Moving beyond monolithic LLMs: A 3B-parameter hierarchical system that outperforms generalists through selective delegation.
“The only true wisdom is in knowing you know nothing.” — Socrates
The biggest models in AI today are optimized as broad generalists — hundreds of billions of parameters trained on trillions of tokens, compressing the entire internet into one monolithic brain. This approach works remarkably well on average, but it blurs the boundary between knowing and guessing. When these models reach the edge of their knowledge, they don’t stop. They hallucinate with the same confidence they use for things they actually know.
What if the alternative isn’t a bigger model, but a wiser architecture?
This is the fourth paper in my Progressive Cognitive Architecture series. The first showed that progressive training produces models with metacognition — the ability to know what they don’t know. The second introduced dream pruning, where SVD compression improves rather than degrades model performance. The third demonstrated continuous learning across domains without catastrophic forgetting.
The results presented here are preliminary but encouraging. This paper explores whether these techniques can be combined into a single system: the Socratic Model — a lightweight generalist that doesn’t try to know everything, but knows who to ask. The architecture works, the routing is accurate, and the system outperforms a monolithic baseline — though significant limitations remain, particularly in logic routing.
From cognitive maturation to delegation

In Paper 3, something unexpected happened. After learning logic, the math-trained model didn’t just gain new knowledge — it changed its cognitive style. It became more autonomous, less willing to delegate to a calculator, more confident in its own reasoning. I called this “cognitive maturation.”
But maturation has a flip side. A model that reasons about everything internally — even when a specialist tool or a specialist model would do better — is overconfident in a different way. The mature response isn’t “always delegate” or “never delegate.” It’s selective delegation: reason when you can, ask for help when you should.
This paper tests whether that selective delegation can extend beyond tools to other models. Instead of routing to a calculator, the system routes to a specialist that has deeper expertise in a specific domain.
The standard approach in AI avoids this entirely by scaling up: make one model bigger until it handles everything. This works remarkably well, but it has practical constraints. Cost grows superlinearly with parameters. Knowledge spreads thin across domains. And crucially, a monolithic model has no built-in mechanism for recognizing when it’s outside its competence.
Humans solved this problem differently. We don’t train generalist humans who know everything. We train specialists coordinated by generalists who know enough about each domain to ask the right questions and validate the answers. Socrates demonstrated this 2,400 years ago: he claimed to know nothing, yet was called the wisest man in Athens. His method was asking the right questions to the right people — and knowing when the answers didn’t make sense.
Architecture: the Socratic system
Our system has three components:

The Router is a 1.5B model trained with progressive cognitive architecture and dream pruning. It has broad intuition across domains — magnitude sense, logical pattern recognition — but no deep expertise. Its job is threefold: classify the query (math? logic? both? general?), delegate to the right specialist, and validate the response.
The Math Expert is a 1.5B Dream LoRA specialized in arithmetic. It solves what it can internally, and delegates to a deterministic calculator when expressions are too complex. Two levels of delegation: router → expert → tool.
The Logic Expert is a 1.5B model specialized in boolean operations, conditional reasoning, compound logic, and quantifiers. It reasons entirely internally — there is no “logic calculator” to delegate to.
The General path handles queries that don’t fit math or logic — the router answers directly from its own broad knowledge.
Total system: 4.5B parameters on disk, but only 3B in memory at any time — the router plus one specialist. The inactive specialist costs zero compute and zero memory. The effective footprint equals a single 3B model.
Training: every model knows its role
This is the critical difference from previous multi-model architectures. Each component is trained to know its role in the system:
The specialists are trained with the full progressive pipeline: learn the domain → dream pruning (SVD consolidation) → learn when to delegate (math expert → calculator; logic expert → internal reasoning) → orchestrate. They aren’t generic models repurposed as specialists — they’re models that have developed expertise through the same cognitive phases a human student would follow.
The router is trained on a classification + delegation dataset: given a query, output the correct routing decision (math/logic/both/general) and formulate the query for the specialist. It’s trained to recognize domains using the broad intuition that dream pruning preserves — the same magnitude sense and pattern recognition that made the Dream LoRA models successful in Papers 2 and 3.
A previous experiment with generic models (untrained for their roles) showed no advantage over a single model. The progressive training is not optional — it’s what makes the architecture work.
Related approaches
The Socratic Model sits at the intersection of several established research lines, but differs from each in important ways.
Mixture of Experts (MoE) architectures like Mixtral (Jiang et al., 2024) and GShard (Lepikhin et al., 2021) route tokens to specialized sub-networks within a single model. The routing happens at the layer level — different tokens activate different feed-forward blocks. The Socratic Model routes at the model level — entire queries go to independent specialist models. This makes the specialists independently trainable, deployable, and replaceable, but introduces inter-model communication overhead that MoE avoids.
Tool-augmented LLMs like Toolformer (Schick et al., 2023) and ART (Paranjape et al., 2023) teach models to call external tools (calculators, search engines, APIs). The Socratic system extends this principle: instead of delegating to deterministic tools only, the router delegates to other trained models — and the math specialist itself delegates further to a calculator. This creates a hierarchy of delegation that tool-use frameworks don’t address.
Multi-agent systems like AutoGen (Wu et al., 2023) and CrewAI orchestrate multiple LLM instances for complex tasks. These typically use large general-purpose models (GPT-4, Claude) in different roles. The Socratic approach is fundamentally different: it uses small, purpose-trained specialists where the training itself — progressive phases, dream pruning — is what creates the specialization. The agents aren’t generic models with different prompts; they’re models with different learned competencies.
Results
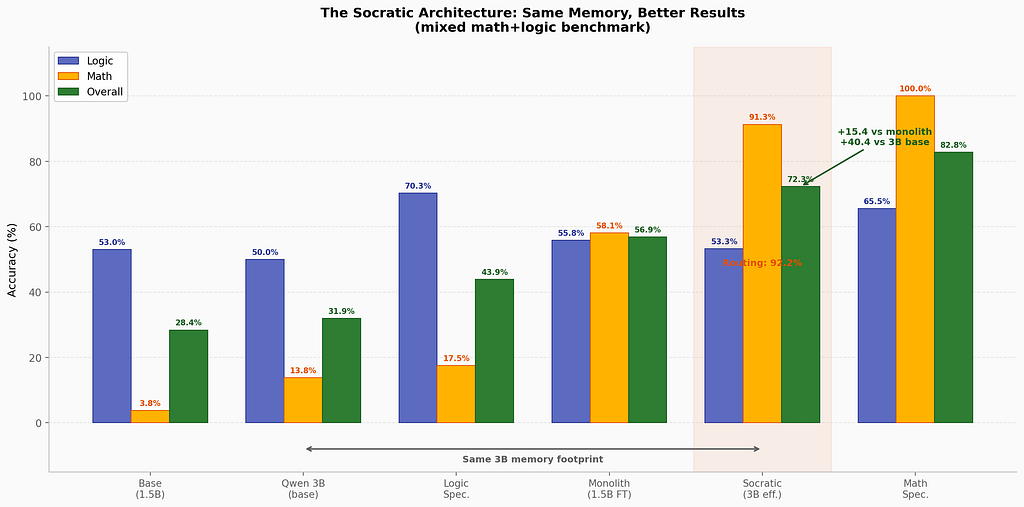
Methodology: 2 seeds (42, 43) for specialists and monolith; 1 seed (42, n=20) for the router system and 3B baseline. Router results are preliminary but consistent with prior smoke tests.
Experimental protocol: The benchmark consists of 20 mixed queries per seed, evenly split between math and logic domains. Math tasks include exact arithmetic, magnitude estimation, adversarial expressions, and delegation decisions. Logic tasks include boolean evaluation, conditional reasoning, negation, and compound statements. The router classifies each query into one of four categories (math / logic / both / general) using a trained classification head; routing accuracy is measured against ground-truth labels. The overall composite score is computed as the unweighted mean of math_composite and logic_composite, each of which aggregates its sub-task scores. Specialist and monolith results (2 seeds) show low inter-seed variance (< 3% on all composites); the single router seed is a limitation acknowledged below.
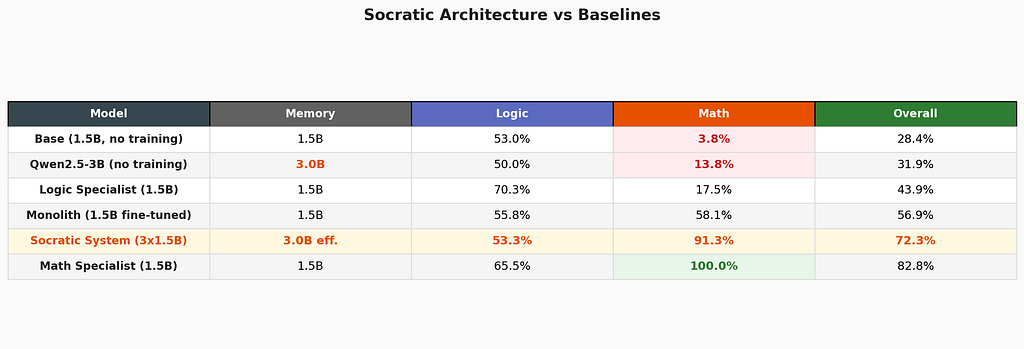
The memory framing: 3B effective, not 4.5B.
A key insight about this architecture: the three models are never in memory simultaneously. The router (1.5B) is always resident. One specialist (1.5B) is loaded on demand. The other sits on disk, ready to swap in. The actual memory footprint is 3B — identical to running a single Qwen2.5–3B.
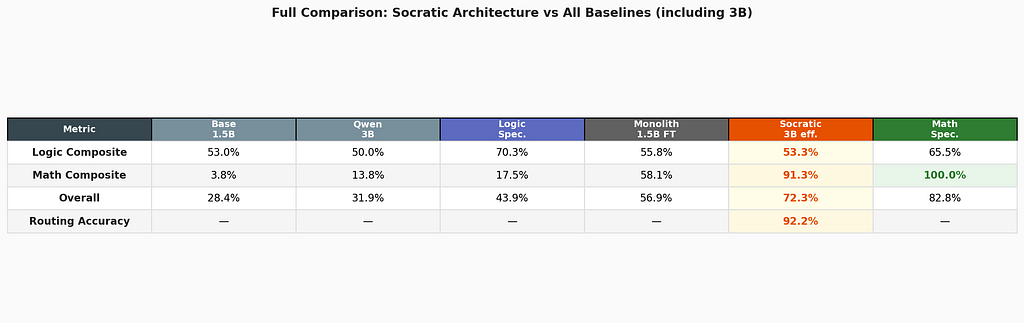
With equal memory budget, the Socratic system scores 72.3% where the untrained 3B scores 31.9%. But the fairest comparison is against the fine-tuned 1.5B monolith — a model that received the same training data. There, the Socratic system leads by 15.4 points: 72.3% vs 56.9%.
Given a 3B memory budget, a practitioner faces a choice: run a single generalist, or run a Socratic system with a 1.5B router and swappable 1.5B specialists. The architectural overhead of routing is more than compensated by specialist expertise.
The Socratic system outperforms the fine-tuned monolith by 15.4 points.
Routing accuracy: 92.2% — the model knows what it doesn’t know.

The router correctly classifies math vs logic vs both vs general 92.2% of the time. This is arguably the most important number in the study — more important than any accuracy score — because it measures metacognition at the system level. The router doesn’t solve problems; it recognizes what kind of problem it’s looking at and who should solve it.
This connects directly to Papers 1–3. Progressive training taught the model metacognition (knowing its own limits). Dream pruning preserved and refined it. Continuous learning extended it across domains. Now that same metacognitive capacity powers the routing decisions. The router’s 92% accuracy isn’t a separate skill — it’s the same “I know what I don’t know” capability, applied to delegation.
Math delegation is near-perfect.
The Socratic system achieves 91.3% on math — approaching the math specialist’s standalone 100%. The pipeline works: router identifies math → math expert solves or delegates to calculator → result returns. The two-level delegation (router → specialist → tool) functions as designed.
Logic routing reveals a communication problem — not an intelligence one.
The Socratic system scores 53.3% on logic — below the logic specialist’s standalone 70.3% and roughly equal to the base model. Specifically, negation tasks (0.0%) and compound logic (21.7%) fail in the routed context, even though the logic specialist handles them well in isolation.
This is the most instructive failure in the study. The logic specialist has the capability — it scores 70.3% when queried directly. The router knows it’s a logic query — routing accuracy is 92.2%. The breakdown happens in between: how the router formulates the query for the specialist.
This mirrors a real phenomenon in human organizations. A manager who correctly identifies that a problem needs a lawyer (routing) can still fail if they describe the problem poorly (query formulation). The specialist’s answer is only as good as the question they receive.
In Paper 3, I observed “cognitive maturation” — the model learning to reason more autonomously after training on logic. Here, I’m seeing the complementary challenge: learning to communicate with specialists requires a different kind of training than learning to be a specialist. The router needs not just domain classification ability, but domain-specific query formulation — knowing how to ask a logic question in a way the logic specialist can process.
This is solvable with better router training data, but it reveals something deeper: delegation is a skill, not just a routing decision. Effective delegation requires understanding enough about the specialist’s domain to formulate a good query — which is exactly what Socrates did. He didn’t just ask anyone any question. He asked the right question to the right person.
What the specialists reveal
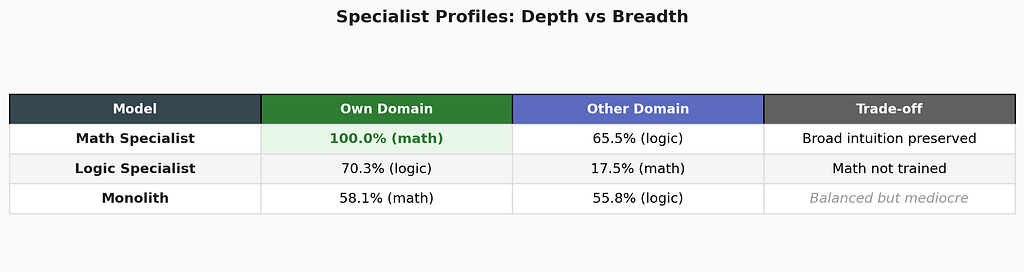
The specialist results are independently interesting, and they echo a theme from Paper 3 — one commenter described the challenge as a “reconstruction problem,” not just a memory problem.
Math Specialist at 100% — perfect on math composite across both seeds. This is the Dream LoRA from Paper 2 combined with a calculator tool. On its domain, it is unbeatable by any model size — a 70B generalist cannot score higher than 100%.
Logic Specialist at 70.3% — strong on boolean (90.7%), conditional (87.3%), compound (91.3%) operations. The progressive training works for logic as it did for math.
Specialists have trade-offs, and the trade-offs are revealing. The math specialist retains 65.5% logic (broad intuition preserved by dream pruning). The logic specialist drops to 17.5% math (expected — it was never trained on math). The monolith sits at 55–58% on both, never excelling at either.
This is the reconstruction problem in miniature: each specialist has reconstructed a coherent internal representation optimized for its domain. The math specialist’s 65.5% logic score shows that dream pruning preserves general reasoning even during specialization — the SVD compression keeps the broad structure while sharpening domain-specific directions. The logic specialist’s 17.5% math score shows what happens without that protection: capabilities that weren’t trained are lost.
The pattern in this benchmark is clear: specialization plus routing outperforms generalization on the tasks measured. A specialist that scores 100% on its domain, combined with a router that sends it the right queries, produces a system that outperforms a generalist that scores 58% on everything — at least for well-separated domains with accurate routing.
What this means
1. In this setting, architecture outperforms a larger untuned baseline at comparable active memory. With the same 3B memory footprint, the Socratic system (72.3%) more than doubles the untrained 3B base (31.9%) and outperforms the fine-tuned 1.5B monolith by 15.4 points (72.3% vs 56.9%). The comparison with the untuned 3B is not entirely fair — the Socratic system benefits from task-specific training — but it establishes that architectural organization can matter more than raw parameter count under constrained memory budgets.
2. Role-aware training is essential. The previous experiment with generic models as specialists showed no advantage. Progressive training — where each model develops expertise through cognitive phases and dream pruning — is what makes the architecture viable. The specialists aren’t repurposed generalists; they’re trained experts.
3. The routing bottleneck is communication, not classification. At 92.2% routing accuracy, the system knows where to send queries. The remaining weakness is how queries are formulated for specialists — particularly for complex multi-step reasoning. This is a training data problem, not an architectural one.
4. Two-level delegation works. Router → specialist → tool is a viable three-tier architecture. The math expert doesn’t just answer — it decides whether to compute internally or call a calculator. This means the Socratic system has heterogeneous delegation depth: math queries get two levels of routing, logic queries get one, general queries get zero. The system adapts its strategy to the domain.
5. The full cognitive arc is visible. Across all four papers, the model’s relationship with delegation has evolved: from learning to delegate to tools (Paper 1), to preserving that ability through compression (Paper 2), to developing autonomous judgment about when to delegate (Paper 3’s cognitive maturation), to now delegating selectively to specialized peers. This trajectory — from dependence on tools, through autonomy, to collaborative intelligence — mirrors human cognitive development more closely than any single benchmark result does.
6. In this benchmark, the monolith does not lead on any measured dimension. At 56.9% overall, the monolithic fine-tuned model is worse than the math specialist on math, worse than the logic specialist on logic, and worse than the Socratic system overall. This doesn’t mean monolithic training is always inferior — a monolith fine-tuned on more data or at larger scale could close the gap. But it suggests that for constrained parameter budgets, specialization with routing is a more efficient use of capacity than generalization.
Limitations
The 7B comparison remains open. The 3B base comparison establishes that the Socratic system dominates at equal memory. Whether it can match a fine-tuned 7B — which would have both more parameters and more training capacity — is the next question. A fine-tuned 3B comparison would also strengthen the argument, isolating the effect of architecture from training.
Router evaluation is preliminary. One seed (n=20) for the Socratic system is informative but not definitive. The 2-seed specialist results are stable; the router needs additional runs to confirm.
Logic routing is lossy. The 53.3% logic score in the Socratic system, compared to 70.3% for the logic specialist alone, reveals a ~17-point communication loss. This is the primary engineering challenge for the next iteration.
Two domains is still narrow. Math and logic are the first two specialists. The architecture’s promise — arbitrary domains, arbitrary specialists — remains theoretical until tested with 3+ domains, including unrelated ones (e.g., coding, natural language understanding).
Cost analysis is incomplete. While 3×1.5B is cheaper than 1×7B for training, the inference cost of routing (one extra model call per query) hasn’t been benchmarked. For latency-sensitive applications, the routing overhead matters.
The road ahead
Fix logic communication. The immediate priority. Better router training data for complex logical queries — specifically, multi-step transformations and negation — should close the 17-point gap between routed and direct specialist performance.
The 7B benchmark. Running Qwen2.5–7B on the same eval framework will establish whether 3×1.5B can compete with 1×7B. If it can, the architecture becomes relevant for production deployment.
Add a third specialist. Coding is the natural next domain. A code specialist trained with dream pruning, routed by the same orchestrator, would test whether the architecture scales beyond two domains. The router would learn three-way classification, and multi-domain queries (e.g., “write a function that implements this logical rule for these calculations”) would test true compositionality.
Adaptive routing. Currently, the router makes a single classification decision. A more sophisticated system would route iteratively: send to math specialist, examine response, decide if logic specialist is also needed, combine results. This would handle “both?” queries more naturally.
Benchmark against MoE. Mixture of Experts architectures (like Mixtral) use a similar principle — route to specialized subnetworks. The key difference is that MoE routes at the layer level within one model, while the Socratic Model routes at the model level across independent specialists. A direct comparison would clarify the trade-offs.
The thesis, complete

Four papers. One trajectory. Not about making models bigger, but about making them wiser.
Paper 1: A small model can learn what it doesn’t know. Paper 2: Dream pruning teaches it to compress without losing. Paper 3: Sleep cycles let it accumulate knowledge across domains — and change how it thinks. Paper 4: It learns to delegate to those who know better.
One commenter on Paper 3 observed that the real challenge isn’t retention but reconstruction — integrating new knowledge without distorting what’s already there. That insight runs through all four papers. Progressive training reconstructs learning as phases. Dream pruning reconstructs representations through compression. Continuous learning reconstructs cognitive style as domains accumulate. And the Socratic architecture reconstructs the very notion of “one model, one answer” — replacing it with a system where knowledge is distributed and coordination is the intelligence.
The results here are preliminary. The logic routing needs work. The 7B comparison remains open. But the direction is clear: a system that delegates intelligently — that knows what it doesn’t know and knows who to ask — can achieve more than one that tries to do everything alone.
The wisest model might not be the largest one. It might be the smallest one that knows its own limits.
References
- Tononi, G. & Cirelli, C. (2003). Sleep and synaptic homeostasis: a hypothesis. Brain Research Bulletin, 62(2), 143–150.
- Jacobs, R.A., Jordan, M.I., Nowlan, S.J., & Hinton, G.E. (1991). Adaptive Mixtures of Local Experts. Neural Computation, 3(1), 79–87.
- Shazeer, N., et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ICLR 2017.
- Jiang, A.Q., et al. (2024). Mixtral of Experts. arXiv:2401.04088.
- Lepikhin, D., et al. (2021). GShard: Scaling Giant Models with Conditional Computation. ICLR 2021.
- Hu, E.J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
- Kirkpatrick, J., et al. (2017). Overcoming catastrophic forgetting in neural networks (EWC). PNAS, 114(13), 3521–3526.
- Schick, T., et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. Meta AI.
- Paranjape, B., et al. (2023). ART: Automatic multi-step reasoning and tool-use for large language models. arXiv:2303.09014.
- Wu, Q., et al. (2023). AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv:2308.08155.
- Bailo, G.L. (2026). What if AI Models Learned Like Humans Do? Towards AI. https://medium.com/towards-artificial-intelligence/what-if-ai-models-learned-like-humans-do-c69c19f29d0c
- Bailo, G.L. (2026). Dream Pruning: What Happens When AI Models Sleep. Towards AI. https://medium.com/towards-artificial-intelligence/dream-pruning-what-happens-when-ai-models-sleep-3db3c404e24a
- Bailo, G.L. (2026). When AI Models Learn to Learn. Towards AI.https://medium.com/towards-artificial-intelligence/when-ai-models-learn-to-learn-continuous-knowledge-without-catastrophic-forgetting-669baf7138c7
Full code (all model variants + evaluation framework) is available as open source: github.com/dexmac221/progressive-cognitive.
A note on AI assistance: This article was developed with the help of AI tools (Claude by Anthropic). The core hypothesis, the experimental design, the Socratic architecture, and all code are my own original work. AI assisted with structuring arguments, drafting prose, and reviewing the literature. All claims have been personally validated.
The Socratic Model: Why the Wisest AI is the One That Knows When to Ask. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.