A structural guarantee for LLM classification output

The Problem
When you use an LLM for classification across many categories, it sometimes returns a label that was never in your input list. The output is directionally close but structurally wrong. A downstream system that expects exact category strings fails.
The standard workarounds do not fully solve this. Adding explicit prompt instructions (“respond only with labels from the provided list”) reduces errors but cannot eliminate them. Post-hoc filtering with string similarity adds latency and breaks when the model output drifts too far. Retry loops compound the problem. None of these give a deterministic guarantee because they all operate after the model has already generated a bad token.
The root cause: the model generates one token at a time with no built-in restriction on what it can emit. Every token in the vocabulary is always a candidate. Constrained decoding fixes this at the generation level by making invalid tokens literally impossible to sample.
How LLMs Generate Tokens
LLMs are autoregressive. At each step, the model reads the entire token sequence so far (prompt plus all previously generated tokens) and outputs a score for every token in its vocabulary. This score vector is called the logit vector.
A typical vocabulary has 32,000 to 100,000 tokens. At each step, the model produces a vector of that size: one float per token. These logits are converted to probabilities via softmax:

A sampling strategy then picks the next token. Greedy decoding picks the argmax. Temperature sampling scales the logits before softmax. Nucleus sampling (top-p) retains only the highest-probability mass. In every case, any token with a finite logit has a nonzero probability. There is no mechanism in the standard generation loop to restrict which tokens get picked.
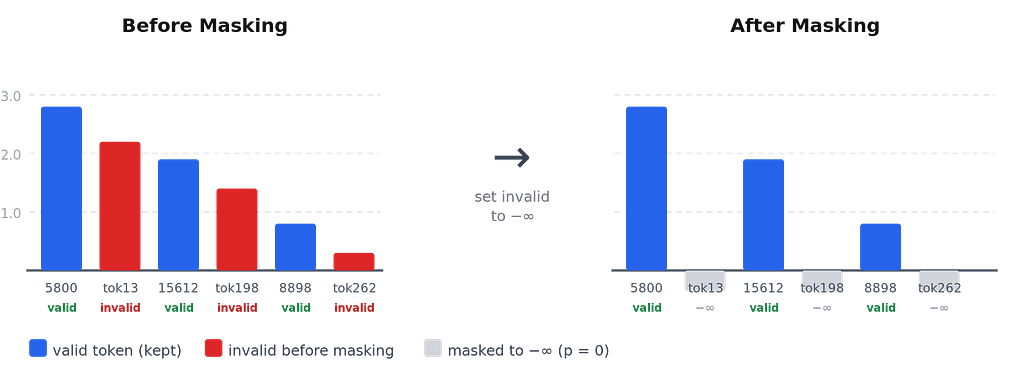
Why −∞ Makes Invalid Tokens Impossible
The softmax function maps any logit to a probability. For a token with logit set to −∞ (covered in depth in this earlier post on attention masking):

This is exact, not approximate. The remaining valid tokens are renormalized to sum to 1. The sampling step, regardless of strategy (greedy, temperature, top-p, top-k), cannot pick a token with probability 0. This is the guarantee.
In code, the intervention is a single line inserted before the sampling step:
logits[~valid_token_mask] = float('-inf')The question is: at each decoding step, which tokens are valid? This depends on what the model has already generated. If the model has emitted “ Tech” as its first label token, the only valid next token is “nology” (to complete “Technology”). All 50,000+ other tokens must be masked. The trie data structure tracks this exactly.
The Trie: Encoding All Valid Sequences
A trie (prefix tree) stores a set of strings organized by shared prefixes. Each node represents one token. Each path from the root to an end node represents one complete valid label. Looking up which tokens are valid after a given prefix takes O(k) time, where k is the number of tokens already generated for the current label.
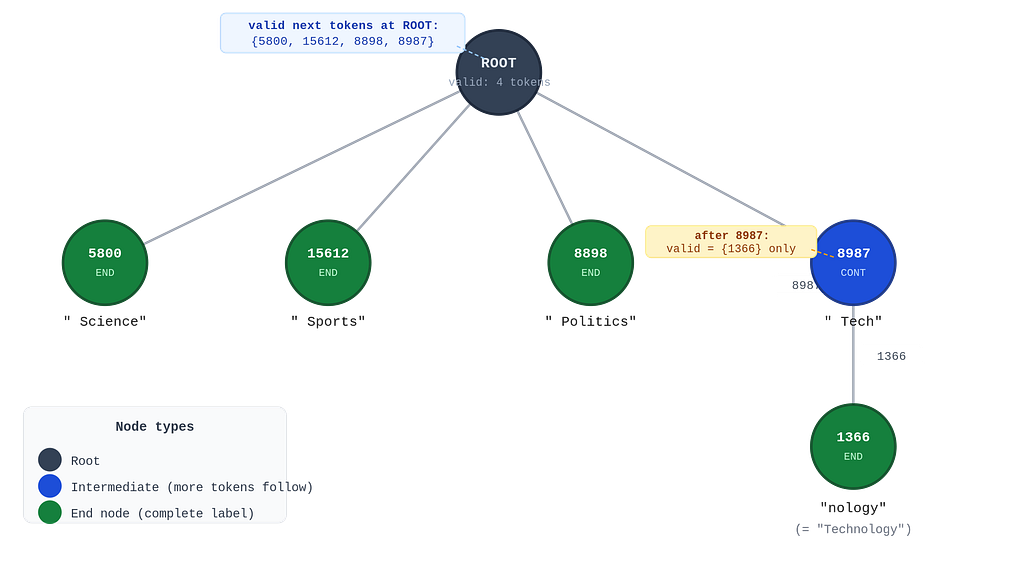
The diagram below shows a trie built from four classification labels: “Science”, “Sports”, “Politics”, and “Technology”. Three labels happen to tokenize to a single token each. “Technology” tokenizes to two tokens: “ Tech” (ID 8987) and “nology” (ID 1366). The trie encodes both paths.
Traversal at decode time
At the start of label generation, the model is at the root node. The valid next tokens are the root’s children: {5800, 15612, 8898, 8987}. All other tokens get −∞.
Say the model samples 8987 (“ Tech”). The trie pointer advances to that node. Now the children are {1366} only. Every other token gets −∞. The model has exactly one choice: 1366 (“nology”). After emitting 1366, the pointer reaches an end node. The only valid next token is EOS. Generation of this label terminates.
If instead the model had sampled 5800 (“ Science”), that node is already an end node. EOS is the only next valid token. The label is complete in one step.
Tokenization-Aware Tries: The Critical Detail
BPE tokenizers are context-sensitive. The same word gets a different token ID depending on whether it appears at the start of a string or in the middle of one (after other tokens). When the model generates a label, it is always generating a continuation of the prompt. So “ Sports” (with a leading space) is the correct form to tokenize, not “Sports”.
Tokenizing without the leading space gives a different token ID and your trie will be built incorrectly. The model will emit “ Sports” (with space) but your trie will only contain “Sports” (without space), so the lookup fails.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
# Wrong: tokenizes as sentence-start, gives a different token ID
tokenizer.encode("Sports", add_special_tokens=False)
# → [51660] (wrong ID for a continuation)
# Right: tokenizes as continuation (leading space = continuation marker)
tokenizer.encode(" Sports", add_special_tokens=False)
# → [22470] (this is what the model will actually emit)
Always build your trie by tokenizing " "+ label with add_special_tokens=False. This matches how the model will emit these tokens when generating a label that follows the prompt.
Watch out: Qwen2.5 uses tiktoken (the same tokenizer family as GPT-4). Unlike SentencePiece models, tiktoken does not use a ▁ prefix character. However, whitespace is still baked into token boundaries. Always verify by decoding the token IDs back to strings and confirming the round-trip reconstructs the original label exactly. If tokenizer.decode(token_ids) != ""+ label, your trie has a tokenization bug.
Building the Constrained Decoder
Trie implementation
class TrieNode:
def __init__(self):
self.children = {} # token_id → TrieNode
self.is_end = False
class ConstrainedTrie:
def __init__(self):
self.root = TrieNode()
def insert(self, token_ids):
node = self.root
for tid in token_ids:
if tid not in node.children:
node.children[tid] = TrieNode()
node = node.children[tid]
node.is_end = True
def get_valid_next_tokens(self, prefix):
"""Which tokens can the model emit next, given what it has emitted so far."""
node = self.root
for tid in prefix:
if tid not in node.children:
return set()
node = node.children[tid]
return set(node.children.keys())
def is_complete(self, prefix):
"""True if prefix exactly spells out one of the inserted labels."""
node = self.root
for tid in prefix:
if tid not in node.children:
return False
node = node.children[tid]
return node.is_end
def all_labels(self):
"""Return every stored label as a tuple of token IDs."""
results = []
def walk(node, path):
if node.is_end:
results.append(tuple(path))
for tid, child in node.children.items():
walk(child, path + [tid])
walk(self.root, [])
return results
Building the trie from labels
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
labels = ["Science", "Sports", "Politics", "Technology"]
trie = ConstrainedTrie()
for label in labels:
# always tokenize as continuation, not sentence start
token_ids = tokenizer.encode(" " + label, add_special_tokens=False)
trie.insert(token_ids)
# rebuild this trie every time the label set changes
The logits processor
HuggingFace generation accepts a LogitsProcessor that intercepts the logit vector at each step. The processor below uses the trie to mask all invalid tokens:
import torch
from transformers import LogitsProcessor, LogitsProcessorList, AutoModelForCausalLM
class TrieLogitsProcessor(LogitsProcessor):
def __init__(self, trie, prompt_length, eos_token_id):
self.trie = trie
self.prompt_length = prompt_length
self.eos = eos_token_id
def __call__(self, input_ids, scores):
# what has the model generated so far (after the prompt)?
generated = input_ids[0, self.prompt_length:].tolist()
# ask the trie: which tokens are valid at this point?
valid = self.trie.get_valid_next_tokens(generated)
# if we've reached a complete label, the model can also stop
if self.trie.is_complete(generated):
valid.add(self.eos)
# set every other token to -inf so it cannot be sampled
masked = torch.full_like(scores, float('-inf'))
for tid in valid:
masked[0, tid] = scores[0, tid]
return masked
# --- plug into HuggingFace generation ---
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
prompt = "Classify the text into one category.\nText: 'The match ended in a penalty shootout.'\nCategory:"
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
processor = TrieLogitsProcessor(trie, input_ids.shape[1], tokenizer.eos_token_id)
output = model.generate(
input_ids,
logits_processor=LogitsProcessorList([processor]),
max_new_tokens=16,
)
label = tokenizer.decode(output[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
print(label) # guaranteed to be one of: Science, Sports, Politics, Technology
The model can use any sampling strategy (greedy, temperature, top-p) and the output will still be a valid label. The constraint is applied before sampling, so it is independent of the sampling method.
Full runnable example: https://github.com/SachinKalsi/constrained-decoding/blob/main/examples/single_label.py
Multi-label and Hierarchical Taxonomies
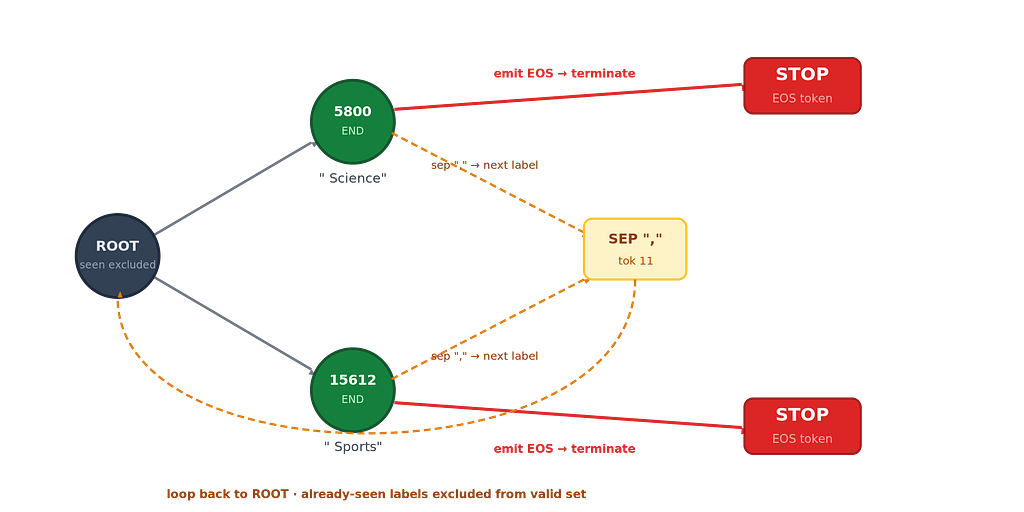
For multi-label classification (one input, multiple output labels), the trie needs two extensions. First, after any end node the model can emit EOS (stop immediately) or a separator token (continue with another label). The model picks whichever has higher probability, it is not forced to keep going. Second, if the model does pick the separator, already-emitted labels must be excluded at ROOT so the next pick cannot repeat what was already chosen.
Preventing repeated labels
At every ROOT visit, the processor groups all trie labels by their first token, then removes a first token only when every label starting with it has already been seen. This matters for hierarchical taxonomies: picking “Technology” should not block “Technology/AI” since they share a first token. Only once both are emitted does that first token disappear from valid. When no valid tokens remain, EOS is added so generation can terminate.
class MultiLabelTrieLogitsProcessor(LogitsProcessor):
def __init__(self, trie, prompt_length, eos_token_id, sep_token_ids):
self.trie = trie
self.prompt_length = prompt_length
self.eos = eos_token_id
self.sep = sep_token_ids
# precompute once: first token -> all labels that start with it
self._by_first = {}
for label in trie.all_labels():
self._by_first.setdefault(label[0], []).append(label)
def _parse(self, tokens):
"""Split token list on separator → (seen labels, current partial label)."""
seen, current, sep_len = [], [], len(self.sep)
i = 0
while i < len(tokens):
if tokens[i : i + sep_len] == self.sep:
if current:
seen.append(tuple(current))
current, i = [], i + sep_len
else:
current.append(tokens[i])
i += 1
return set(seen), current
def __call__(self, input_ids, scores):
generated = input_ids[0, self.prompt_length:].tolist()
seen, current = self._parse(generated)
valid = self.trie.get_valid_next_tokens(current)
if self.trie.is_complete(current):
valid.add(self.eos) # model can stop ...
valid.update(self.sep) # ... or continue with a separator
# back at root: remove a first token only when every label that
# starts with it has been seen (precomputed in __init__).
# this keeps sibling labels available until they too are emitted.
if not current and seen:
for first_tok, group in self._by_first.items():
if all(lbl in seen for lbl in group):
valid.discard(first_tok)
if not valid:
valid.add(self.eos) # safety: no new labels available
masked = torch.full_like(scores, float('-inf'))
for tid in valid:
masked[0, tid] = scores[0, tid]
return masked
Full implementation with docstrings: https://github.com/sachinkalsi/constrained-decoding/blob/main/constrained_decoding/processors.py
Hierarchical taxonomies: For hierarchical labels like “Technology > AI > NLP”, treat the full path string as the label and tokenize it as-is. The trie will encode the shared prefix “Technology > AI” once, with branches for each sub-category below it. No structural change to the trie is needed
The Correctness Proof
The 100% adherence guarantee from trie-based constrained decoding is structural, not empirical. You do not need to run 10,000 test cases and count errors. The guarantee follows from two invariants that hold by construction:
1. Forward invariant: At every decoding step t, the only tokens the model can emit are children of the current trie node. By definition, each child corresponds to a valid continuation of some label in the taxonomy. So every token the model emits is a valid prefix extension.
2. Termination invariant: The model can only stop generating (emit EOS) when the trie pointer is at an end node. End nodes are inserted only when a complete label is added to the trie. So every sequence the model can complete corresponds to exactly one label in the taxonomy.
If both invariants hold, the reachable outputs under constrained decoding are exactly the set of tokenized taxonomy labels, no more and no less. These invariants hold if and only if the trie is built correctly from the complete label set. You verify this with a single traversal: enumerate all root-to-leaf paths in the trie and check they match your label list. That check, done once at build time, is the entire proof. No inference needed.
This guarantee is independent of model weights, sampling temperature, top-p setting, or any other generation parameter.
Edge Cases to Handle
Trie rebuild on taxonomy changes. The trie is a static snapshot of your label set. Any time labels are added, removed, or renamed, rebuild it from scratch. This takes milliseconds for typical taxonomies (hundreds to thousands of labels) and should run at service startup or when the taxonomy version changes.
Low confidence on valid tokens. After masking, probability mass concentrates on a smaller set. If the model has very low confidence across all valid tokens, it will still pick one, but it may pick the wrong one. The fix is fine-tuning, not changing the constraint logic.
Extremely long labels. Labels that tokenize to many tokens create long constrained corridors where the model has very few valid choices at each intermediate step. This does not hurt correctness but can degrade quality. Fine-tuning helps here too.
Limitations
Requires logit access. This technique only works with models where you control the generation loop and can intercept logits at each step. You cannot apply it to API-only services like OpenAI, Anthropic, or Gemini. Those services do support structured output (JSON mode, tool calling), which is itself implemented via constrained decoding on their end, but you do not get direct control over the trie.
Probability redistribution. Masking removes tokens and the remaining probability mass gets renormalized. On inputs where the model genuinely does not know which category applies, the masked distribution may assign highest probability to a label just because competing labels were masked. The output is structurally valid but semantically wrong.
No substitute for model quality. The trie enforces output structure. It says nothing about whether the chosen label is correct. A weak model with constrained decoding gives you structurally correct wrong answers. Fine-tuning and constrained decoding are complementary, not alternatives.
Beyond Classification
The same mechanism generalizes to any situation where the output must conform to a grammar or a fixed schema. For JSON output, the trie (or a more general finite-state machine) encodes valid JSON token sequences. For SQL generation, a grammar-constrained decoder ensures the output is always parseable SQL. For agentic systems, constrained decoding prevents the model from hallucinating action names that do not exist in the tool registry.
In all these cases, the core idea is identical: at each decoding step, compute the set of tokens that are valid continuations of the current partial output, mask everything else to −∞, and let the model sample from the restricted distribution.
Conclusion
Constrained decoding via trie-based logit masking gives a structural guarantee that LLM output will always be one of your valid taxonomy labels. The guarantee does not come from repeated testing or probabilistic reasoning. It comes from the fact that invalid tokens have exactly zero probability under softmax when their logit is −∞, and the trie ensures only valid continuations ever get finite logits.
Rebuild the trie when your labels change. Fine-tune your model to improve accuracy. Use constrained decoding to eliminate structural errors in production.
If you are working with open-weight models and need deterministic output structure, constrained decoding is the right tool. It does not require changing the model or the prompt beyond what you already have. The only addition is the logits processor and the trie built from your label set.
Constrained Decoding: Forcing LLMs to Respect Your Taxonomy was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.