Quantization asks how much of a neural network you can throw away before it breaks. Education asks the same question about the human mind.

I was talking about TurboQuant to a tech colleague at an AI company last week. Quantization, model compression, how you squeeze a 70-billion-parameter model into something that runs on hardware a fraction of the size. Standard conversation for people who build them.
A sales colleague overheard us and walked over.
“Why does that matter? Isn’t data just data? It’s not like there’s a storage problem.”
She was not being dismissive. She was genuinely asking. And the question stopped me, because she was right about something she did not realize she was right about.
Data is just data. That part she nailed. The part she missed is that the value was never in the data. The value is in knowing which data to throw away.
That insight connects AI model compression to something much older than neural networks.
What compression actually does
Quantization takes a neural network and asks a single question: how much of this can I remove before the output breaks?
A 70-billion-parameter model stores billions of floating-point numbers at high precision. Each parameter is a weight learned during training, a tiny piece of the pattern the model uses to produce output. Quantization reduces that precision. FP16 to INT8. INT8 to INT4. Each step throws away information. The question is whether the information it throws away matters.
(Most of it does not.)
This is counterintuitive. If I told you I could remove 75% of a surgeon’s training and they would still perform at the same level, you would call me insane. But neural networks are not surgeons. They are massively overparameterized by design. They store far more information than they need to generalize. The redundancy is a byproduct of training, not a feature of competence.
The results bear this out. A well-quantized 32B model running at INT4 will outperform a poorly prompted 70B model running at full precision on tasks that require focused context. We proved this in production. Our document extraction pipeline used Qwen3 32B VL to beat Gemini 3 Pro, a frontier vision-language model many times its size. Under 40% accuracy from the frontier model. Over 90% from the smaller one. Not because the smaller model was smarter. Because the architecture gave it exactly the right context at exactly the right moment.
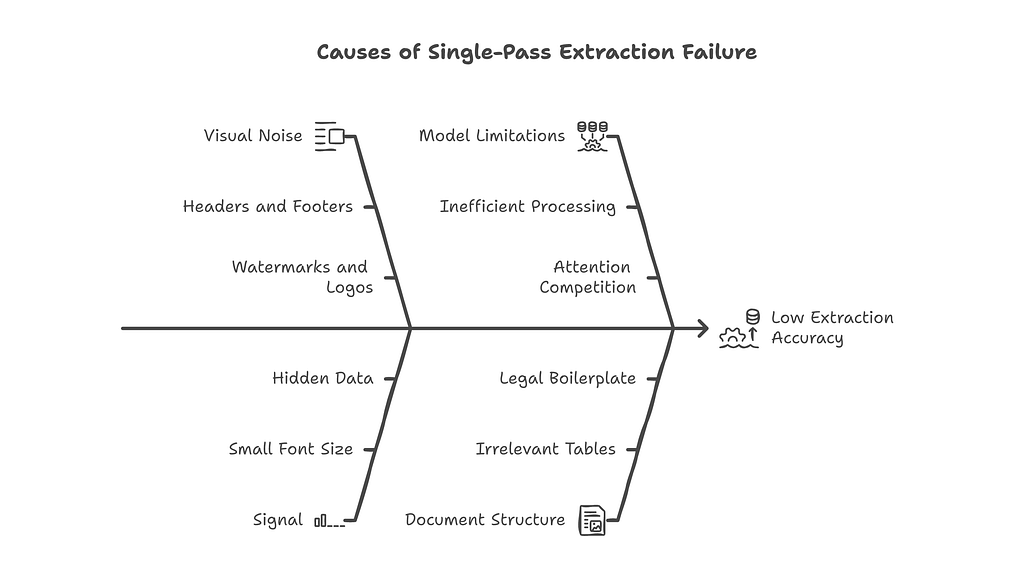
The frontier model drowned in 15,000 tokens of visual noise — headers, footers, watermarks, logos, decorative borders. The compressed model got exactly the signal it needed and nothing else. The graph did the work. The model executed.
Compression does not make a model dumber. It makes a model focused. It removes the noise that full precision carries and keeps the patterns that generalize.
That process is not unique to neural networks. Humans have been doing it for centuries. We just call it something different.
Compression is what education does
What quantization does to a model is what education does to a mind.
A medical degree compresses centuries of clinical knowledge into six years. It does not teach every case. It teaches the patterns that generalize. Anatomy. Physiology. Pharmacology. Differential diagnosis. The frameworks that let a doctor reason about a patient they have never seen before, presenting symptoms that were not in any textbook.
The student who memorizes every fact from every lecture has not been educated. The student who can walk into an emergency room and diagnose a condition they have never encountered, using the reasoning frameworks they internalized, that student has been compressed correctly.
A good university does not transfer all knowledge. It transfers the minimum representation that preserves meaning. It strips away irrelevant details, outdated methods, edge cases that do not generalize. It keeps the structure that lets someone reason about situations that were not in the curriculum.
That is exactly what quantization does.

A 70B model at full precision is the student who memorized everything. Every lecture. Every footnote. Every edge case. It can recall any of it on demand. But recall is not understanding, and carrying all that weight slows it down when speed matters.
A well-quantized 32B model is the student who understood the material. Smaller. Faster. And in the right context, more accurate. It is not wasting attention on information that does not help with the task in front of it.
George Cybenko published the Universal Approximation Theorem in 1989. The paper proved that a neural network with a single hidden layer and sufficient width can approximate any continuous function to arbitrary accuracy. That theorem describes what neural networks can learn. Quantization asks: how much of that network can you remove before the approximation breaks? How few parameters can you keep while still preserving the function?
Education asks the same question about a human mind. How few years of training can you provide while still producing someone who can generalize? How much of the curriculum can you cut before the graduate breaks?
The answer in both cases is: more than you think. The redundancy is enormous. The signal-to-noise ratio of a full-precision model and a four-year degree are both shockingly low. Most of what gets stored, in weights or in memory, is noise. The art of compression is knowing which part is not.
Her question was accidentally the right question. Data is just data. The value is in knowing which data to throw away. That is what compression does. That is what education does. And that is what most people never learn about AI, even the ones selling it.
The widest gap in technology history
She sells AI products. She did not know what quantization is. I do not mean she could not explain the math. I mean she did not know the word. And she closes deals every month.
That is not a story about one person. That is a story about an entire industry.
90% of developers now use AI tools daily, according to Google’s 2025 DORA report. 75% of knowledge workers use AI regularly. Fewer than 28% of any group — technical or not — can explain how the technology actually works.
We have built the first technology in history that makes people more capable while making them less literate about the capability.
Every previous technology wave required understanding to unlock value. You had to learn to drive to use a car. You had to learn to type to use a computer. You had to learn to code to build software. Each wave had a literacy requirement. No understanding, no access.
AI broke that pattern. You can use ChatGPT to draft a legal contract without understanding language models, probability distributions, or token prediction. You can use Copilot to write production code without understanding how the model was trained or what its failure modes are. You can use Midjourney to create marketing assets without understanding diffusion, latent spaces, or CLIP embeddings.
The value is immediate. The understanding is optional.
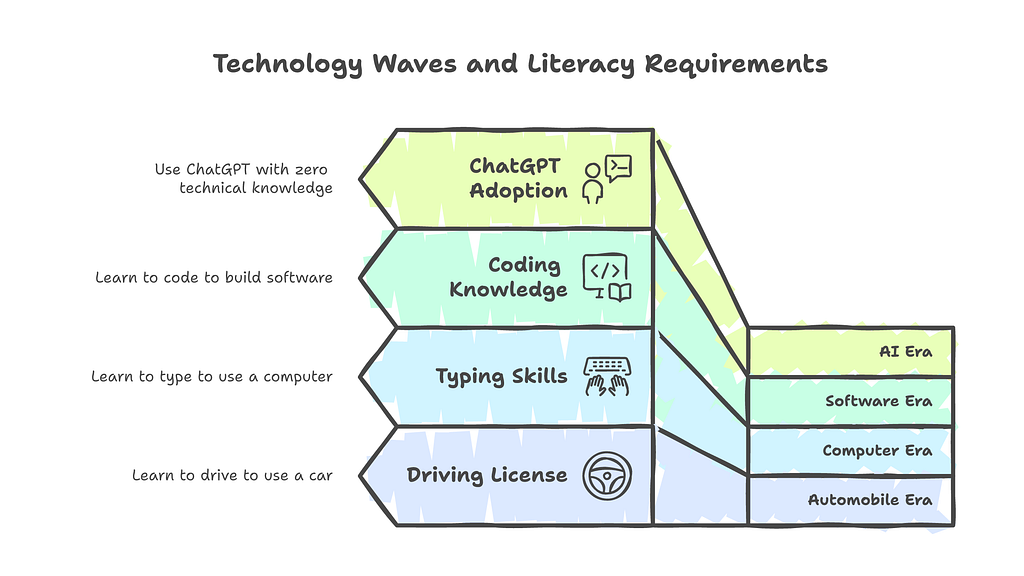
That has never happened before at this scale.
The uncomfortable part: this is what good abstraction looks like. A well-designed system hides its complexity. The iPhone does not require you to understand ARM architecture. Electricity does not require you to understand transformers. Google Maps does not require you to understand Dijkstra’s algorithm. Good tools disappear. You use them without thinking about how they work.
So why does the AI literacy gap matter?
It matters because abstraction works when the system is stable and the user’s decisions do not depend on understanding the internals. You do not need to understand combustion engines to drive safely. The car handles it. But you do need to understand combustion engines if you are a mechanic. You do need to understand them if you are writing emissions regulations. You do need to understand them if you are deciding which engine to put in a fleet of delivery trucks.
A driver who does not understand engines is fine. A mechanic who does not understand engines is dangerous. A regulator who does not understand engines writes bad emissions laws.
The AI industry is full of mechanics who do not understand the engine.
She sells AI products to enterprise clients. She recommends one model over another. She positions capabilities against competitors. She influences purchasing decisions that will shape how organizations use AI for years. And she does not know what quantization is — not the math, not the concept, not even the word.
That is not her failure. That is the industry’s failure. The AI industry built tools that non-technical people can use without understanding. Then it hired non-technical people to sell those tools without teaching them what they are selling. The abstraction that made the products accessible also made the salesforce ignorant. And nobody noticed because the deals kept closing.
We count adoption. We do not count comprehension.
The AI industry celebrates adoption metrics. How many developers use Copilot. How many enterprises deployed agents. How many knowledge workers prompt ChatGPT daily. Every earnings call, every industry report, every keynote — the numbers go up and everyone applauds.
Nobody tracks comprehension metrics.
We count how many people use the tool. We do not count how many people understand what the tool is doing to their work. We count how many models shipped. We do not count how many buyers can articulate why one model is different from another. We count how many AI products are in market. We do not count how many salespeople can explain what they sell.
That gap has a cost. We just have not received the invoice yet.

I see this pattern in my own work. I build multi-agent AI systems for enterprise clients. Financial institutions. Government-linked companies. Consulting firms. When I explain what quantization enables — running models on-premise instead of sending data to a cloud API, reducing inference costs by 60–80%, deploying on hardware the client already owns — the technical teams get it instantly. The business teams hear “cheaper and faster” and stop listening.
“Cheaper and faster” is enough to close a deal. It is not enough to make a good decision. The client who chose a quantized open-weight model because it was cheaper, without understanding why it was cheaper, will not know what to do when accuracy degrades on a new document type. They will not know that the model lost some capability during compression and needs a different prompting strategy. They will blame the model. Or blame us. Or abandon the approach. Because nobody gave them the five-minute explanation that would have set the right expectations.
The pharmaceutical industry figured this out decades ago. Sales reps undergo pharmacology training — not at a researcher’s level, but enough to know what they are selling, how it works, what the side effects are, and when it should not be used. Some cities like Chicago require it by law. Financial advisors must pass Series 65 or Series 66 licensing exams before they can give investment advice. Insurance agents learn actuarial basics. In regulated industries, there is a minimum comprehension bar for the people who sell the product to the people who use it.
AI has no equivalent. You can sell a system that scores a billion job applicants without understanding how scoring works. You can sell a model that runs on a phone without knowing why running on a phone is harder than running in a cloud. You can sell an agent framework without understanding what “bounded autonomy” means or why it matters.
The product complexity went up. The sales knowledge bar did not.
The knowledge is not moving
The value is not in having all the information. It is in keeping the right information and making it portable.
The AI industry compressed the user experience brilliantly. Anyone can use these tools. A lawyer drafts contracts with GPT. A marketer generates campaigns with Claude. A developer writes code with Copilot. The tools are portable. They travel from expert hands to anyone’s hands. That is genuine progress.
But the AI industry did not compress the understanding at all. The knowledge of how these systems work, why they fail, what their limitations are, when to trust them and when not to. That knowledge stayed exactly where it started. In the heads of researchers and engineers. It did not get packaged. It did not get simplified. It did not get made portable.
We made the tools portable. We did not make the knowledge portable.
Education solves that problem. That is its entire purpose — take complex knowledge, strip away the noise, find the minimum representation that preserves meaning, and transfer it to someone who did not have it before. Make the knowledge portable.
Compression solves it too. Not metaphorically. Literally. A quantized model that runs on a laptop instead of a data center is portable knowledge. A skill file that encodes domain expertise into a format an AI agent can execute is portable knowledge. A well-structured prompt that captures decades of actuarial judgment in a repeatable workflow is portable knowledge.
The tools exist. The methods exist. What does not exist is the will to use them on the hardest problem: explaining AI to the people who depend on it.
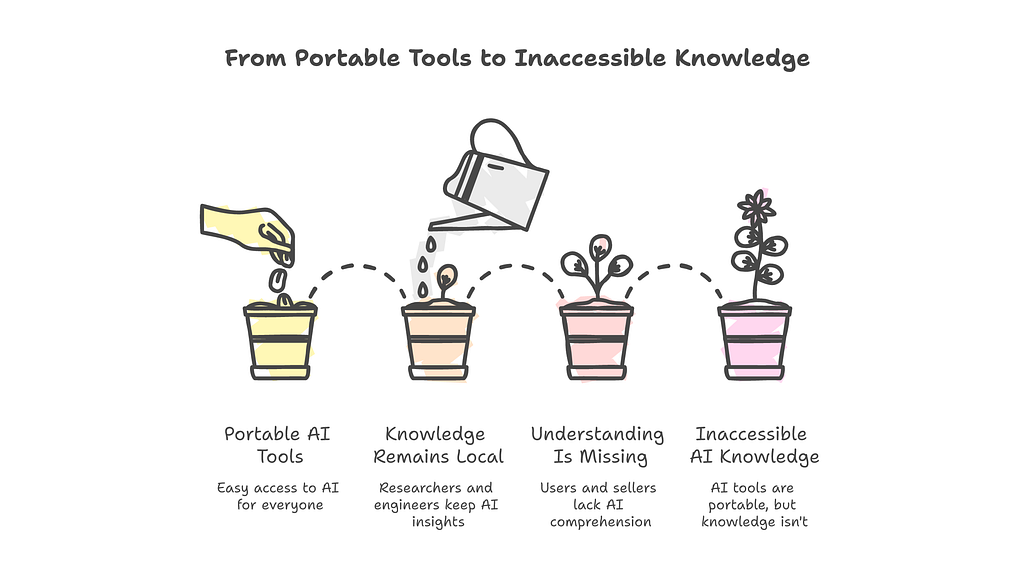
She asked why compression matters. The answer is that compression is how knowledge becomes portable — in machines and in minds. And right now, the knowledge is not moving.
Originally published at https://www.weeai.dev on March 29, 2026.
75% of What a Neural Network Learns is noise. So is 75% of What You Learned in School. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.