Designing Robust AI Agent Tooling: Handling Semantic Variations Between User Language and Backend Systems
Modern AI agents often sit between human language and strict backend systems. While humans naturally use flexible, ambiguous language, backend systems — especially databases and APIs — require precise, canonical values.
This is a very common (and important) problem in agent + tool design 👍
You’re essentially dealing with semantic normalization between natural language and strict backend enums.
Consider an AI agent designed to fetch Flights or Hotels for a given location.
Example Interaction
User → Agent: "I want to fetch hotels for Seattle"
Agent → LLM: Interprets user intent
LLM → Agent: Calls fetchDetails(location=Seattle, lob=hotels)
Agent → DB: Query where lob = "hotels"
DB → Agent: No results
Your DB is strict:
lob = "Hotel" | "Flight"
User language is flexible:
hotel, hotels, stay, stays, accommodation, lodging
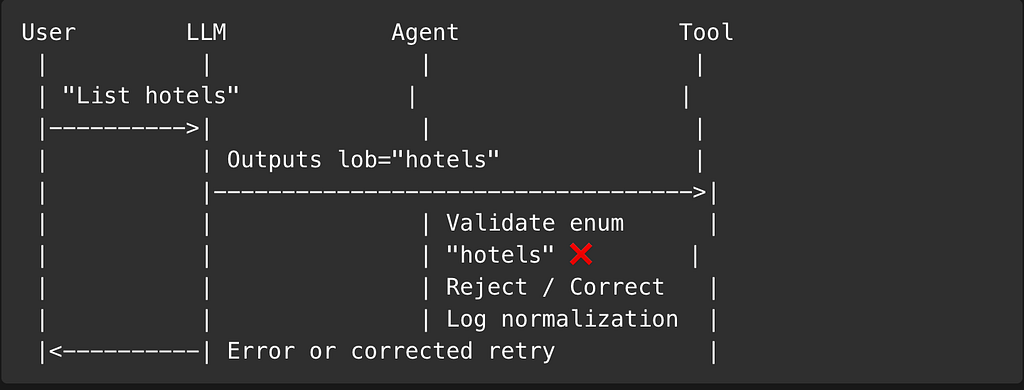
Root Cause
- The database stores lob = "Hotel"
- The user uses “hotels” (plural)
- The LLM passes the user’s linguistic variation directly
- Result: Zero results despite valid data
This is a very common (and important) problem in agent + tool design 👍
You’re essentially dealing with semantic normalization between natural language and strict backend enums.
Core Design Principle
Natural language should never directly control strict backend systems.Instead, AI systems must translate human intent into canonical, system-safe representations before executing business logic.
Design
User → Agent → Normalize intent → Tool call (strict enum) → DB
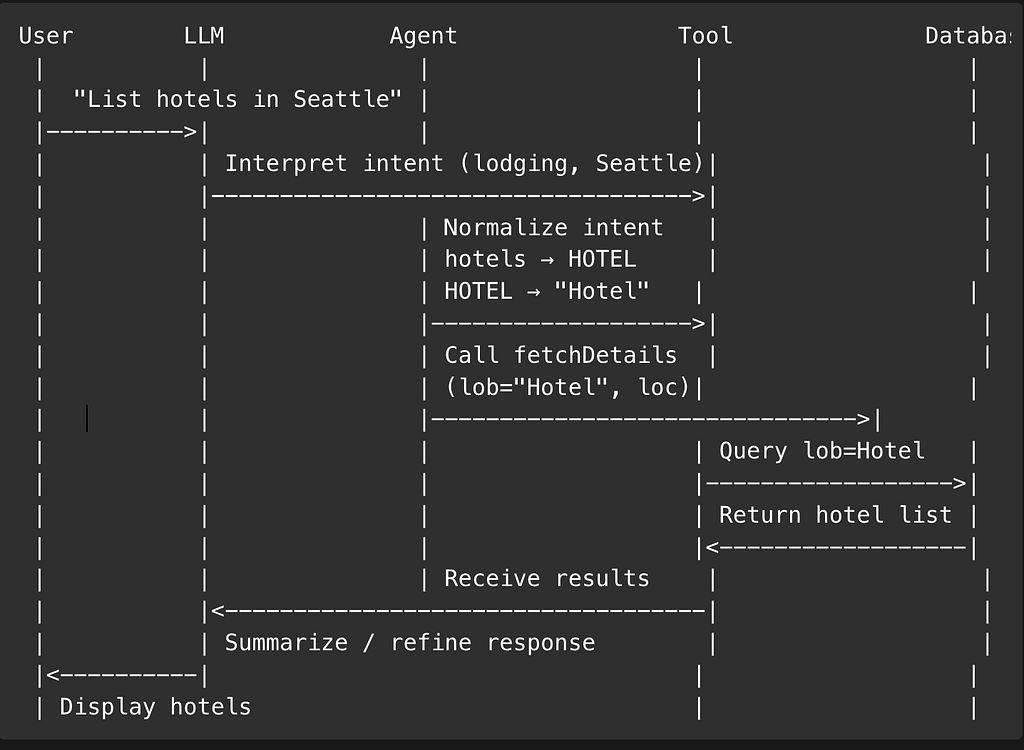
Option 1: LOB Normalization Layer (Most Robust)
Create a normalization step inside the Agent, before calling tools.
Step 1: Define canonical enums
{
"LOB_CANONICAL": {
"HOTEL": "Hotel",
"FLIGHT": "Flight"
}
}Step 2: Define accepted aliases
{
"HOTEL": ["hotel", "hotels", "stay", "stays", "accommodation", "lodging"],
"FLIGHT": ["flight", "flights", "air", "airline", "plane", "airfare"]
}Step 3: Normalize user intent
String normalizeLob(String userInput) {
String input = userInput.toLowerCase();
if (HOTEL_ALIASES.stream().anyMatch(input::contains)) {
return "Hotel";
}
if (FLIGHT_ALIASES.stream().anyMatch(input::contains)) {
return "Flight";
}
throw new IllegalArgumentException("Unsupported LOB");
}Flow becomes:
User → Agent
Agent → normalizeLob("hotels") → "Hotel"
Agent → tool(lob="Hotel", location="Seattle")
✅ DB-safe
✅ Deterministic
✅ LLM hallucinations don’t break you
Option 2: Force the LLM to Output Only Canonical Values (Very Common)
You can constrain the LLM using the tool schema itself.
Reference — https://community.openai.com/t/tool-calls-does-the-schema-matter/859354
Tool schema example
{
"name": "fetchDetails",
"description": "Fetch hotels or flights for a location",
"parameters": {
"type": "object",
"properties": {
"location": { "type": "string" },
"lob": {
"type": "string",
"enum": ["Hotel", "Flight"]
}
},
"required": ["location", "lob"]
}
}System prompt (important)
When calling fetchDetails:
- Use ONLY the enum values provided.
- Map plural or synonym user intent to the closest enum.
- "hotels", "stay", "accommodation" → "Hotel"
- "flights", "airfare" → "Flight"
Result
Even if user says:
"List hotels in Seattle"
LLM will produce:
{
"lob": "Hotel",
"location": "Seattle"
}⚠️ Still recommended to validate server-side.
Option 3: Defensive DB Query (Fallback Only)
You can make DB queries more tolerant, but this should be last-line defense, not primary logic.
Example
SELECT * FROM listings
WHERE LOWER(lob) IN ('hotel', 'hotels')
or
WHERE LOWER(lob) LIKE 'hotel%'
❌ Leaks business logic into DB
❌ Hard to maintain
❌ Doesn’t scale for more LOBs
Option 4: LLM Prompt as a Translator, Not an Executor
Use the LLM for understanding, not execution authority.
System Prompt Example
You must map user language to canonical business enums.
Do not pass plural, synonym, or free-text values to tools.
Hotels, stays, accommodations → Hotel
Flights, airfare → Flight
This keeps the LLM focused on semantic interpretation, not business rules.
Final Thoughts
As AI agents become a core interaction layer between users and systems, the architectural decisions made today will determine whether these agents remain reliable production systems or devolve into fragile, prompt-driven integrations.
This document emphasizes a critical principle:
AI systems must be linguistically flexible at the boundaries and mechanically strict at the core.
Natural language is inherently ambiguous, evolving, and probabilistic. Backend systems — databases, APIs, and services — are not. Attempting to blur this boundary by allowing free-form language to propagate directly into execution paths introduces hidden failure modes, silent data issues, and long-term maintenance risk.
The architecture proposed in this Document deliberately separates concerns:
- LLMs are used for understanding intent, not enforcing business rules
- Agents act as guardians of system correctness
- Tools and databases operate only on canonical, validated inputs
By adopting canonical domain models, semantic normalization layers, schema-enforced tool contracts, and layered validation, teams can safely scale AI capabilities without sacrificing determinism, observability, or trust.
Importantly, this approach does not slow down innovation — it enables it. Teams can:
- Add new lines of business without rewriting prompts
- Improve language understanding independently of backend systems
- Audit, debug, and evolve AI behavior with confidence
This Document is not just a solution to pluralization or synonym handling. It establishes a foundational pattern for building production-grade AI agents that are extensible, explainable, and safe by design.
As AI continues to move from experimentation to infrastructure, architectures like this will be essential to ensure that intelligence enhances systems — rather than destabilizing them.
Designing Robust AI Agent Tooling: Handling Semantic Variations Between User Language and Backend… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.