The Biggest Mistake Tech Companies Are Making With AI Is Choosing Models Based on Hype, Not True Benchmarks
AI Engineering / Model Selection / Benchmarks

When you say “this LLM is best” — best at what? Coding? Reasoning? Documents? Speed? Cost? Benchmarks are report cards for LLMs. SWE-bench checks: can it fix real GitHub bugs? Terminal-bench checks: can it work inside a real terminal? RealWorldQA checks: can it reason about practical situations? Here is every benchmark that exists, every model that matters, and the actual numbers.
Anubhav · Senior AI Research Engineer · April 2026

Pick your need, pick your benchmark, pick your model
Every entry below shows what benchmark to actually check — not what the model card claims.
Agentic coding — Real bug fixing. Multi-file patches, real repos. Check SWE-bench Verified / Pro. Best picks: Claude Opus 4.7 (87.6%) or GPT-5.5 (82.6%).
Terminal / DevOps — CLI automation. Docker, Linux, server debugging. Check Terminal-Bench 2.0. Best pick: GPT-5.5 (82.7%) — clear #1.
PhD reasoning — Expert science. Graduate-level problems. Check GPQA Diamond. Best picks: Gemini 3.1 Pro (94.1%) and Claude Opus 4.7 (94.2%).
Competition math — Olympiad-level. AIME, FrontierMath. Check AIME 2025 and FrontierMath. Best picks: Grok 4 (95%), o3, DeepSeek R1.
Frontier knowledge — Absolute hardest. Expert humans score 90%. Check Humanity’s Last Exam. Best picks: Claude Opus 4.7 (46.9%) and Gemini 3.1 Pro (44.7%).
Human preference — Real-world quality. 6M+ blind user votes. Check Chatbot Arena ELO. Best pick: Claude Opus 4.6 Thinking (1504 ELO, #1).
Production / API — Tool calling pipelines. Function call accuracy. Check BFCL and TAU-bench. Best picks: Claude Opus 4.6 / GPT-5.4.
Vision / Docs — Charts, PDFs, multimodal. Expert visual reasoning. Check MMMU and DocVQA. Best picks: Gemini 3.1 Pro and GPT-4o.
Budget / Self-host — Open-source frontier. Near-proprietary, free weights. Check SWE-bench and Open LLM Leaderboard. Best picks: MiniMax M2.5 (80.2%) and GLM-5 (77.8%).
“In production, the best model is the one that fits your use case — not the one with the highest number on a benchmark you didn’t choose carefully.”
Why this guide exists
Most benchmark articles show MMLU, HumanEval, and GSM8K — three benchmarks that are now fully saturated. All frontier models score within 2–3% of each other on those tests. That’s noise, not signal. This guide covers every benchmark category that still differentiates models, every major model family from every lab, and actual verified scores from independent evaluators — not model cards.
The saturation problem (read this first): MMLU (88–92% all frontier models), HumanEval (90–97%), GSM8K (95–99%), HellaSwag (95%+) — these no longer separate frontier models. If a model card only cites these four benchmarks, treat it as marketing, not evidence. Use GPQA Diamond, SWE-bench Verified/Pro, AIME, TAU-bench, Humanity’s Last Exam, and Arena ELO instead.
Coding and software engineering benchmarks
What actually separates models for engineers
SWE-bench Verified [new 2025–26] — Real-world bug fixing (gold standard). 500 human-verified GitHub issues. Model receives issue + full repo, must produce a working patch. Tests multi-file editing, repo navigation, real engineering — not DSA toy problems. The most-cited coding benchmark. Top scores: GPT-5.5 82.6%, Claude Opus 4.7 87.6% (though 4.7 used later scaffold), Claude Opus 4.6 80.8%, Sonnet 4.6 79.6%.
SWE-bench Pro [new 2025–26] — Harder, private codebases. 1,865 problems from 41 actively maintained repos with standardized scaffold. Much harder than Verified — top models drop from 80%+ to 20–64%. Claude Opus 4.7 64.3%, GPT-5.5 58.6%, Gemini 3.1 Pro 54.2%. More reliable than Verified because private repos resist memorization.
Terminal-Bench 2.0 [new 2025–26] — Real command-line workflows. Complex CLI workflows requiring planning, iteration, and tool coordination in a sandboxed terminal: Docker issues, server debugging, Linux operations, pipeline orchestration. GPT-5.5 82.7% (clear #1), Claude Opus 4.7 69.4%, Gemini 3.1 Pro 68.5%. If you build DevOps agents, this matters more than SWE-bench.
LiveCodeBench — Contamination-free coding. Competitive programming problems from LeetCode/Codeforces posted after model training cutoffs. Updated continuously. The only coding benchmark that is structurally resistant to data memorization. Best ongoing signal for genuine code reasoning.
Aider Polyglot — Multi-language code editing. Code edits across Python, JS, Java, C++, Go, Rust, TypeScript via chat interface. Measures real pair-programming accuracy across 7+ languages. Practical signal for teams not working exclusively in Python.
BigCodeBench — Practical library usage. 1,140 tasks requiring use of 139 libraries (pandas, numpy, requests, etc.). More realistic than HumanEval — you must know the ecosystem, not just algorithms. Tests whether a model can actually call APIs correctly.
SciCode [new 2025–26] — Scientific code generation. Writing code that solves real scientific problems: training ML models for non-standard tasks, recognizing shapes, classifying signals. Part of the AAII composite index. Tests research-grade programming, not production CRUD.
CRUXEval — Code understanding vs generation. Predict code output (CRUXEval-O) or predict input (CRUXEval-I) from a given function. Tests code comprehension — can the model actually understand what code does, not just write more of it.
HumanEval / HumanEval+ [saturated] — Function-level Python generation. 164 Python functions from docstrings. All frontier models score 90–97%. Fully saturated. HumanEval+ adds 80x more test cases and partially restores signal — use it over the original if you must.
MBPP / MBPP+ [saturated] — Basic Python programming. 974 crowd-sourced entry-level Python tasks. Also saturated for frontier models (all ~85–90%). Only useful for evaluating smaller models below the frontier.
Reasoning and knowledge benchmarks
From grade school to the absolute frontier
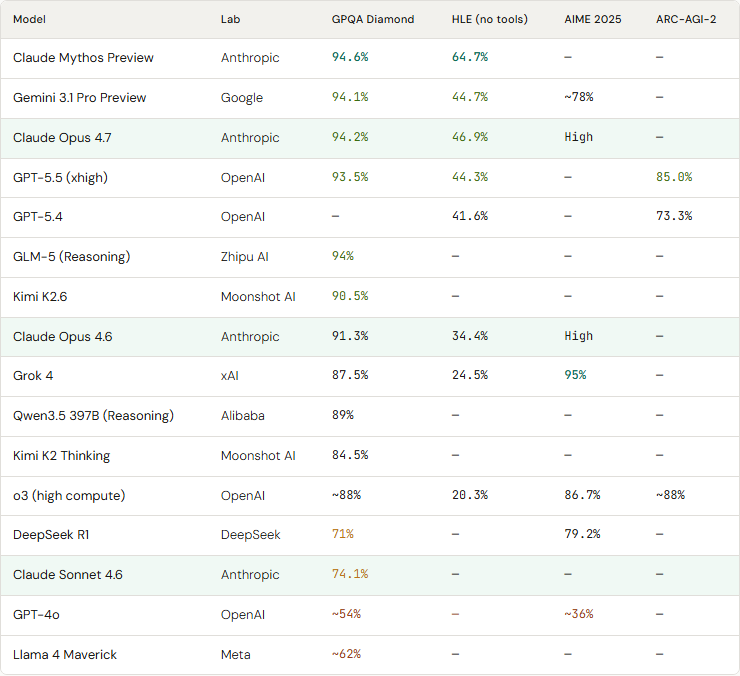
Humanity’s Last Exam (HLE) [new 2025–26] — The hardest academic benchmark. 2,500 questions across 100+ subjects, contributed by 1,000 subject-matter experts from 500+ institutions. Answers cannot be found via web search. Expert humans score ~90%. When launched in 2025, GPT-4o scored 2.7%. As of May 2026: Gemini 3.1 Pro 44.7%, Claude Opus 4.7 46.9%, GPT-5.5 44.3%, Grok 4 24.5%, o3 (high) 20.3%. Purpose-built to replace MMLU and GPQA as the frontier measure.
GPQA Diamond — PhD-level expert science reasoning. 198 graduate-level questions in physics, chemistry, biology. Domain PhD experts score ~65%. Designed to be “Google-proof.” Current top scores (independent evaluation, May 2026): Gemini 3.1 Pro Preview 94.1%, Claude Opus 4.7 94.2%, GPT-5.5 93.6%, Claude Opus 4.6 91.3%, Grok 4 87.5%, DeepSeek R1 71%, GPT-4o ~54%.
MMLU-Pro — Harder knowledge breadth. 10-choice questions (vs 4-choice MMLU) with harder problems. Reduces random guessing advantage. Scores run ~15–20% lower than standard MMLU. Provides meaningful separation where MMLU no longer can.
ARC-AGI-2 — Visual abstraction (fluid intelligence). Novel visual pattern puzzles designed to resist memorization. Tests generalization to never-before-seen patterns. GPT-5.5 85.0% (up from GPT-5.4’s 73.3% — largest single-generation jump on any benchmark). Human expert baseline ~95%. The best proxy we have for general reasoning ability.
GDPval [new 2025–26] — Real-world knowledge work. 44 knowledge work occupations from the top 9 US GDP industries: software developers, lawyers, nurses, mechanical engineers. Tests practical professional reasoning across domains people actually use AI for. GPT-5.5 84.9%, Claude Opus 4.7 80.3%, Gemini 3.1 Pro 67.3%.
BBH (Big-Bench Hard) — Diverse hard reasoning. 23 tasks where prior models historically failed: logical deduction, causal reasoning, temporal sequences. Multi-skill reasoning gauntlet that still differentiates mid-tier from frontier models.
BrowseComp [new 2025–26] — Web research and retrieval. Multi-hop web reasoning: finding specific facts requiring navigating multiple pages, synthesizing information, resolving ambiguity. Gemini 3.1 Pro 85.9%, GPT-5.5 84.4%, Kimi K2 Thinking 60.2%. Critical benchmark for research agent use cases.
AA-Omniscience [new 2025–26] — Factual accuracy and hallucination rate. Independent Artificial Analysis benchmark measuring both accuracy on factual questions AND hallucination rate (confidence on wrong answers). GPT-5.5: 57% accuracy but 86% hallucination rate. Claude Opus 4.7: 36% hallucination rate. Gemini 3.1 Pro: 50% hallucination rate. A critical safety signal often absent from model cards.
DROP — Arithmetic reasoning over text. Read a passage, answer questions requiring arithmetic, sorting, or counting. Combines reading comprehension with numerical reasoning. Still differentiates models on structured document analysis.
TruthfulQA / SimpleQA — Factual accuracy on common questions. Questions designed to elicit common misconceptions. SimpleQA (OpenAI) focuses on simple factual questions with unambiguous right/wrong answers. Direct hallucination rate measure for everyday knowledge.
MMLU [saturated] — Broad academic knowledge (57 subjects). 15,908 questions across 57 subjects. All frontier models score 88–92%. 2–3% differences are noise. Use MMLU-Pro or HLE instead for meaningful differentiation.
MuSR (Multi-Step Soft Reasoning) — Long narrative reasoning chains. 6–10 reasoning steps over complex narratives: murder mysteries, team allocation, object placement. Tests chain-of-thought quality on long-horizon problems without the mathematical structure of AIME.
Mathematics benchmarks
From word problems to research frontiers
AIME 2024 / 2025 — American Invitational Math Exam. 30 problems requiring deep mathematical reasoning. High-variance benchmark that still separates frontier models. May 2026 scores: Grok 4 95%, o3 (high) 86.7%, DeepSeek R1 79.2%, Gemini 3.1 Pro ~78%. GPT-4o only ~36% — a 60-point spread makes this highly informative.
MATH / MATH-500 — Competition math (AMC/AIME level). 12,500 problems spanning 7 subjects including number theory and combinatorics. MATH-500 is the curated 500-problem fast-eval subset. Top models now score 90–97%, so primarily useful for distinguishing mid-tier from frontier.
FrontierMath [new 2025–26] — Cutting-edge research-level mathematics. Problems from active mathematical research, contributed by professional mathematicians. Even experts find these hard. Models still score under 40% at best. GPT-5.5 Tier 4: 35.4%, Claude Opus 4.7: 22.9%, Gemini 3.1 Pro: 16.7%. The true frontier of mathematical AI evaluation.
OlympiadBench — International Math Olympiad level. IMO-difficulty problems requiring creative multi-step proofs. Harder than AIME, easier than FrontierMath. The middle ground for distinguishing top reasoning models from the field.
MGSM — Multilingual grade-school math. GSM8K translated to 10 languages. Tests whether math reasoning transfers across Spanish, Chinese, Japanese, Thai, Bengali. Still relevant for evaluating non-English reasoning quality.
GSM8K [saturated] — Grade-school word problems. 8,500 word problems. All frontier models score 95–99%. Fully saturated. Only useful for evaluating models below frontier level (7B-13B parameter range).
Agentic and tool use benchmarks

Multi-step real-world tasks
Long context benchmarks

What happens at 100K-1M tokens
Vision and multimodal benchmarks
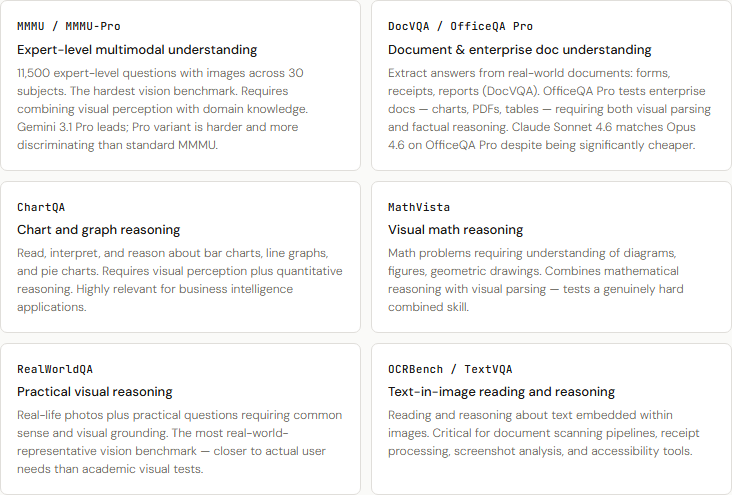
Seeing and reasoning together
Chat quality and instruction following
Does it actually listen to you
Chatbot Arena / LMArena — Human preference ELO (6M+ votes). Crowdsourced blind A/B voting — real users choose the better response without knowing which model is which. ELO-rated. The least gameable benchmark because users can’t be bribed. As of April 2026 overall: Claude Opus 4.6 Thinking #1 (ELO 1504). Coding leaderboard: Opus 4.6 (1549), Sonnet 4.6 (1523). Math: GPT-5.4 leads.
IFBench [new 2025–26] — Hard instruction following. Harder version of IFEval with more complex, nested constraints. Part of the AAII composite index. Tests precision compliance on complex multi-requirement instructions — not just simple format constraints.
IFEval — Strict format constraints. Verifiable format rules: “exactly 3 paragraphs,” “include keywords X, Y, Z,” “respond in JSON.” Tests whether a model follows explicit rules precisely — a surprisingly hard problem even for frontier models.
MT-Bench / Arena-Hard — Multi-turn conversation quality. 80 multi-turn questions judged by LLM-as-judge (MT-Bench), and the 500 hardest Arena queries (Arena-Hard). Tests quality across follow-up turns, not just opening responses — a model can look great on single-turn and fall apart on turn 3.
AlpacaEval 2.0 (LC) — Instruction following win rate. Model outputs vs GPT-4 reference. Length-Controlled variant corrects for verbosity bias — longer responses were artificially favored in the original. More honest signal for instruction quality without padding penalties.
WildBench — Real-world query diversity. 1,024 real user queries from the wild. Harder and more diverse than MT-Bench. Tests whether models handle the long tail of actual user needs — not curated evaluation prompts. Closer to what real users actually ask.
Safety and alignment benchmarks
The side of capability that doesn’t go on slides
WMDP (Weapons of Mass Destruction Proxy) — Dangerous knowledge refusal (lower = safer). Does the model refuse to assist with bioweapons, chemical weapons, cyber weapons? Lower score means safer — less dangerous knowledge leaked. Claude models consistently score lowest. Critical for enterprise compliance, especially in regulated industries.
CyberGym [new 2025–26] — Real cybersecurity challenges. CTF (Capture the Flag) challenges and real cyber range tasks. GPT-5.5 81.8%, Claude Opus 4.7 73.1%, Claude Mythos Preview 83.1%. Higher scores mean more capable on real offensive security tasks — important context for security teams deploying coding agents.
HarmBench — Jailbreak robustness. Red-team attacks across multiple attack categories. Attack Success Rate (ASR) — lower is better. Tests how robust a model is to known jailbreak techniques. Claude models consistently show lowest ASR.
XSTest — Over-refusal detection. Does the model refuse harmless requests? Safety without excessive restriction is the goal. Models that are both resistant to jailbreaks (HarmBench) and not overly cautious (XSTest) represent the best safety-utility balance.
CyberSecEval — Code-level security risks. Tests whether a model generates insecure code, assists with vulnerability exploitation, or produces code with security flaws. Critical for organizations deploying coding agents that write production code.
Complete model comparison: every major model, verified scores
Scores from independent evaluators (vals.ai, Artificial Analysis, BenchLM, SWE-rebench, Rootly SRE-skills-bench, LMArena) and official model cards. All data as of May 2026. “ — -” means not yet independently evaluated.
New in this edition vs standard benchmark articles: This table includes the GPT-5 family (GPT-5 through 5.5), Claude Opus 4.7, Grok 4, GLM-5, Kimi K2, Qwen3.5, and MiniMax M2 — models absent from most comparison articles that are now scoring at or near frontier level.
Coding and software engineering — full field

* Claude Opus 4.7 SWE-bench Verified score uses Claude Code scaffold. Scores vary by evaluation framework — always note the scaffold when comparing.
Reasoning and knowledge — full field
Agentic tasks and human preference

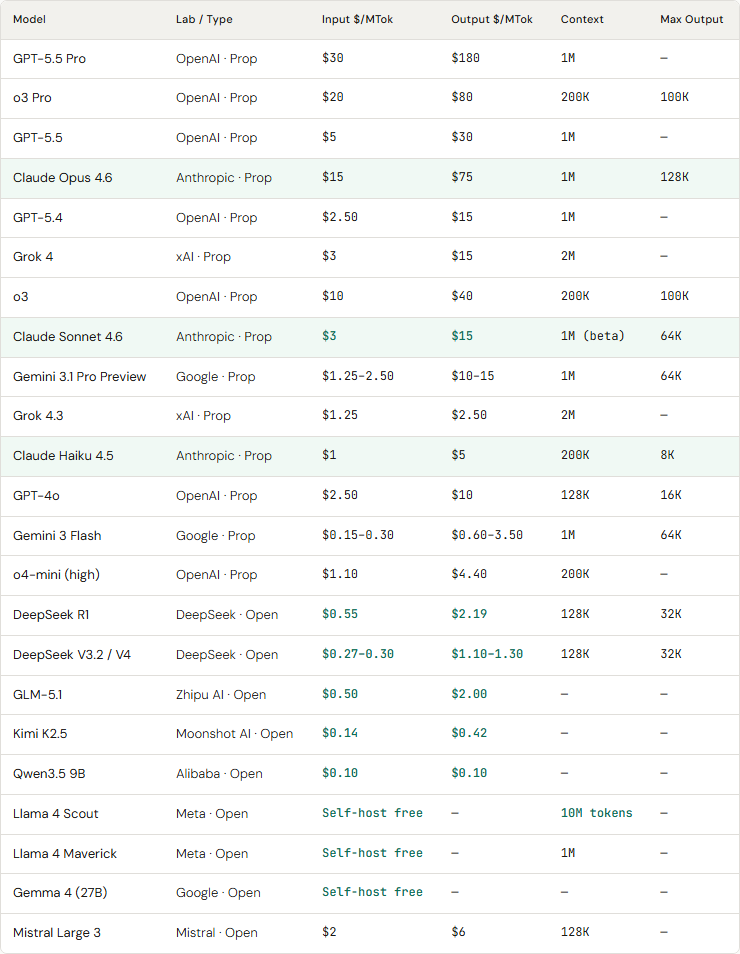
Complete pricing and context matrix
The benchmarks that still differentiate (use these)
Coding agent — SWE-bench Verified + Pro. If a model card claims coding excellence but doesn’t show SWE-bench Verified, ask why. Pro is harder and more honest. Both together give the full picture.
DevOps agent — Terminal-Bench 2.0. The only benchmark that tests real CLI workflows. If you build unattended terminal agents, this matters more than SWE-bench.
Expert reasoning — GPQA Diamond + HLE. GPQA is still the standard. HLE is the new frontier — if a model doesn’t report HLE, it likely doesn’t perform well on it.
Math — AIME 2025 + FrontierMath. 60-point spread on AIME across frontier models. FrontierMath is the true unsolved frontier — models still under 40%.
Agentic pipelines — TAU-bench + MCP Atlas. Real multi-step task completion. MCP Atlas is the new critical benchmark for teams using MCP-based tool pipelines.
Human preference — Chatbot Arena ELO. 6M+ blind votes. The hardest benchmark to game. A model that rises here organically is genuinely better in practice.
Long context — MRCR v2 (512K-1M tokens). The new discriminating long-context benchmark. Passing NIAH is necessary but not sufficient — MRCR v2 shows whether reasoning holds at scale.
Safety-critical — AA-Omniscience hallucination rate. GPT-5.5 has an 86% hallucination rate (confident wrong answers) despite high accuracy. Opus 4.7 is at 36%. For regulated domains, this gap is existential.
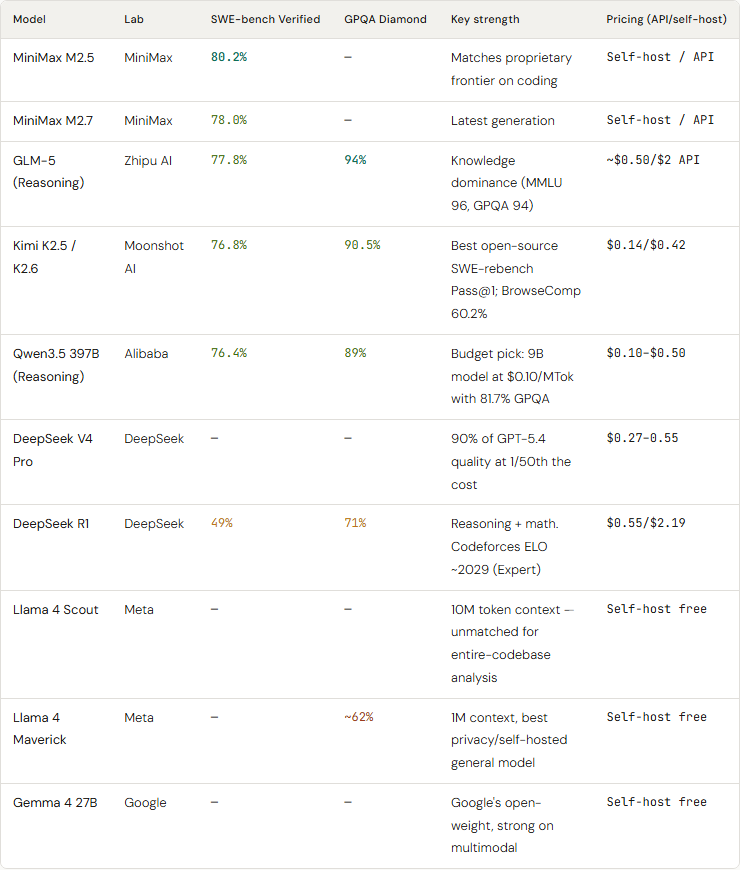
The open-source frontier: Chinese labs have caught up

The most underreported story of 2026: Chinese open-weight models now rival proprietary frontiers on coding benchmarks. This was not true in 2024.
MiniMax M2.5 (MiniMax) — SWE-bench Verified: 80.2% | GPQA Diamond: — — | Key strength: Matches proprietary frontier on coding | Pricing: Self-host / API
MiniMax M2.7 (MiniMax) — SWE-bench Verified: 78.0% | GPQA Diamond: — — | Key strength: Latest generation | Pricing: Self-host / API
GLM-5 (Reasoning) (Zhipu AI) — SWE-bench Verified: 77.8% | GPQA Diamond: 94% | Key strength: Knowledge dominance (MMLU 96, GPQA 94) | Pricing: ~$0.50/$2 API
Kimi K2.5 / K2.6 (Moonshot AI) — SWE-bench Verified: 76.8% | GPQA Diamond: 90.5% | Key strength: Best open-source SWE-rebench Pass@1; BrowseComp 60.2% | Pricing: $0.14/$0.42
Qwen3.5 397B (Reasoning) (Alibaba) — SWE-bench Verified: 76.4% | GPQA Diamond: 89% | Key strength: Budget pick: 9B model at $0.10/MTok with 81.7% GPQA | Pricing: $0.10-$0.50
DeepSeek V4 Pro (DeepSeek) — SWE-bench Verified: — — | GPQA Diamond: — — | Key strength: 90% of GPT-5.4 quality at 1/50th the cost | Pricing: $0.27–0.55
DeepSeek R1 (DeepSeek) — SWE-bench Verified: 49% | GPQA Diamond: 71% | Key strength: Reasoning + math. Codeforces ELO ~2029 (Expert) | Pricing: $0.55/$2.19
Llama 4 Scout (Meta) — SWE-bench Verified: — — | GPQA Diamond: — — | Key strength: 10M token context — unmatched for entire-codebase analysis | Pricing: Self-host free
Llama 4 Maverick (Meta) — SWE-bench Verified: — — | GPQA Diamond: ~62% | Key strength: 1M context, best privacy/self-hosted general model | Pricing: Self-host free
Gemma 4 27B (Google) — SWE-bench Verified: — — | GPQA Diamond: — — | Key strength: Google’s open-weight, strong on multimodal | Pricing: Self-host free
Where to verify live scores (bookmark these)
Benchmark scores change weekly. Always cross-reference a model card’s claims against independent trackers before making infrastructure decisions.
LMArena (Arena.ai) — Human preference ELO, 6M+ votes — https://lmarena.ai
SWE-bench.com — Real software engineering scores — https://www.swebench.com
Artificial Analysis — Speed, price, AAII intelligence index — https://artificialanalysis.ai
LLM Stats — 300+ models, GPQA + SWE composite — https://llm-stats.com
BenchLM.ai — 185+ benchmarks tracked per model — https://benchlm.ai
LiveBench.ai — Contamination-free, updated continuously — https://livebench.ai
SEAL / Scale AI — SWE-bench Pro, HLE, expert evals — https://labs.scale.com/leaderboard
BFCL (Berkeley) — Function calling accuracy leaderboard — https://gorilla.cs.berkeley.edu/leaderboard.html
Aider Leaderboard — Practical code editing across languages — https://aider.chat/docs/leaderboards/
Open LLM Leaderboard — Open-source model comparison (HF) — https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
SRE Skills Bench — Cloud infra, Kubernetes, IAM reasoning — https://sreskillsbench.com
HLE Leaderboard — Humanity’s Last Exam scores + pricing — https://pricepertoken.com/leaderboards/benchmark/hle
“Tell me in the comments: which benchmark do you rely on when choosing a model for your use case?”
Sources: Anthropic release announcements (Sonnet 4.6, Opus 4.6, Opus 4.7), OpenAI GPT-5.5 system card (April 23 2026), vals.ai SWE-bench tracker, BenchLM.ai (April 2026), Rootly SRE-skills-bench, Artificial Analysis Intelligence Index v4.0, LMArena Arena leaderboard, pricepertoken.com HLE tracker, IntuitionLabs HLE analysis, Vellum GPT-5.5 analysis, BuildFastWithAI open-source rankings, BenchLM open-source LLM guide, Clarifai Kimi/Qwen/GLM comparison.
*Benchmarks change weekly!.. This article is to give you what benchmarks exist — with models — how to compare and decide!
The Biggest Mistake Tech Companies Are Making With AI Is Choosing Models Based on Hype, Not True… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.