hyper Inference)
But I needed something faster that didn’t require an A100 to train or run.So I didn’t retrain the model, I didn’t add a new dataset, augment images, or touch the weights at all. I changed what happens after the model speaks, and went from detecting 10–12 persons to consistently catching 30 or more.
The Approach : Stop Treating All Bounding Boxes Equally. The model already sees them. It just doesn’t trust itself enough to say so - unless you build a smarter listener.
What is the exact problem with a fixed Confidence Threshold?
Every object detection pipeline has a confidence threshold - a number that says “only show me detections the model is at least X% sure about.” In YOLO models, this defaults somewhere around 0.25 to 0.50. It’s a global number, applied equally to every detection in every frame.
That works well when your subjects are large, well-lit, and close. But in a crowded room - a classroom, a lecture hall, a warehouse floor - you have massive variation in apparent size across the same frame. A person in row 1 takes up 30% of the frame height. A person in row 8 takes up maybe 4%. The model’s confidence score for that row-8 person might be 0.08. Your threshold is 0.25. Gone.
Here’s what makes this quietly interesting: that 0.08 score isn’t the model saying “I don’t see a person there.” It’s the model saying “I see something person-shaped, but I’m not very confident.” There’s a difference. And that difference is where this approach lives.
- TRADITIONAL APPROACH : One fixed threshold, applied uniformly. Optimised for precision. Small/distant subjects systematically dropped.
- ADAPTIVE APPROACH : Threshold varies per detection based on box size and the frame’s own score distribution. Small subjects get a fairer chance.
- THE TRADE OFF : Lower thresholds invite false positives. The system must compensate with secondary evidence to stay honest.
- THE SECONDARY EVIDENCE : Pose keypoints - nose, left shoulder, right shoulder. If those are confident, the bounding box probably is real.
How the filtering works - conceptually
Instead of a static threshold, I opened the floodgates. I set the initial model confidence extremely low (around 0.05) to capture every possible candidate, and then passed those candidates through a custom, dynamic three-step filter.
The approach has three layers, each doing a different job:
- Run the model very permissively : Instead of the default confidence cutoff, the model is asked to surface almost everything-candidates with scores as low as 0.05. This is intentional. The goal is to gather the full population of “possible persons” before any filtering happens.
- Compute a frame-level reference threshold : Rather than using a fixed number, look at the distribution of confidence scores across all candidates in this specific frame. Use a low percentile of that distribution as a soft floor. A frame full of high-confidence detections naturally demands more. A frame of distant, low-confidence candidates adapts accordingly.
- Scale the threshold by bounding box size : Smaller boxes get a lower required confidence than larger ones. A person who occupies 40% of the frame height should need to clear a higher bar than one who occupies 5%. The math is simple - a linear function of relative box height — but the effect is meaningful.
- Keypoint rescue for borderline cases : If a detection still doesn’t clear the adaptive threshold, there’s one more chance: examine the pose keypoints the model produced for that candidate. If the nose and both shoulders have high confidence, the detection is rescued and kept. A bag or chair doesn’t have confident shoulders. A person usually does.
- Final NMS pass : After filtering, a standard non-maximum suppression removes any overlapping duplicates. What remains is a set of candidates that passed either the adaptive score filter or the keypoint rescue - no more, no less.
The Results
The jump in recall was staggering. By allowing small objects to have lower thresholds and verifying weak boxes with strong keypoints, the back half of the classroom suddenly “lit up” with stable, accurate tracking IDs.
This is the part worth sitting with: the model was generating keypoint predictions for these “undetected” people all along. The skeleton was there in the output - just silently discarded because the box score didn’t clear the gate. The filtering layer was essentially ignoring evidence that the model itself had produced.
The Elephant in the Room : Why isn’t this standard?
This is the part I genuinely wondered about while building this. The technique isn’t novel in any deep sense - adaptive thresholding has roots in classical image processing, and the idea of using secondary features to validate a primary detection is well-established. So why isn’t there a standard “adaptive post-filter” module that ships with every detection pipeline?
I think the answer is a mix of a few things:
- First, most benchmark evaluations reward precision over recall. When you tune a model for COCO mAP, a false positive hurts more visibly than a missed small detection. That culture propagates into defaults conservative thresholds, safe settings.
- Second, this approach is scene-dependent. The parameters that work beautifully in a fixed-camera classroom (stable background, consistent lighting, known density) could behave erratically in a busy street scene or a dark nightclub. The frame-level percentile threshold specifically assumes that “most candidates in this frame are real persons” - an assumption that holds in a classroom and breaks in many other contexts.
- Third, the keypoint rescue path introduces a dependency on pose estimation. You can’t apply this to a plain object detection model. It requires a pose-aware model like yolov8n-pose or similar, which narrows the applicable contexts considerably.
It feels like a technique that seasoned CV engineers might use quietly, but shy away from discussing because it isn’t as robust as purely data-driven solutions or architectural shifts like SAHI.
The Broader Idea : Listening to the model more carefully
What I find conceptually interesting about this isn’t the specific implementation - it’s the framing. A detection model produces a rich output: bounding boxes, confidence scores, class probabilities, and in the case of pose models, a full set of keypoint predictions. Standard pipelines reduce all of that to a binary: above threshold, or not.
This approach treats the model’s output more like a conversation. The bounding box score is one voice. The keypoint confidences are another. The frame-level distribution is context. When one voice is uncertain, you check the others before making a decision. That’s not a novel insight - it’s what any careful analyst would do. But it’s surprisingly rare in deployed CV pipelines.
The same logic could extend in other directions: temporal consistency (if a box appeared in the last three frames, be more lenient about confidence in this one), spatial priors (if we know people tend to sit in rows, penalise detections in unexpected locations), or even auxiliary classifiers trained specifically to distinguish true low-confidence persons from high-confidence clutter.
I’d Love to hear your thoughts
This approach emerged from a specific problem - person detection in a fixed-camera classroom - and it worked well enough there that I wanted to write it up. But I’m genuinely uncertain how widely applicable it is, and whether the specific combination of adaptive thresholding + keypoint rescue has been formalised anywhere I haven’t looked.
If you’ve encountered research or deployment work along these lines, I’d love to hear about it. A few directions I’m curious about:
- Are there published papers on scene-adaptive post-filtering for person detection specifically? The closest I’ve found touches on dynamic NMS and soft-NMS, but not quite this.
- Has anyone formalised the keypoint-as-secondary-evidence approach in a way that generalises beyond COCO-keypoint models?
- For those who’ve deployed complicated(crowded) person/object detection in fixed-camera settings: what post-processing do you actually use? Is this already standard practice somewhere and just not written about?
- Would you consider this a technical debt trap, or a valid optimization layer for fixed-camera pipelines?
Drop a comment, or point me to a paper, a repo, a blog post - anything that moves this conversation forward. The model already sees these people. I want to know if anyone else has found better ways to listen to it.
I Tripled My YOLO Detection - Without Retraining was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.