Originally shared as an X Article on May 3, 2026.
One thing has become clear as we have built our own harness management tools internally at Arize and watched external systems like Devin at Cognition start managing other Devins, managed agents at Anthropic and long-running agents from Lee Robinson at Cursor: swarm management is the next real systems problem in AI.
Not single agents or one-off tool calls. Instead, managing swarms of long-running agents is a key challenge many are circling around in the industry right now.
Most agent frameworks have crossed the first line: they can spawn subagents.
That is not swarm management.
It is the beginning of the problem.
The interesting question is what happens after the child exists. Where does it live? Who owns it? Can it be addressed? Can it be steered? Can it finish after the parent has moved on? If the process restarts, does the system know what was still running?
This is the next layer above the agent harness. A harness lets one agent call tools, read files, run commands, and keep a loop going. A delegation tool lets one agent borrow workers. A swarm manager owns a fleet.
The core feature of an agent harness is a loop over tools. A swarm manager is a loop over running harnesses, making sure they are progressing.
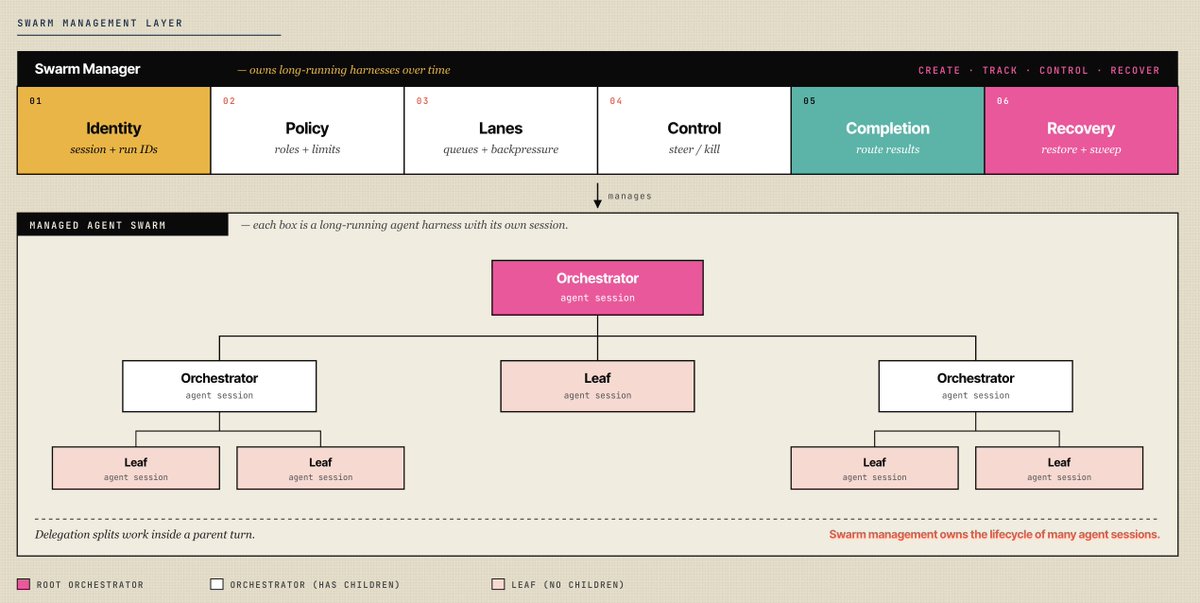
That distinction sounds academic until you look at real systems.
Hermes has a very good delegation primitive. Its delegate_task tool creates child AIAgent instances, runs them in parallel, streams progress, applies timeouts, interrupts them, and returns structured summaries back to the parent. Clean. Useful. Understandable.
But the child lives inside the parent tool call.
As we looked around the ecosystem for examples of swarm management really working, one of the absolute best examples was hiding in plain sight: OpenClaw.
OpenClaw has a solid swarm management system. Its subagents become gateway sessions. They get durable session keys, run IDs, lifecycle records, parent-child lineage, cleanup policy, and a push-based completion path back to the requester.
That is the architectural line.
Delegation asks: how does one agent split work? Swarm management asks: how does a runtime own many agents over time?
This blog will spend a lot of time highlighting what we think needs to be in swarm management driven by a lot of ideas in OpenClaw.
The agent needs durable identity
The first requirement of swarm management is identity.
If you cannot address a child, you cannot manage it. You can wait for it. You can cancel the local future. You can ask the parent to summarize what happened.
But you cannot operate a fleet.
In OpenClaw, a spawned child gets a session key:
agent:<targetAgentId>:subagent:<uuid>
That key is doing real work.
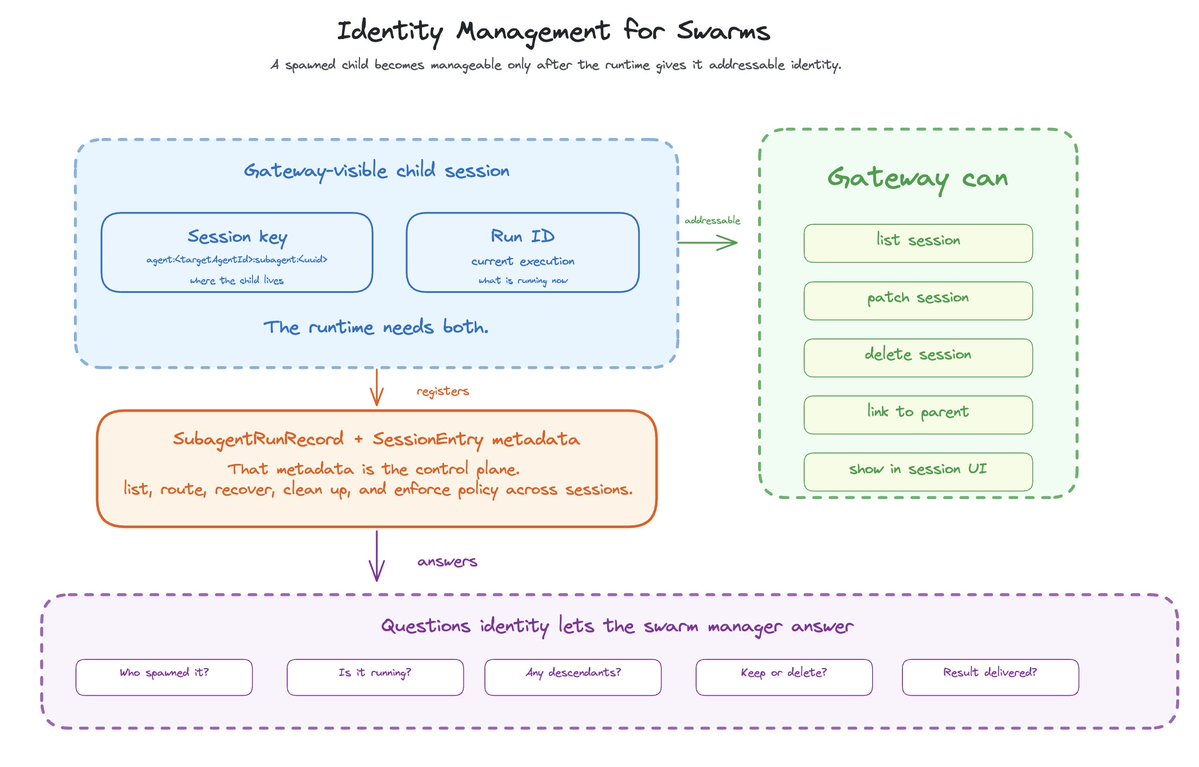
It turns the child into something the gateway can see. The child can be listed, patched, deleted, and linked back to a parent. It can show up next to normal chat sessions, cron sessions, and ACP sessions.
The child also gets a run ID. The session key names where the child lives. The run ID names the current execution.
You need both.
A swarm manager has to know the basics: child session key, run ID, requester, controller, depth, role, workspace, task label, cleanup policy, timestamps, and outcome. That metadata answers the questions the runtime cannot hand-wave away.
Who spawned this child? Is it still running? Does it have descendants? Should it be kept as a session or deleted after completion? Did the result actually get delivered?
If those answers only live inside a model’s context window, the runtime cannot manage the swarm.
Completion is routed, not returned
Most delegation systems have a simple contract:
- Parent calls a tool.
- Child runs.
- Parent blocks.
- Child returns a summary.
- Parent continues.
That is a good contract for bounded delegation.
It breaks down once the parent is not just waiting on the same call stack.
In a real swarm, the parent may be active. Or idle. Or another subagent. Or restarted. Or gone. The child may have children of its own. The result may need to be private orchestration context, not a user-facing message.
OpenClaw handles this with a push-based model. sessions_spawn returns acceptance and bookkeeping. The result arrives later through the registry and announce flow.
Roughly:
- Parent spawns a child through sessions_spawn.
- OpenClaw creates a child session.
- The child run is registered.
- The child runs in its own session.
- The registry waits for lifecycle completion.
- OpenClaw captures the child’s latest output.
- It builds an internal task_completion event.
- It routes that event back to the requester session.
The important part is the event:
{
type: "task_completion",
source: "subagent",
childSessionKey,
childSessionId,
taskLabel,
status,
result,
replyInstruction
}That is the parent-child contract: capture completion, preserve provenance, route it to the right session, and let that session decide what to do next.
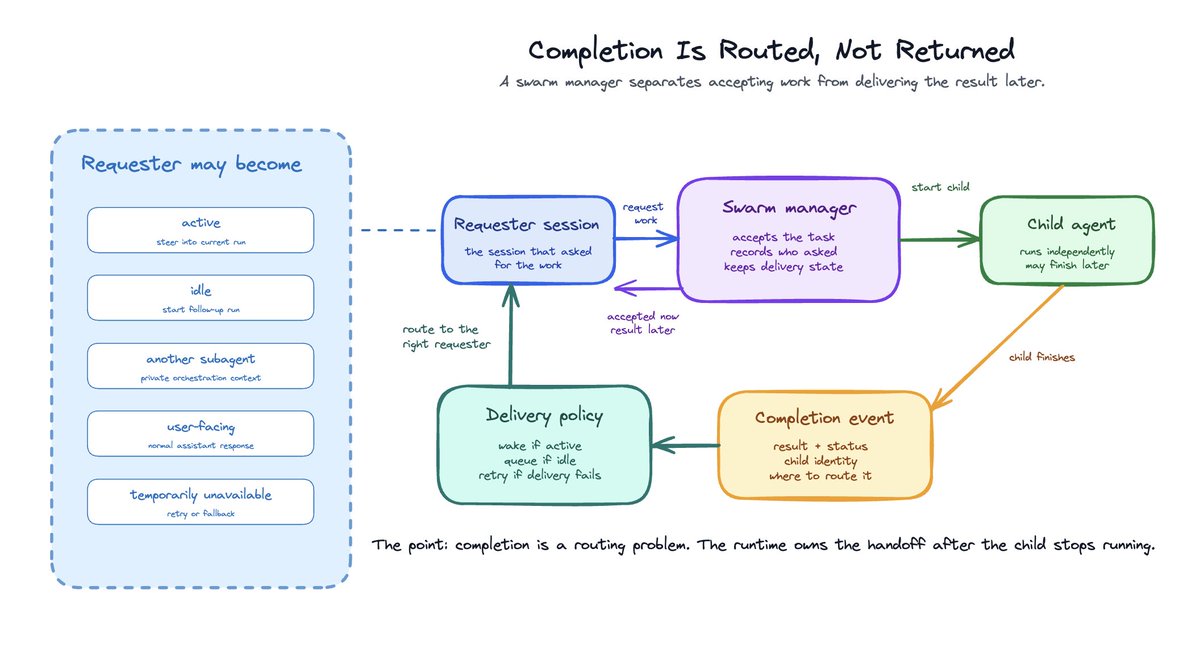
The delivery layer has policy. It can steer an active requester session, queue an announce for later, call the gateway agent method directly, deliver a user-facing channel message, retry, or fall back to direct send. Most subagent systems skip this part.
They treat completion as a return value. In a swarm manager, completion is a routing problem.
Queues matter more than prompts
Once agents can spawn agents, the runtime has to care about concurrency in a very practical way.
You need strict ordering within a session. Two messages should not collide inside the same active agent loop. You also need parallelism across sessions. Otherwise the fleet becomes a single-file line.
This is why swarm management starts to look less like an agent framework and more like runtime infrastructure.
Main agent work is one lane. Subagent work is another. Cron or background work may be another. Each lane can have its own concurrency limit, while each session still serializes its own active run.
A user sends a follow up while an agent is busy. A child finishes while a parent is still running. A child has children. A cron job completes and needs to notify a session. A steer message arrives while a model is streaming.
If all of those are just messages, the system gets messy fast.
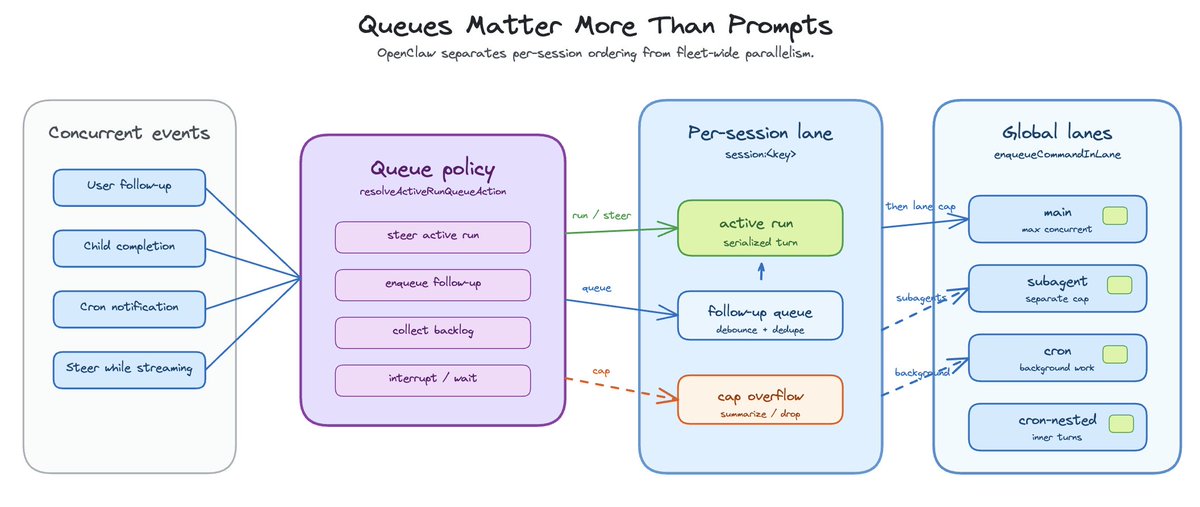
Some messages should steer the active run. Some should be queued as follow-ups. Some should interrupt. Some should be summarized or dropped when the backlog gets too large. The answer lives in queue policy, not better prompting.
Cancellation is too weak for agent swarms and fleets
The simplest systems can cancel a future. That is table stakes.
A real swarm manager needs to steer, interrupt, kill, and cascade. Steering is the interesting one.
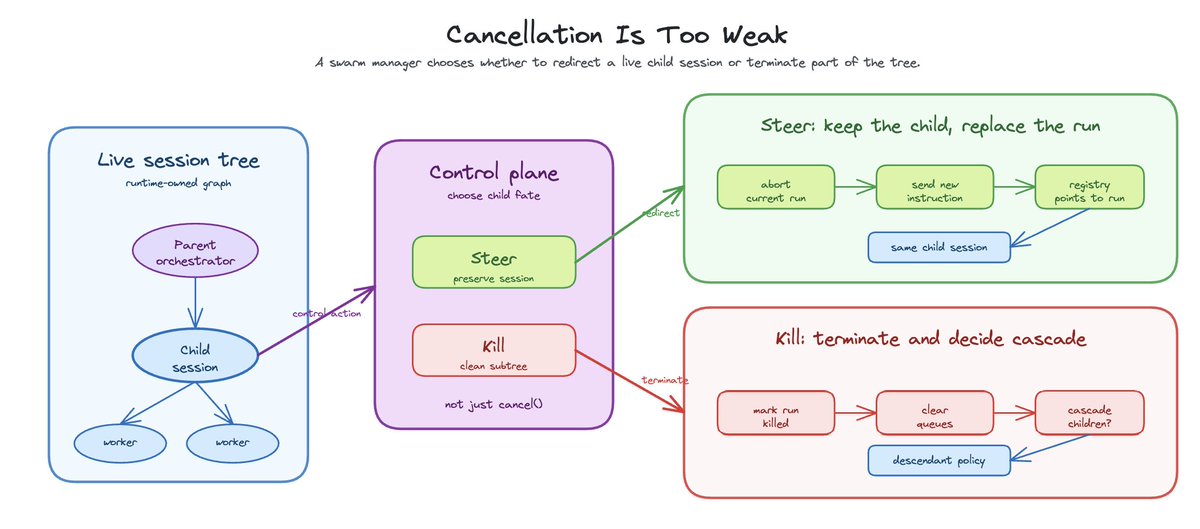
When a child is doing the wrong thing, you do not always want to kill it and lose the session. You may want to redirect it.
In OpenClaw, steering a controlled subagent is a control-plane operation. It marks the current run for steer-restart, suppresses stale completion announcement, aborts the in-flight run, clears queues, waits for abort to settle, sends a new agent message, and remaps the registry from the old run to the new one. The system is telling the child to stop what it is doing and pivot.
Kill is different. Kill should terminate the run, mark session state, suppress inappropriate completion announcements, and optionally cascade to descendants.
Cascade matters because a swarm is a tree. Killing an orchestrator while leaving its workers alive is usually wrong. Sometimes it is exactly what you want. The runtime needs to know the graph well enough to make that distinction.
This is where prompt-only coordination falls apart.
You cannot ask the model to remember every live child and manually clean up the tree. The runtime has to own the graph.
Roles are a runtime safety mechanism
Flat swarms do not scale. If every child can spawn every other child indefinitely, the system eventually becomes useless or dangerous.
The simple split is orchestrator and leaf. Orchestrators coordinate. They can spawn workers, inspect status, and synthesize results. Leaves do work. They cannot coordinate further.
This should be enforced in tools, not just suggested in prompts.
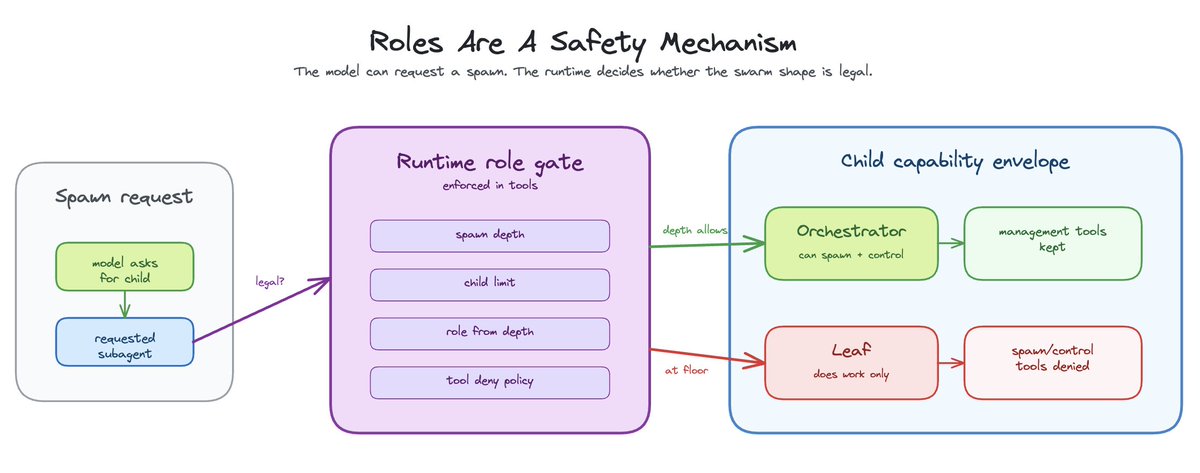
OpenClaw tracks spawn depth and resolves subagent capabilities from that depth. It stores spawnDepth, subagentRole, and subagentControlScope in the child session. Leaves lose management tools. Orchestrators keep them within configured depth and child limits.
Hermes has a similar idea in delegate_task: role=”leaf” vs role=”orchestrator”, configurable delegation.max_spawn_depth, and a kill switch for orchestrator behavior. That is the right instinct.
But in a swarm manager, the boundary belongs in the control plane. The model can request a spawn. The runtime decides whether it is legal.
The runtime should know how deep the child is, how many children the parent already owns, which tools are denied to this role, and whether the child can create more children.
No labels, no hand-holding. The system enforces the shape of the swarm.
Recovery keeps the runtime in control
A swarm manager cannot fire and forget.
If the system owns children, it needs to know when they are stuck, missing, orphaned, completed, or completed but undelivered.
OpenClaw’s subagent registry listens to lifecycle events. It uses agent.wait. It tracks active run context. It persists the registry to disk. It restores runs on startup. It has retry timers for announce delivery and grace windows for transient lifecycle errors.
It also runs a sweeper.
The sweeper is not glamorous. It is the part that makes the system real.
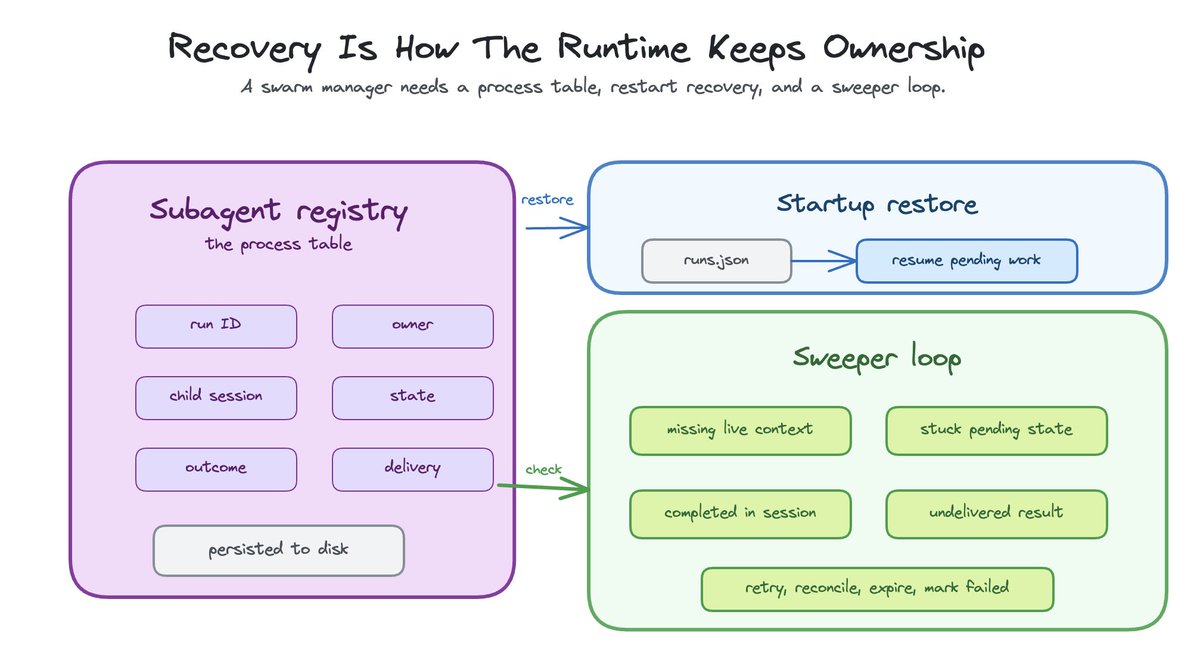
It checks active runs without live run context. It reconciles them against session state. It expires old session-mode records after cleanup. It removes or retries stuck pending lifecycle states. It marks delivery failed instead of leaving cleanup half-done forever.
This is operating-system work.
The analogy is not perfect, but it is useful: a swarm manager needs something close to a process table, because the management problem rhymes.
What is running? Who owns it? What happens when it exits? Which children should die with the parent? Which sessions should survive restart? Which outputs have not been delivered?
Without that, the system is mostly launching work and hoping.
Agent state outlives the run
Every swarm manager eventually becomes a cleanup system.
Subagents create state: transcripts, run records, browser sessions, bundle MCP runtimes, attachment directories, workspace files, delivery status, lifecycle hooks, and cost metadata.
Someone has to own that state after the model stops thinking about it.
OpenClaw lets a child be kept or deleted. That choice matters. A one-shot run can clean up transcript and runtime state. A persistent child session should remain addressable. Attachments may be retained or removed. Browser and MCP runtimes need retirement. Context engines need to know whether a subagent ended or was deleted.
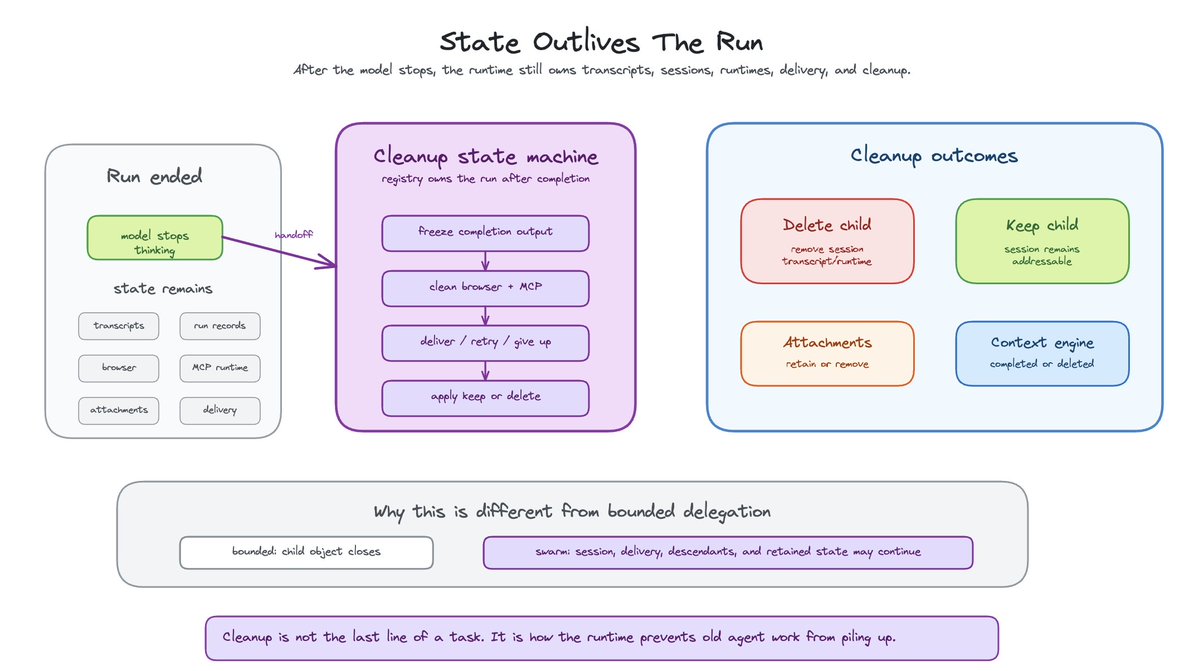
This is another place where delegation and swarm management diverge.
In bounded delegation, cleanup can be local. The child object closes. The thread exits. The parent gets JSON.
In swarm management, cleanup is distributed. The child may be a session. The run may be done but delivery not complete. The session may be kept but attachments removed. The parent may need one more wake-up after descendants settle.
Cleanup is a state machine.
That sounds heavy because it is.
But long-running multi-agent systems accumulate state. Pretending otherwise just moves the complexity into bugs.
Swarm management is the layer above the agent
OpenClaw is interesting because it exposes the swarm manager layer in code.
There is no magical SwarmManager object that makes everything elegant. The swarm emerges from ordinary runtime machinery:
- session keys
- lanes
- run IDs
- registry records
- lifecycle events
- internal completion events
- queue policy
- delivery routing
- cleanup decisions
- recovery sweeps
That is probably what real swarm management looks like: a set of boring control-plane primitives that make many agents survivable.
Hermes shows what good delegation looks like. Spawn workers, stream progress, return summaries, synthesize.
OpenClaw shows what happens when delegation becomes session infrastructure.
The next generation of agent systems will not just ask whether an agent can call tools. That was the harness question.
The next question is where agents live, who owns them, how they report back, how they are stopped, and what survives after restart.
That is the layer that turns “a single agent harness” into a fleet of well coordinated “agents” that can tackle a wide range of tasks.
The post Swarm management in agent harnesses: owning long-running agents appeared first on Arize AI.